 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Slow Transfer Predictions: Generative Methods Compared
Dec 16, 2025Monitoring data transfer performance is a crucial task in scientific computing networks. By predicting performance early in the communication phase, potentially sluggish transfers can be identified and selectively monitored, optimizing network usage and overall performance. A key bottleneck to improving the predictive power of machine learning (ML) models in this context is the issue of class imbalance. This project focuses on addressing the class imbalance problem to enhance the accuracy of performance predictions. In this study, we analyze and compare various augmentation strategies, including traditional oversampling methods and generative techniques. Additionally, we adjust the class imbalance ratios in training datasets to evaluate their impact on model performance. While augmentation may improve performance, as the imbalance ratio increases, the performance does not significantly improve. We conclude that even the most advanced technique, such as CTGAN, does not significantly improve over simple stratified sampling.
Effectiveness and predictability of in-network storage cache for scientific workflows
Jul 20, 2023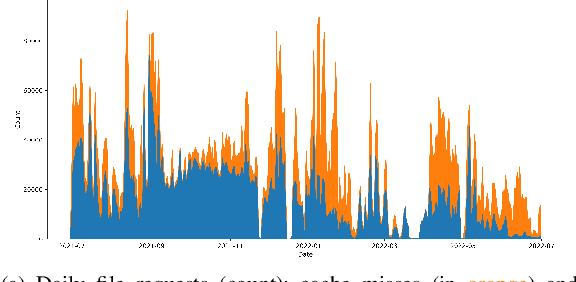
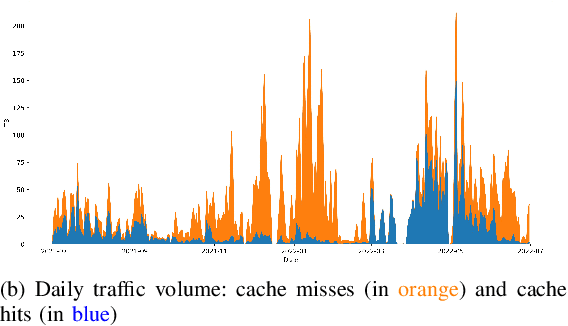
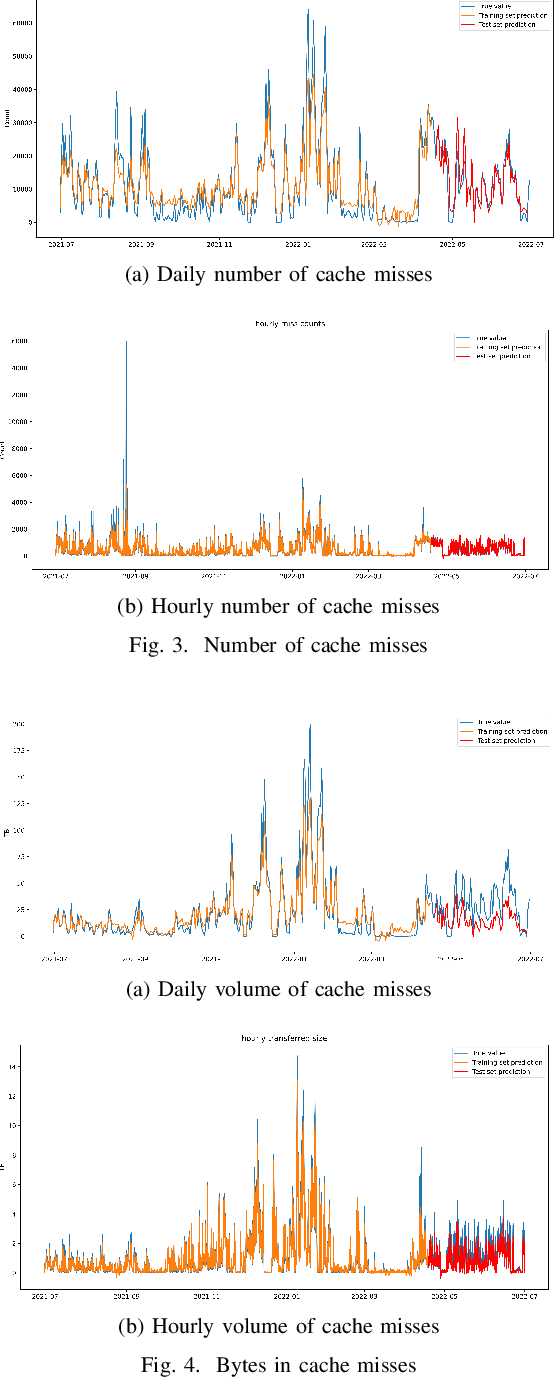
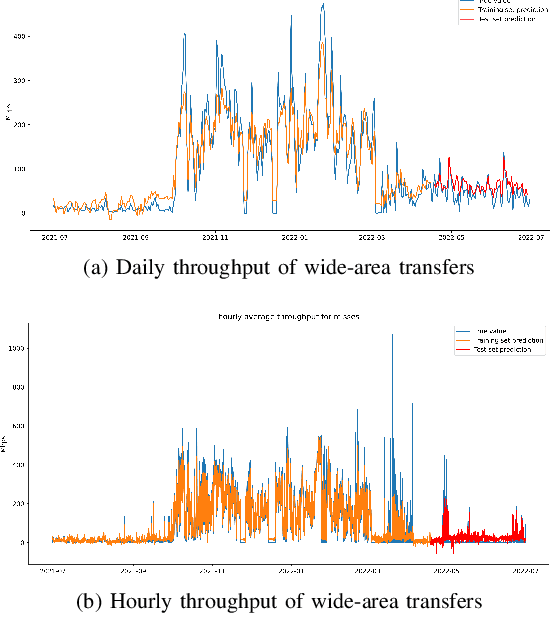
Large scientific collaborations often have multiple scientists accessing the same set of files while doing different analyses, which create repeated accesses to the large amounts of shared data located far away. These data accesses have long latency due to distance and occupy the limited bandwidth available over the wide-area network. To reduce the wide-area network traffic and the data access latency, regional data storage caches have been installed as a new networking service. To study the effectiveness of such a cache system in scientific applications, we examine the Southern California