 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Elastic Training for Sparse Deep Learning on Heterogeneous Multi-GPU Servers
Oct 13, 2021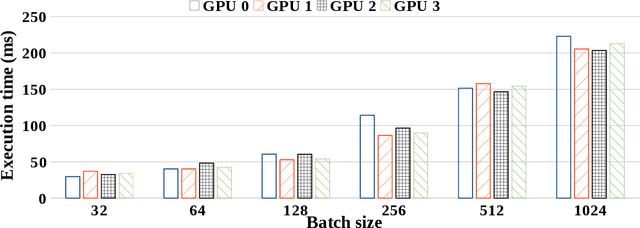

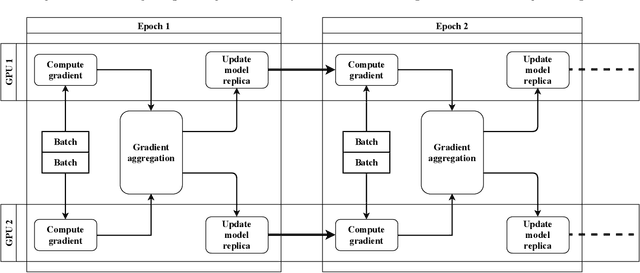
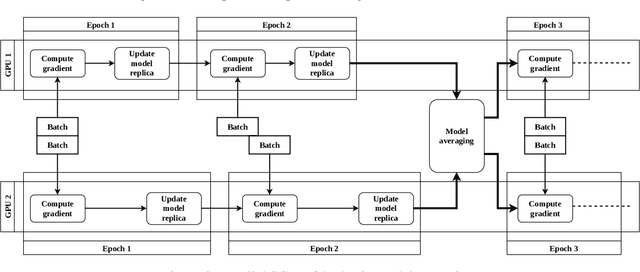
Motivated by extreme multi-label classification applications, we consider training deep learning models over sparse data in multi-GPU servers. The variance in the number of non-zero features across training batches and the intrinsic GPU heterogeneity combine to limit accuracy and increase the time to convergence. We address these challenges with Adaptive SGD, an adaptive elastic model averaging stochastic gradient descent algorithm for heterogeneous multi-GPUs that is characterized by dynamic scheduling, adaptive batch size scaling, and normalized model merging. Instead of statically partitioning batches to GPUs, batches are routed based on the relative processing speed. Batch size scaling assigns larger batches to the faster GPUs and smaller batches to the slower ones, with the goal to arrive at a steady state in which all the GPUs perform the same number of model updates. Normalized model merging computes optimal weights for every GPU based on the assigned batches such that the combined model achieves better accuracy. We show experimentally that Adaptive SGD outperforms four state-of-the-art solutions in time-to-accuracy and is scalable with the number of GPUs.
Embedded Self-Distillation in Compact Multi-Branch Ensemble Network for Remote Sensing Scene Classification
Apr 01, 2021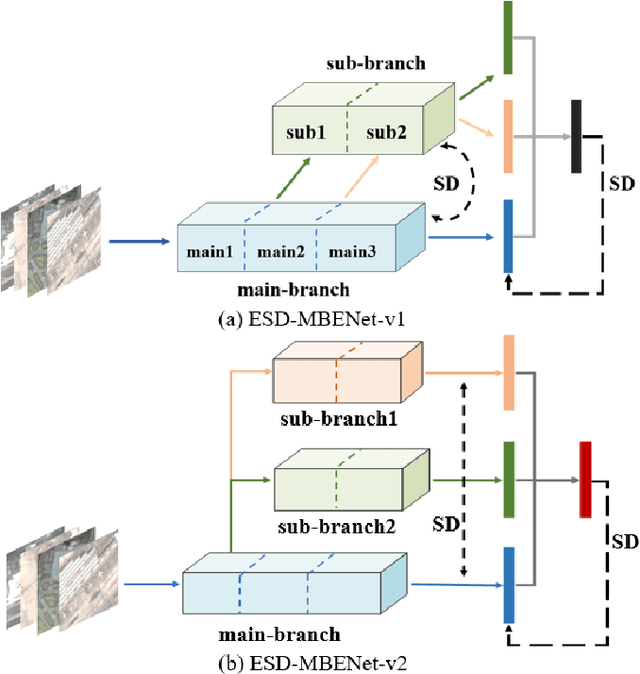
