 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Self-Driving Trigger at the LHC: Adaptive Response in Real Time
Jan 13, 2026Real-time data filtering and selection -- or trigger -- systems at high-throughput scientific facilities such as the experiments at the Large Hadron Collider (LHC) must process extremely high-rate data streams under stringent bandwidth, latency, and storage constraints. Yet these systems are typically designed as static, hand-tuned menus of selection criteria grounded in prior knowledge and simulation. In this work, we further explore the concept of a self-driving trigger, an autonomous data-filtering framework that reallocates resources and adjusts thresholds dynamically in real-time to optimize signal efficiency, rate stability, and computational cost as instrumentation and environmental conditions evolve. We introduce a benchmark ecosystem to emulate realistic collider scenarios and demonstrate real-time optimization of a menu including canonical energy sum triggers as well as modern anomaly-detection algorithms that target non-standard event topologies using machine learning. Using simulated data streams and publicly available collision data from the Compact Muon Solenoid (CMS) experiment, we demonstrate the capability to dynamically and automatically optimize trigger performance under specific cost objectives without manual retuning. Our adaptive strategy shifts trigger design from static menus with heuristic tuning to intelligent, automated, data-driven control, unlocking greater flexibility and discovery potential in future high-energy physics analyses.
Edge Machine Learning for Cluster Counting in Next-Generation Drift Chambers