Petabyte Scale Cache for a high-energy physics experiment. By examining about 3TB of operational logs, we show that this cache removed 67.6% of file requests from the wide-area network and reduced the traffic volume on wide-area network by 12.3TB (or 35.4%) an average day. The reduction in the traffic volume (35.4%) is less than the reduction in file counts (67.6%) because the larger files are less likely to be reused. Due to this difference in data access patterns, the cache system has implemented a policy to avoid evicting smaller files when processing larger files. We also build a machine learning model to study the predictability of the cache behavior. Tests show that this model is able to accurately predict the cache accesses, cache misses, and network throughput, making the model useful for future studies on resource provisioning and planning.
Extract Dynamic Information To Improve Time Series Modeling: a Case Study with Scientific Workflow
May 19, 2022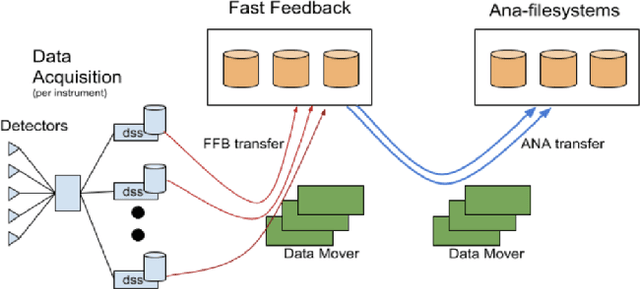
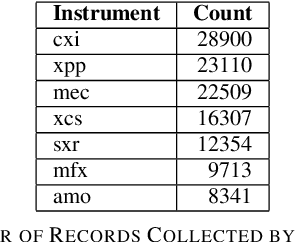
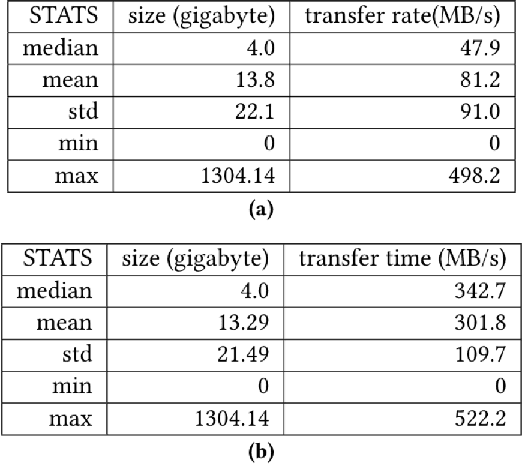

In modeling time series data, we often need to augment the existing data records to increase the modeling accuracy. In this work, we describe a number of techniques to extract dynamic information about the current state of a large scientific workflow, which could be generalized to other types of applications. The specific task to be modeled is the time needed for transferring a file from an experimental facility to a data center. The key idea of our approach is to find recent past data transfer events that match the current event in some ways. Tests showed that we could identify recent events matching some recorded properties and reduce the prediction error by about 12% compared to the similar models with only static features. We additionally explored an application specific technique to extract information about the data production process, and was able to reduce the average prediction error by 44%.