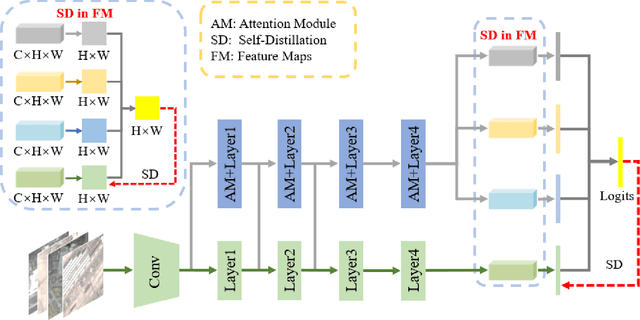
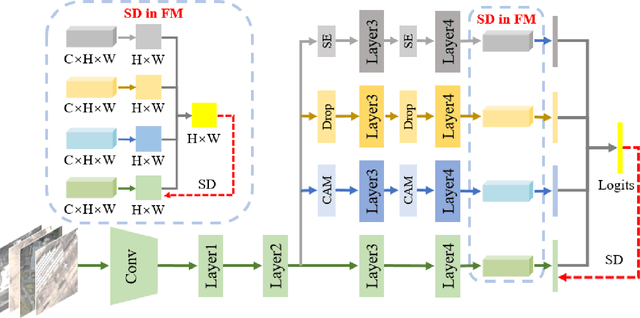
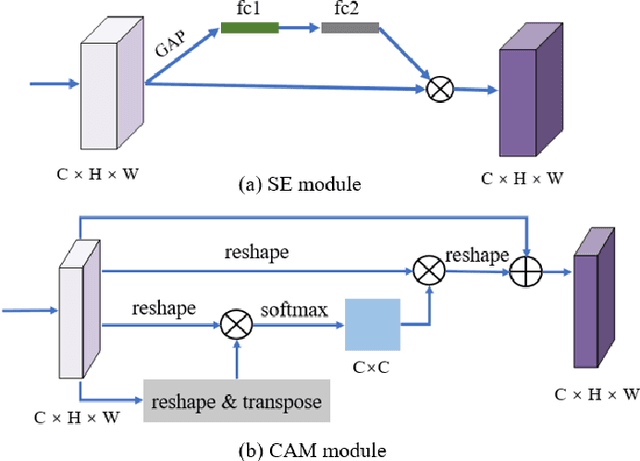
Remote sensing (RS) image scene classification task faces many challenges due to the interference from different characteristics of different geographical elements. To solve this problem, we propose a multi-branch ensemble network to enhance the feature representation ability by fusing features in final output logits and intermediate feature maps. However, simply adding branches will increase the complexity of models and decline the inference efficiency. On this issue, we embed self-distillation (SD) method to transfer knowledge from ensemble network to main-branch in it. Through optimizing with SD, main-branch will have close performance as ensemble network. During inference, we can cut other branches to simplify the whole model. In this paper, we first design compact multi-branch ensemble network, which can be trained in an end-to-end manner. Then, we insert SD method on output logits and feature maps. Compared to previous methods, our proposed architecture (ESD-MBENet) performs strongly on classification accuracy with compact design. Extensive experiments are applied on three benchmark RS datasets AID, NWPU-RESISC45 and UC-Merced with three classic baseline models, VGG16, ResNet50 and DenseNet121. Results prove that our proposed ESD-MBENet can achieve better accuracy than previous state-of-the-art (SOTA) complex models. Moreover, abundant visualization analysis make our method more convincing and interpretable.
MGML: Multi-Granularity Multi-Level Feature Ensemble Network for Remote Sensing Scene Classification
