 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024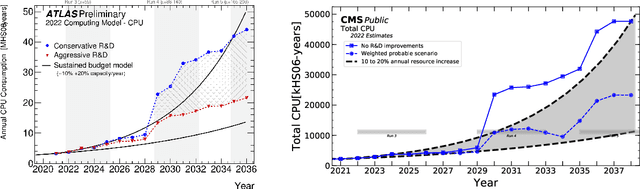
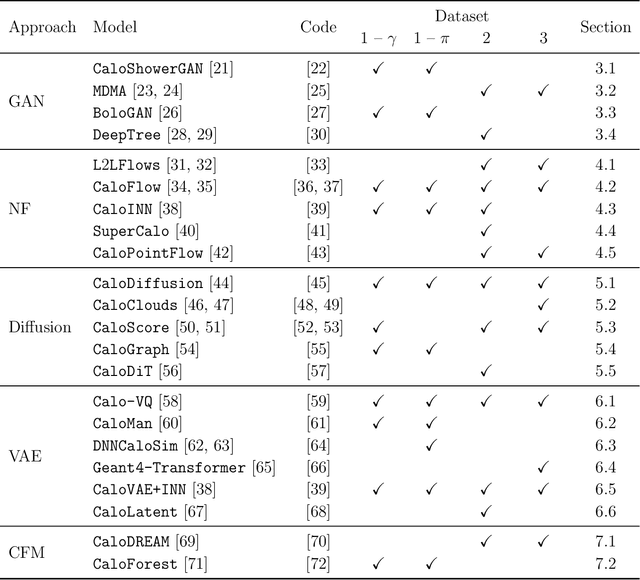
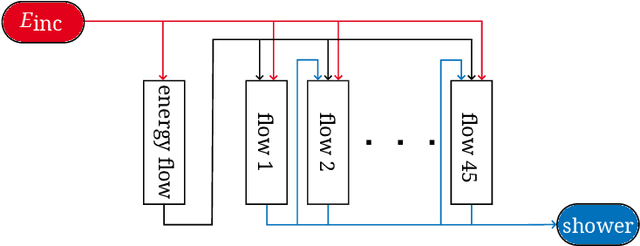
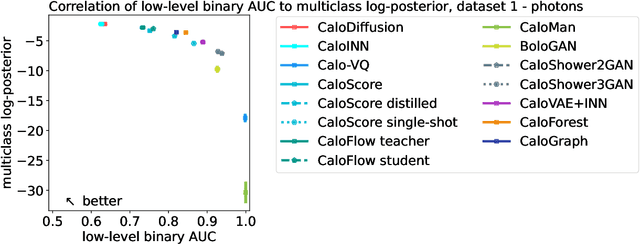
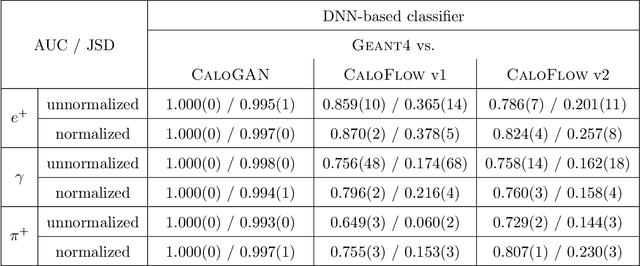
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Semi-Supervised Domain Adaptation for Cross-Survey Galaxy Morphology Classification and Anomaly Detection
Nov 11, 2022



In the era of big astronomical surveys, our ability to leverage artificial intelligence algorithms simultaneously for multiple datasets will open new avenues for scientific discovery. Unfortunately, simply training a deep neural network on images from one data domain often leads to very poor performance on any other dataset. Here we develop a Universal Domain Adaptation method DeepAstroUDA, capable of performing semi-supervised domain alignment that can be applied to datasets with different types of class overlap. Extra classes can be present in any of the two datasets, and the method can even be used in the presence of unknown classes. For the first time, we demonstrate the successful use of domain adaptation on two very different observational datasets (from SDSS and DECaLS). We show that our method is capable of bridging the gap between two astronomical surveys, and also performs well for anomaly detection and clustering of unknown data in the unlabeled dataset. We apply our model to two examples of galaxy morphology classification tasks with anomaly detection: 1) classifying spiral and elliptical galaxies with detection of merging galaxies (three classes including one unknown anomaly class); 2) a more granular problem where the classes describe more detailed morphological properties of galaxies, with the detection of gravitational lenses (ten classes including one unknown anomaly class).