Access Trends of In-network Cache for Scientific Data
May 11, 2022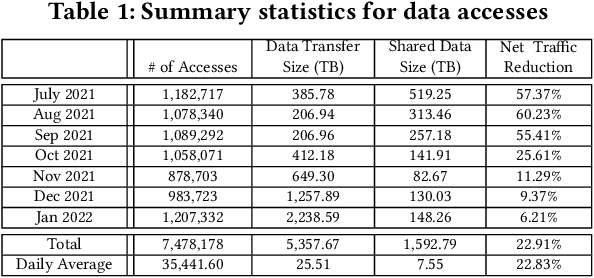
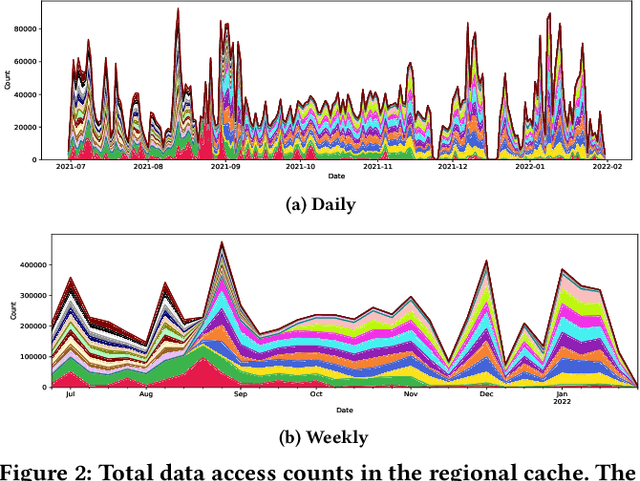
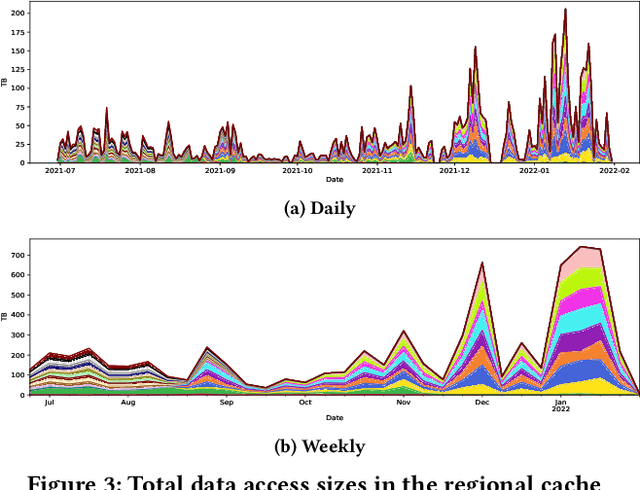
Scientific collaborations are increasingly relying on large volumes of data for their work and many of them employ tiered systems to replicate the data to their worldwide user communities. Each user in the community often selects a different subset of data for their analysis tasks; however, members of a research group often are working on related research topics that require similar data objects. Thus, there is a significant amount of data sharing possible. In this work, we study the access traces of a federated storage cache known as the Southern California Petabyte Scale Cache. By studying the access patterns and potential for network traffic reduction by this caching system, we aim to explore the predictability of the cache uses and the potential for a more general in-network data caching. Our study shows that this distributed storage cache is able to reduce the network traffic volume by a factor of 2.35 during a part of the study period. We further show that machine learning models could predict cache utilization with an accuracy of 0.88. This demonstrates that such cache usage is predictable, which could be useful for managing complex networking resources such as in-network caching.