Dec 29, 2020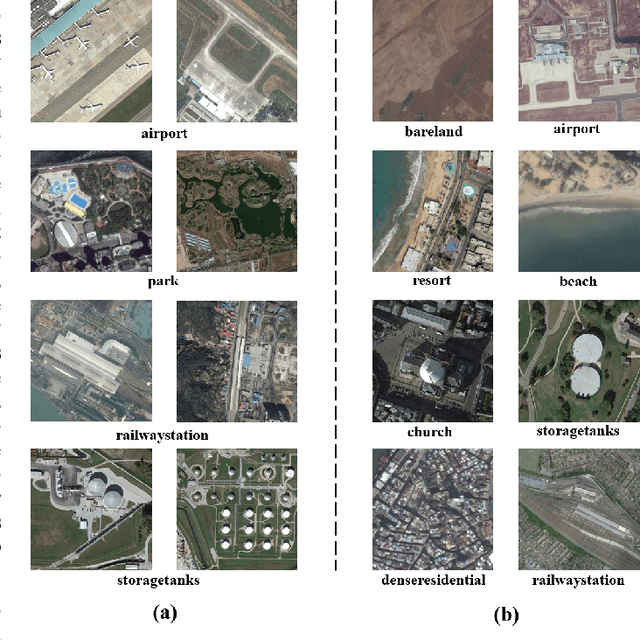
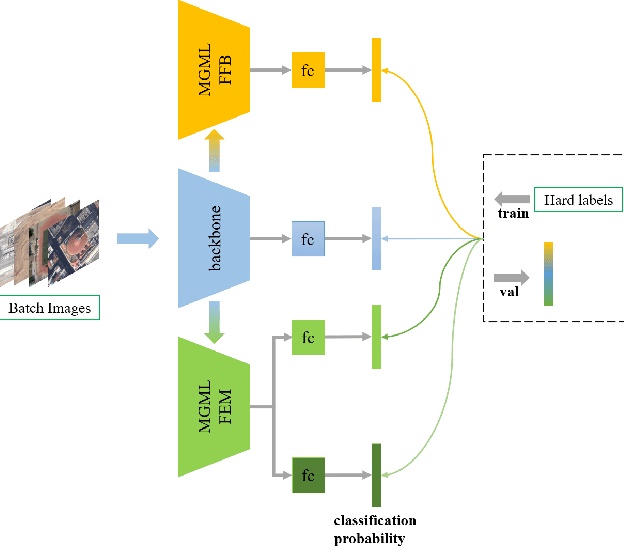
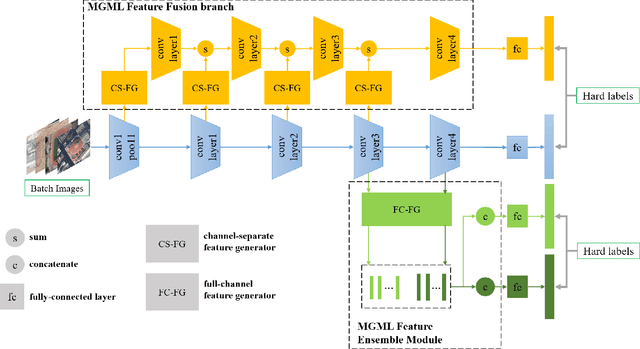
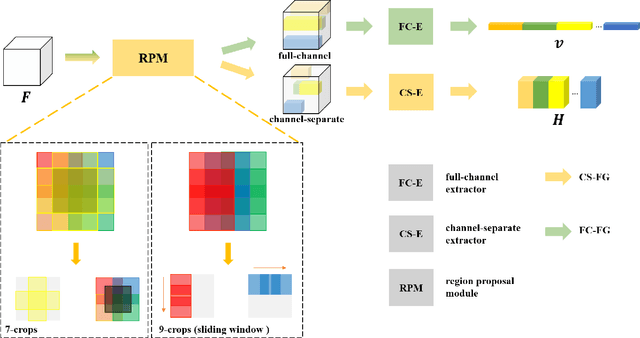
Remote sensing (RS) scene classification is a challenging task to predict scene categories of RS images. RS images have two main characters: large intra-class variance caused by large resolution variance and confusing information from large geographic covering area. To ease the negative influence from the above two characters. We propose a Multi-granularity Multi-Level Feature Ensemble Network (MGML-FENet) to efficiently tackle RS scene classification task in this paper. Specifically, we propose Multi-granularity Multi-Level Feature Fusion Branch (MGML-FFB) to extract multi-granularity features in different levels of network by channel-separate feature generator (CS-FG). To avoid the interference from confusing information, we propose Multi-granularity Multi-Level Feature Ensemble Module (MGML-FEM) which can provide diverse predictions by full-channel feature generator (FC-FG). Compared to previous methods, our proposed networks have ability to use structure information and abundant fine-grained features. Furthermore, through ensemble learning method, our proposed MGML-FENets can obtain more convincing final predictions. Extensive classification experiments on multiple RS datasets (AID, NWPU-RESISC45, UC-Merced and VGoogle) demonstrate that our proposed networks achieve better performance than previous state-of-the-art (SOTA) networks. The visualization analysis also shows the good interpretability of MGML-FENet.