Physics Community Needs, Tools, and Resources for Machine Learning
Mar 30, 2022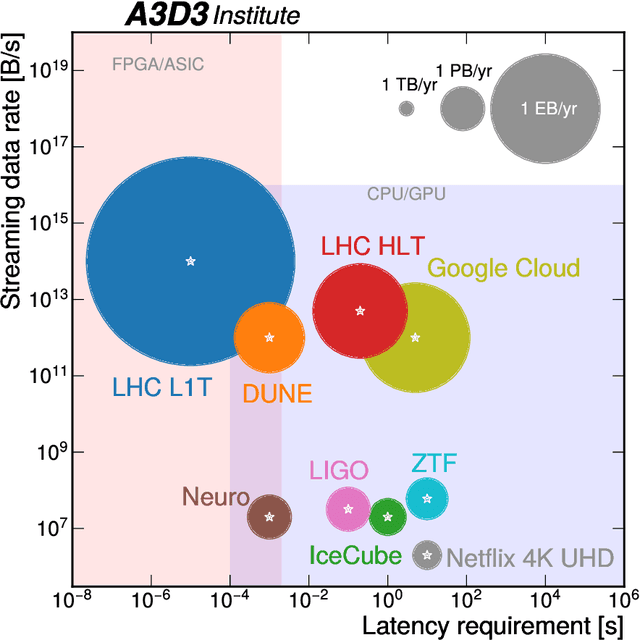

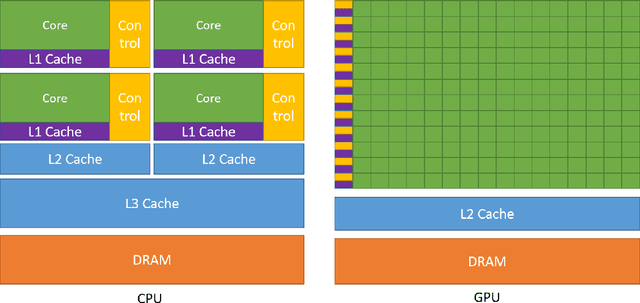
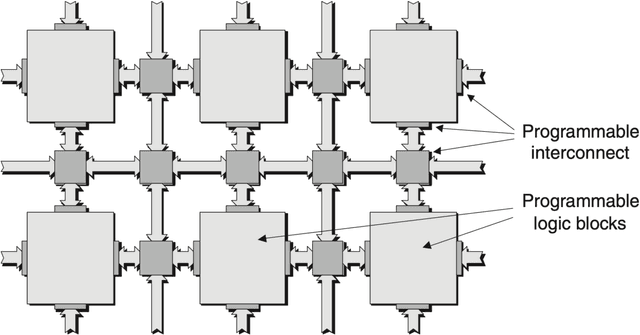
Machine learning (ML) is becoming an increasingly important component of cutting-edge physics research, but its computational requirements present significant challenges. In this white paper, we discuss the needs of the physics community regarding ML across latency and throughput regimes, the tools and resources that offer the possibility of addressing these needs, and how these can be best utilized and accessed in the coming years.