Improving Botnet Detection with Recurrent Neural Network and Transfer Learning
Apr 26, 2021
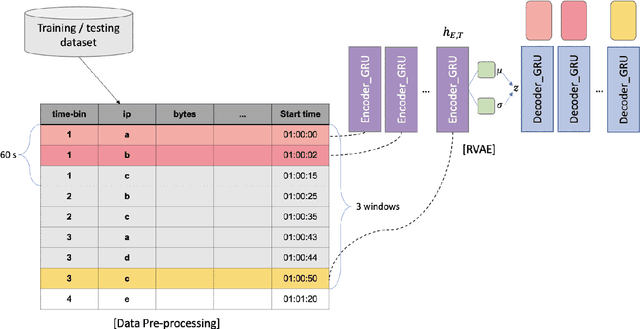
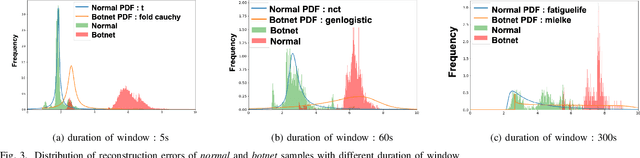
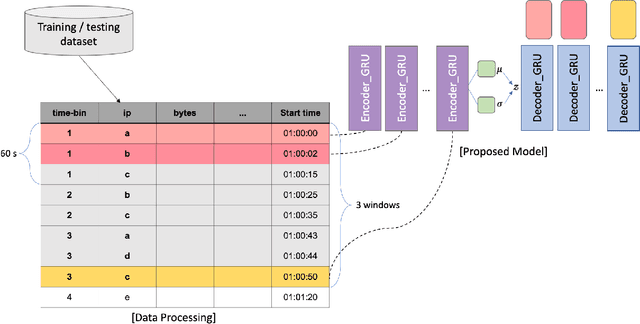
Botnet detection is a critical step in stopping the spread of botnets and preventing malicious activities. However, reliable detection is still a challenging task, due to a wide variety of botnets involving ever-increasing types of devices and attack vectors. Recent approaches employing machine learning (ML) showed improved performance than earlier ones, but these ML- based approaches still have significant limitations. For example, most ML approaches can not incorporate sequential pattern analysis techniques key to detect some classes of botnets. Another common shortcoming of ML-based approaches is the need to retrain neural networks in order to detect the evolving botnets; however, the training process is time-consuming and requires significant efforts to label the training data. For fast-evolving botnets, it might take too long to create sufficient training samples before the botnets have changed again. To address these challenges, we propose a novel botnet detection method, built upon Recurrent Variational Autoencoder (RVAE) that effectively captures sequential characteristics of botnet activities. In the experiment, this semi-supervised learning method achieves better detection accuracy than similar learning methods, especially on hard to detect classes. Additionally, we devise a transfer learning framework to learn from a well-curated source data set and transfer the knowledge to a target problem domain not seen before. Tests show that the true-positive rate (TPR) with transfer learning is higher than the RVAE semi-supervised learning method trained using the target data set (91.8% vs. 68.3%).
Botnet Detection Using Recurrent Variational Autoencoder
Apr 01, 2020
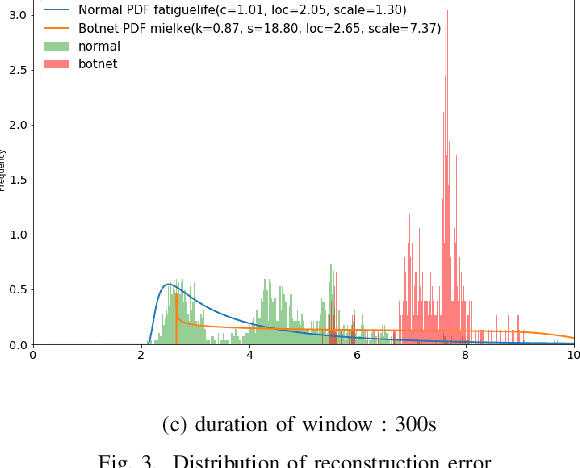

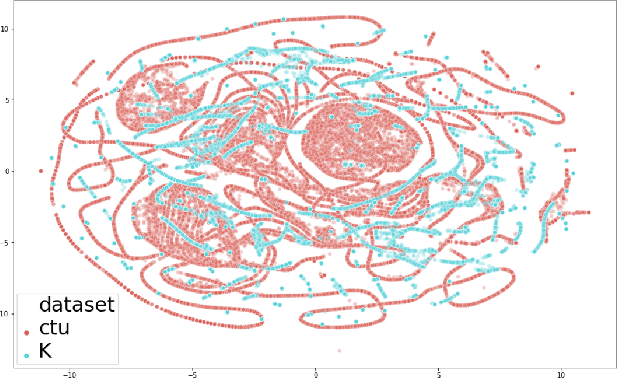
Botnets are increasingly used by malicious actors, creating increasing threat to a large number of internet users. To address this growing danger, we propose to study methods to detect botnets, especially those that are hard to capture with the commonly used methods, such as the signature based ones and the existing anomaly-based ones. More specifically, we propose a novel machine learning based method, named Recurrent Variational Autoencoder (RVAE), for detecting botnets through sequential characteristics of network traffic flow data including attacks by botnets. We validate robustness of our method with the CTU-13 dataset, where we have chosen the testing dataset to have different types of botnets than those of training dataset. Tests show that RVAE is able to detect botnets with the same accuracy as the best known results published in literature. In addition, we propose an approach to assign anomaly score based on probability distributions, which allows us to detect botnets in streaming mode as the new networking statistics becomes available. This on-line detection capability would enable real-time detection of unknown botnets.