Heterogeneous CPU+GPU Stochastic Gradient Descent Algorithms
Apr 19, 2020
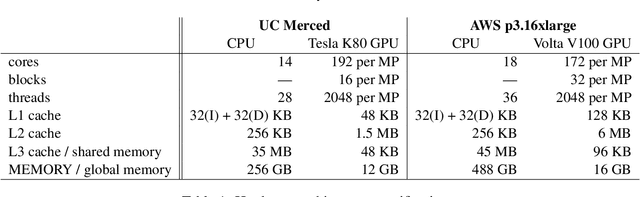
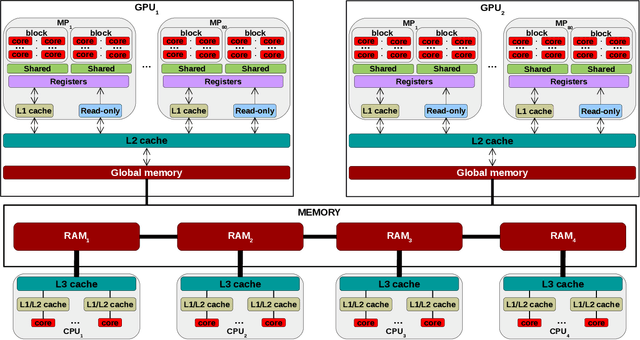

The widely-adopted practice is to train deep learning models with specialized hardware accelerators, e.g., GPUs or TPUs, due to their superior performance on linear algebra operations. However, this strategy does not employ effectively the extensive CPU and memory resources -- which are used only for preprocessing, data transfer, and scheduling -- available by default on the accelerated servers. In this paper, we study training algorithms for deep learning on heterogeneous CPU+GPU architectures. Our two-fold objective -- maximize convergence rate and resource utilization simultaneously -- makes the problem challenging. In order to allow for a principled exploration of the design space, we first introduce a generic deep learning framework that exploits the difference in computational power and memory hierarchy between CPU and GPU through asynchronous message passing. Based on insights gained through experimentation with the framework, we design two heterogeneous asynchronous stochastic gradient descent (SGD) algorithms. The first algorithm -- CPU+GPU Hogbatch -- combines small batches on CPU with large batches on GPU in order to maximize the utilization of both resources. However, this generates an unbalanced model update distribution which hinders the statistical convergence. The second algorithm -- Adaptive Hogbatch -- assigns batches with continuously evolving size based on the relative speed of CPU and GPU. This balances the model updates ratio at the expense of a customizable decrease in utilization. We show that the implementation of these algorithms in the proposed CPU+GPU framework achieves both faster convergence and higher resource utilization than TensorFlow on several real datasets and on two computing architectures -- an on-premises server and a cloud instance.
Stochastic Gradient Descent on Highly-Parallel Architectures
Feb 24, 2018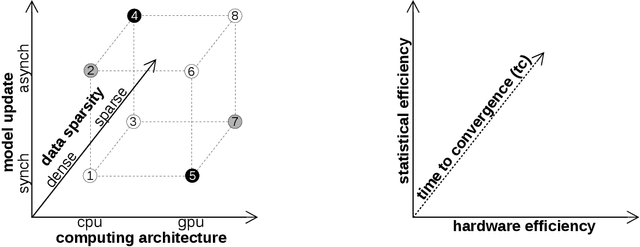
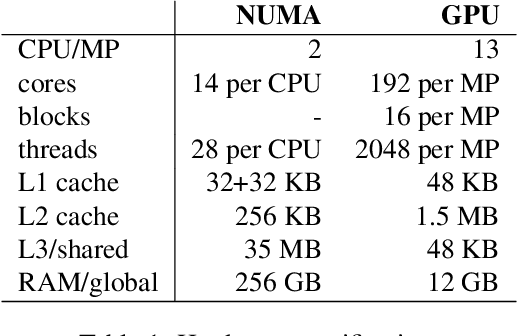

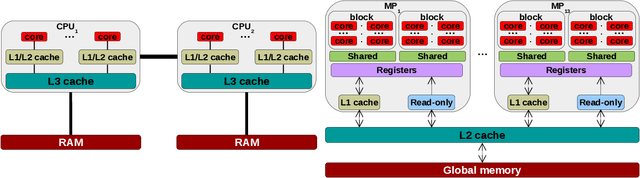
There is an increased interest in building data analytics frameworks with advanced algebraic capabilities both in industry and academia. Many of these frameworks, e.g., TensorFlow and BIDMach, implement their compute-intensive primitives in two flavors---as multi-thread routines for multi-core CPUs and as highly-parallel kernels executed on GPU. Stochastic gradient descent (SGD) is the most popular optimization method for model training implemented extensively on modern data analytics platforms. While the data-intensive properties of SGD are well-known, there is an intense debate on which of the many SGD variants is better in practice. In this paper, we perform a comprehensive study of parallel SGD for training generalized linear models. We consider the impact of three factors -- computing architecture (multi-core CPU or GPU), synchronous or asynchronous model updates, and data sparsity -- on three measures---hardware efficiency, statistical efficiency, and time to convergence. In the process, we design an optimized asynchronous SGD algorithm for GPU that leverages warp shuffling and cache coalescing for data and model access. We draw several interesting findings from our extensive experiments with logistic regression (LR) and support vector machines (SVM) on five real datasets. For synchronous SGD, GPU always outperforms parallel CPU---they both outperform a sequential CPU solution by more than 400X. For asynchronous SGD, parallel CPU is the safest choice while GPU with data replication is better in certain situations. The choice between synchronous GPU and asynchronous CPU depends on the task and the characteristics of the data. As a reference, our best implementation outperforms TensorFlow and BIDMach consistently. We hope that our insights provide a useful guide for applying parallel SGD to generalized linear models.