New directions for surrogate models and differentiable programming for High Energy Physics detector simulation
Mar 15, 2022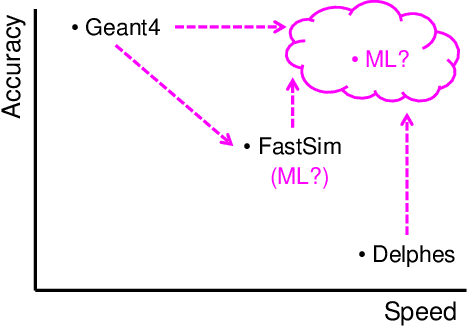
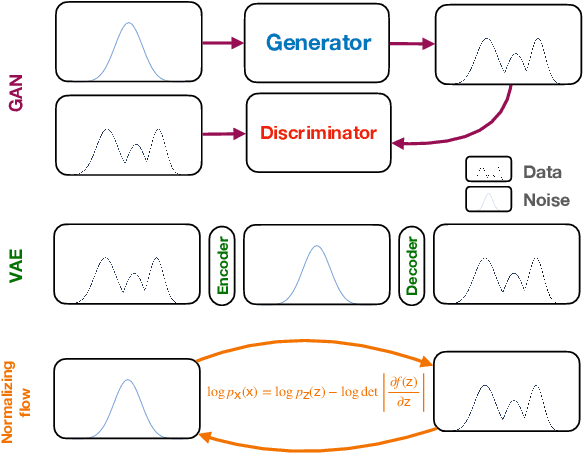
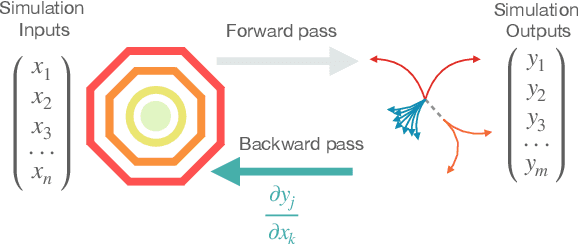
The computational cost for high energy physics detector simulation in future experimental facilities is going to exceed the current available resources. To overcome this challenge, new ideas on surrogate models using machine learning methods are being explored to replace computationally expensive components. Additionally, differentiable programming has been proposed as a complementary approach, providing controllable and scalable simulation routines. In this document, new and ongoing efforts for surrogate models and differential programming applied to detector simulation are discussed in the context of the 2021 Particle Physics Community Planning Exercise (`Snowmass').
DeepAdversaries: Examining the Robustness of Deep Learning Models for Galaxy Morphology Classification
Dec 28, 2021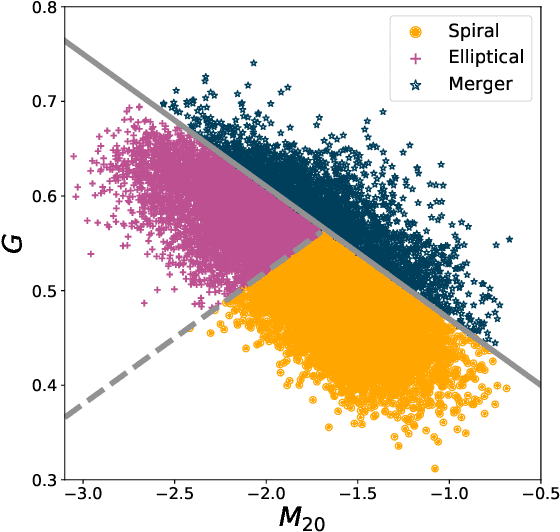
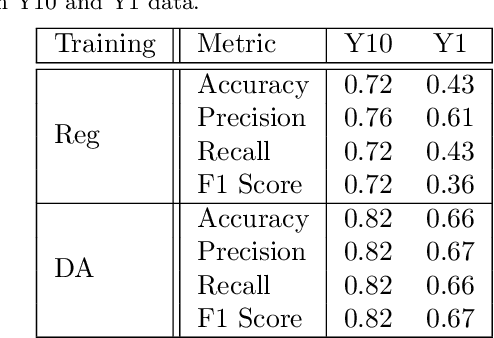
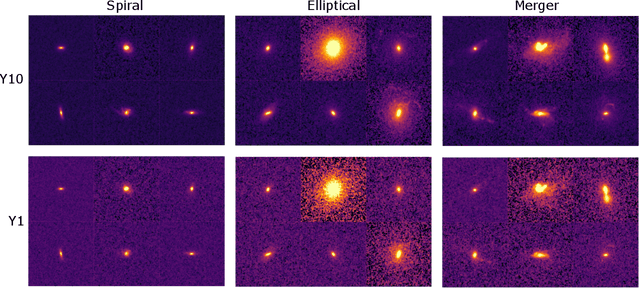
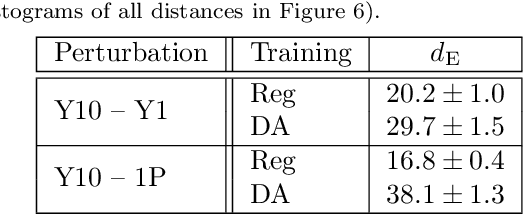
Data processing and analysis pipelines in cosmological survey experiments introduce data perturbations that can significantly degrade the performance of deep learning-based models. Given the increased adoption of supervised deep learning methods for processing and analysis of cosmological survey data, the assessment of data perturbation effects and the development of methods that increase model robustness are increasingly