An Ensemble Approach toward Automated Variable Selection for Network Anomaly Detection
Oct 28, 2019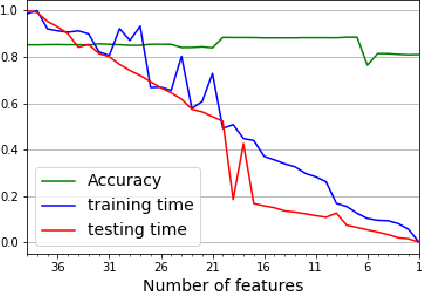
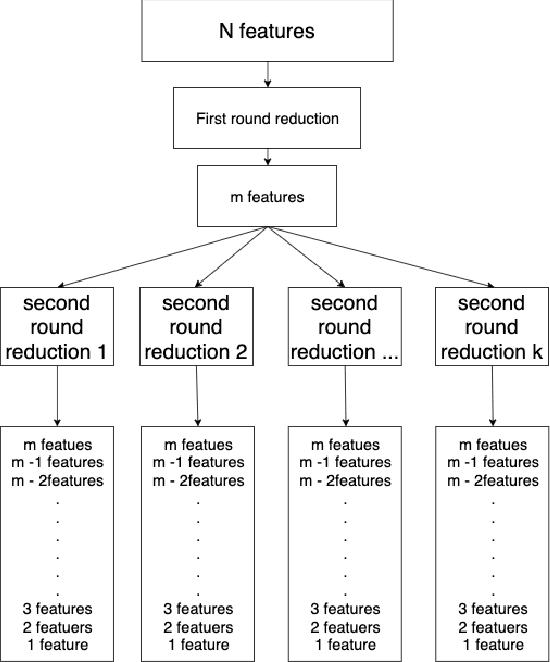
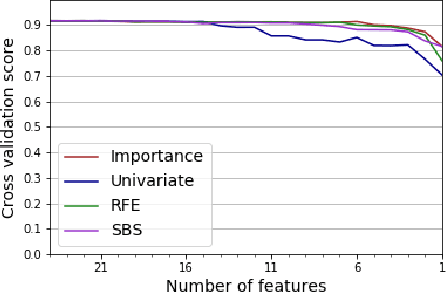
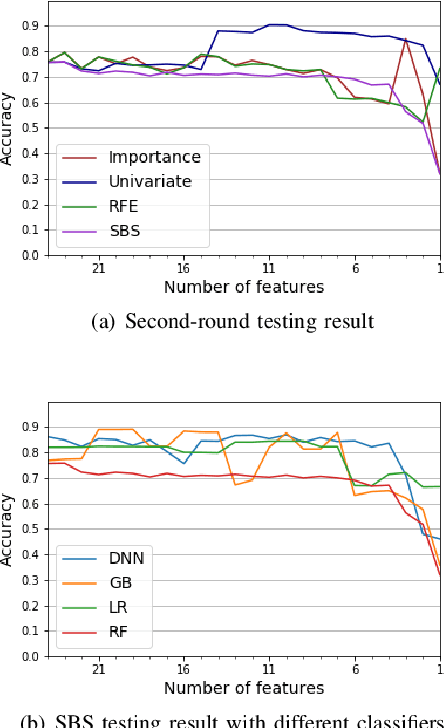
While variable selection is essential to optimize the learning complexity by prioritizing features, automating the selection process is preferred since it requires laborious efforts with intensive analysis otherwise. However, it is not an easy task to enable the automation due to several reasons. First, selection techniques often need a condition to terminate the reduction process, for example, by using a threshold or the number of features to stop, and searching an adequate stopping condition is highly challenging. Second, it is uncertain that the reduced variable set would work well; our preliminary experimental result shows that well-known selection techniques produce different sets of variables as a result of reduction (even with the same termination condition), and it is hard to estimate which of them would work the best in future testing. In this paper, we demonstrate the potential power of our approach to the automation of selection process that incorporates well-known selection methods identifying important variables. Our experimental results with two public network traffic data (UNSW-NB15 and IDS2017) show that our proposed method identifies a small number of core variables, with which it is possible to approximate the performance to the one with the entire variables.