 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024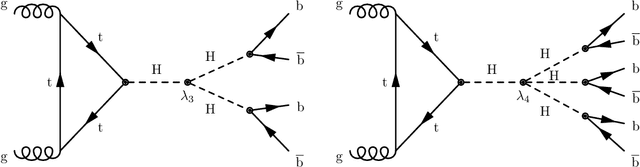



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.