Nov 16, 2025Drift chambers have long been central to collider tracking, but future machines like a Higgs factory motivate higher granularity and cluster counting for particle ID, posing new data processing challenges. Machine learning (ML) at the "edge", or in cell-level readout, can dramatically reduce the off-detector data rate for high-granularity drift chambers by performing cluster counting at-source. We present machine learning algorithms for cluster counting in real-time readout of future drift chambers. These algorithms outperform traditional derivative-based techniques based on achievable pion-kaon separation. When synthesized to FPGA resources, they can achieve latencies consistent with real-time operation in a future Higgs factory scenario, thus advancing both R&D for future collider detectors as well as hardware-based ML for edge applications in high energy physics.
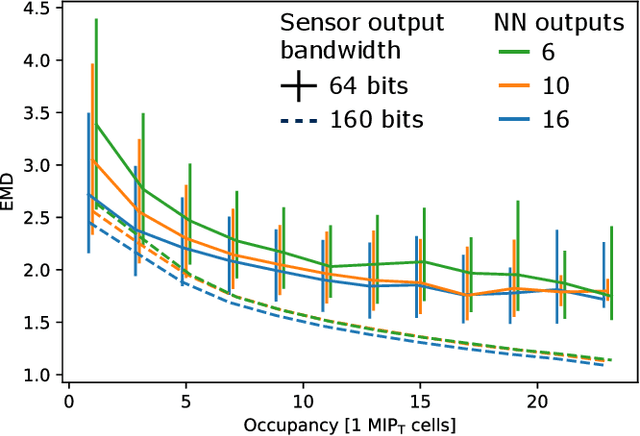
Differentiable Earth Mover's Distance for Data Compression at the High-Luminosity LHC
Jun 07, 2023The Earth mover's distance (EMD) is a useful metric for image recognition and classification, but its usual implementations are not differentiable or too slow to be used as a loss function for training other algorithms via gradient descent. In this paper, we train a convolutional neural network (CNN) to learn a differentiable, fast approximation of the EMD and demonstrate that it can be used as a substitute for computing-intensive EMD implementations. We apply this differentiable approximation in the training of an autoencoder-inspired neural network (encoder NN) for data compression at the high-luminosity LHC at CERN. The goal of this encoder NN is to compress the data while preserving the information related to the distribution of energy deposits in particle detectors. We demonstrate that the performance of our encoder NN trained using the differentiable EMD CNN surpasses that of training with loss functions based on mean squared error.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022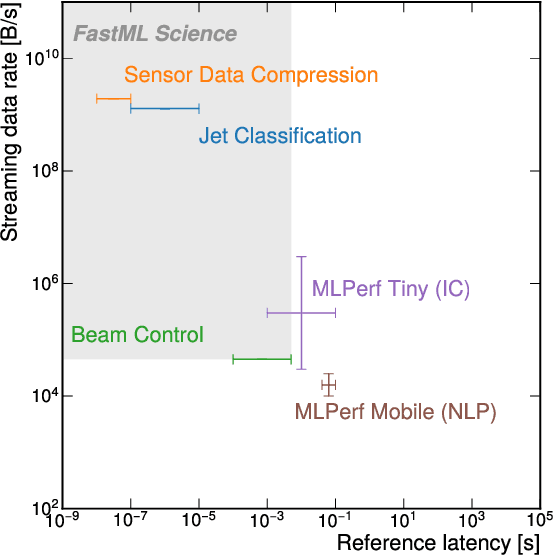
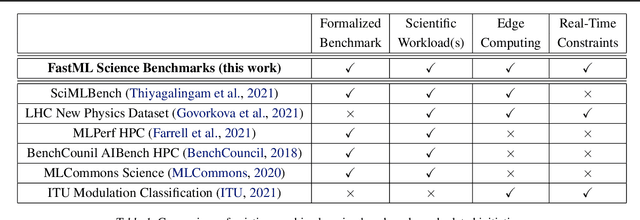
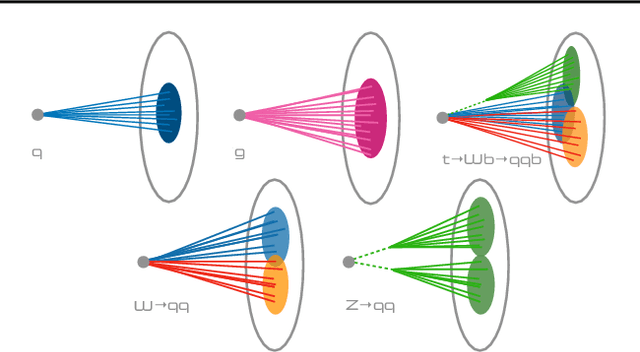

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
Physics Community Needs, Tools, and Resources for Machine Learning
Mar 30, 2022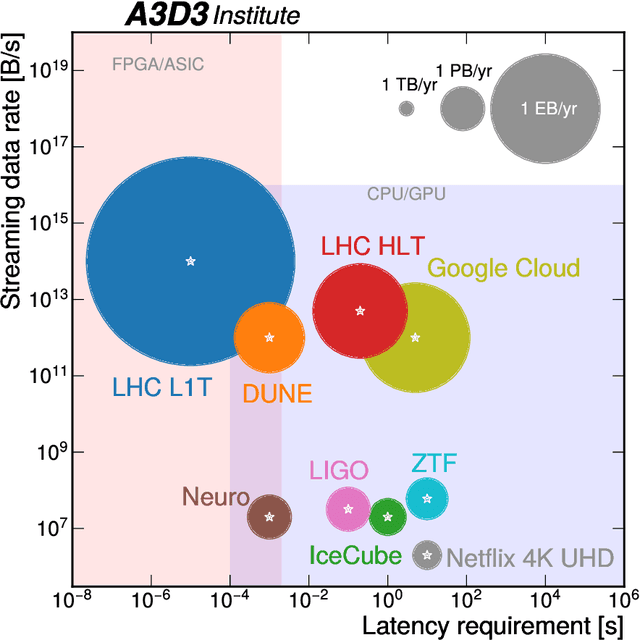

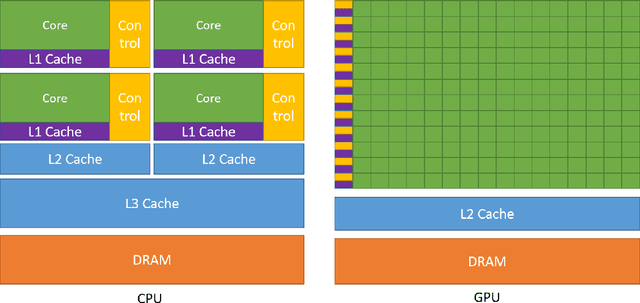
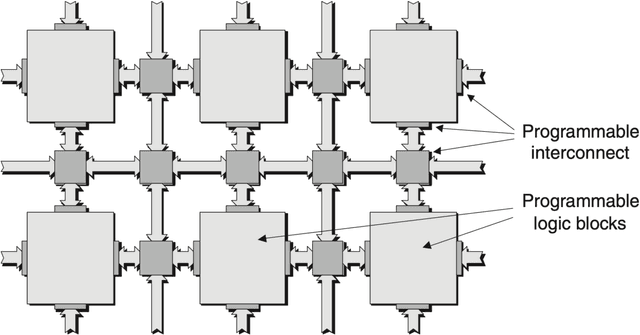
Machine learning (ML) is becoming an increasingly important component of cutting-edge physics research, but its computational requirements present significant challenges. In this white paper, we discuss the needs of the physics community regarding ML across latency and throughput regimes, the tools and resources that offer the possibility of addressing these needs, and how these can be best utilized and accessed in the coming years.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
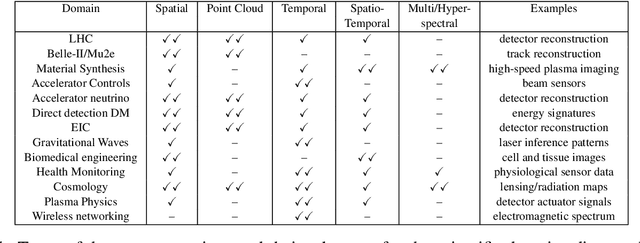
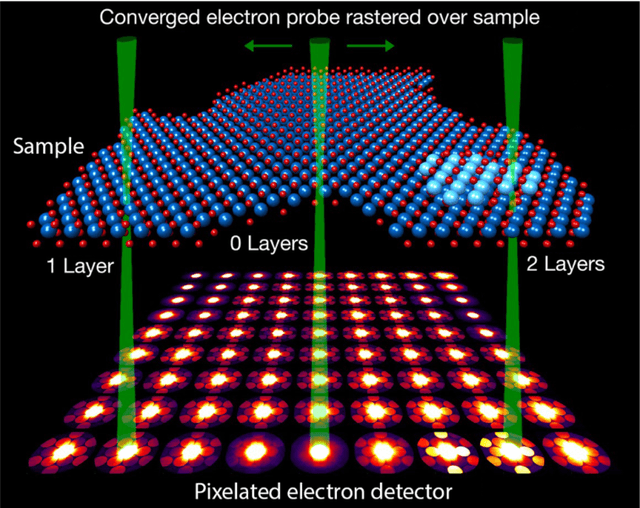
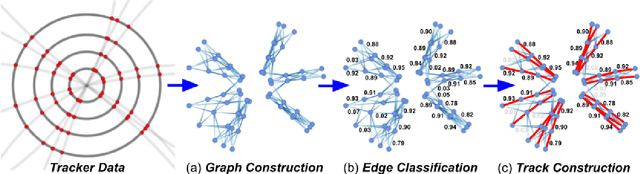
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
A reconfigurable neural network ASIC for detector front-end data compression at the HL-LHC
May 04, 2021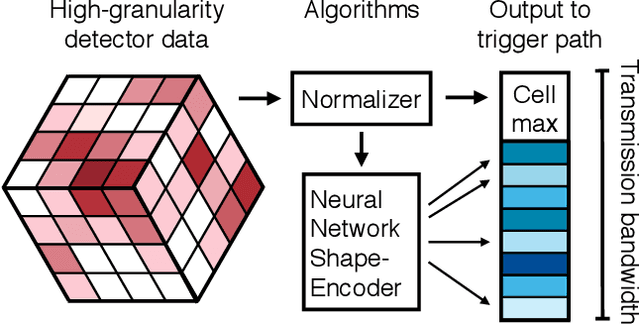
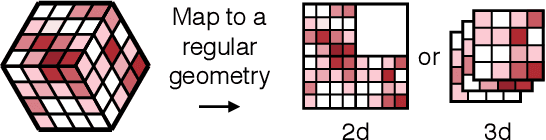
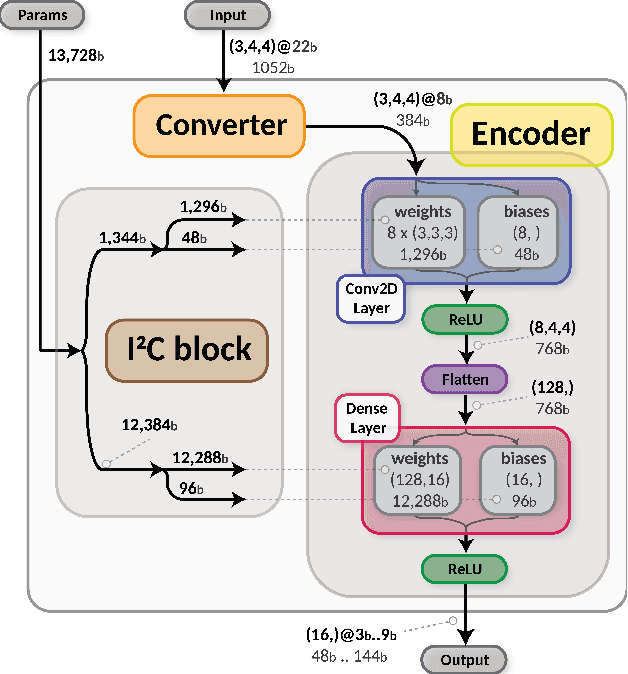
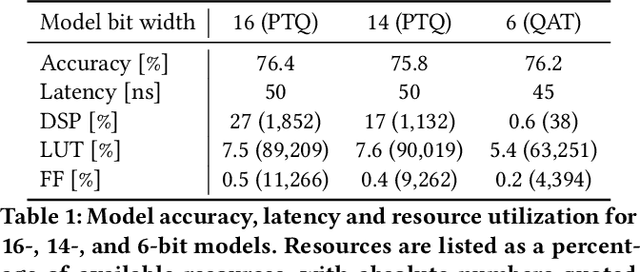
Despite advances in the programmable logic capabilities of modern trigger systems, a significant bottleneck remains in the amount of data to be transported from the detector to off-detector logic where trigger decisions are made. We demonstrate that a neural network autoencoder model can be implemented in a radiation tolerant ASIC to perform lossy data compression alleviating the data transmission problem while preserving critical information of the detector energy profile. For our application, we consider the high-granularity calorimeter from the CMS experiment at the CERN Large Hadron Collider. The advantage of the machine learning approach is in the flexibility and configurability of the algorithm. By changing the neural network weights, a unique data compression algorithm can be deployed for each sensor in different detector regions, and changing detector or collider conditions. To meet area, performance, and power constraints, we perform a quantization-aware training to create an optimized neural network hardware implementation. The design is achieved through the use of high-level synthesis tools and the hls4ml framework, and was processed through synthesis and physical layout flows based on a LP CMOS 65 nm technology node. The flow anticipates 200 Mrad of ionizing radiation to select gates, and reports a total area of 3.6 mm^2 and consumes 95 mW of power. The simulated energy consumption per inference is 2.4 nJ. This is the first radiation tolerant on-detector ASIC implementation of a neural network that has been designed for particle physics applications.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021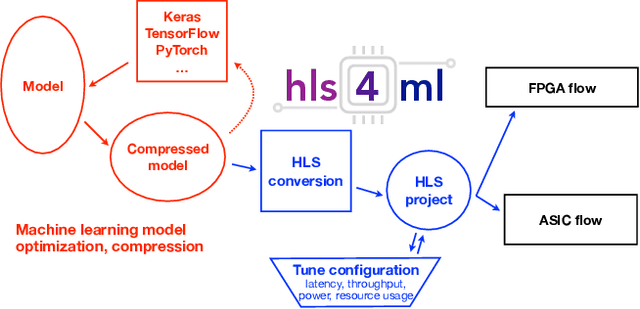
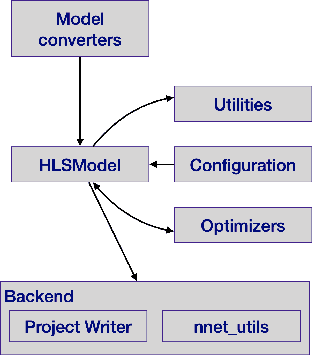
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.