important. In the context of morphological classification of galaxies, we study the effects of perturbations in imaging data. In particular, we examine the consequences of using neural networks when training on baseline data and testing on perturbed data. We consider perturbations associated with two primary sources: 1) increased observational noise as represented by higher levels of Poisson noise and 2) data processing noise incurred by steps such as image compression or telescope errors as represented by one-pixel adversarial attacks. We also test the efficacy of domain adaptation techniques in mitigating the perturbation-driven errors. We use classification accuracy, latent space visualizations, and latent space distance to assess model robustness. Without domain adaptation, we find that processing pixel-level errors easily flip the classification into an incorrect class and that higher observational noise makes the model trained on low-noise data unable to classify galaxy morphologies. On the other hand, we show that training with domain adaptation improves model robustness and mitigates the effects of these perturbations, improving the classification accuracy by 23% on data with higher observational noise. Domain adaptation also increases by a factor of ~2.3 the latent space distance between the baseline and the incorrectly classified one-pixel perturbed image, making the model more robust to inadvertent perturbations.
Autoencoders for Semivisible Jet Detection
Dec 09, 2021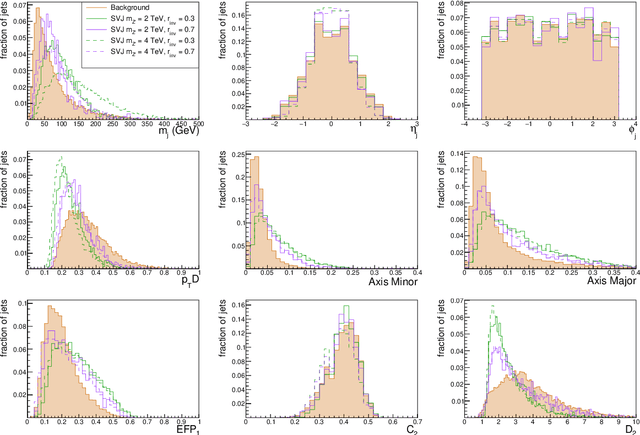
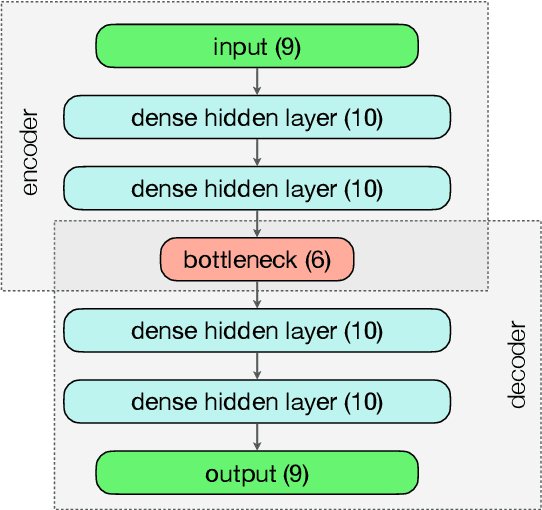
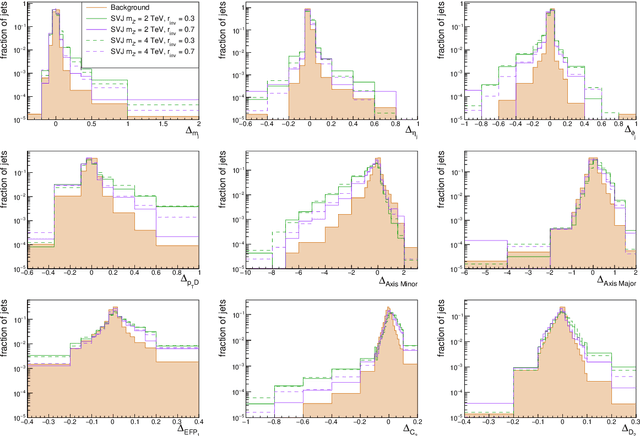
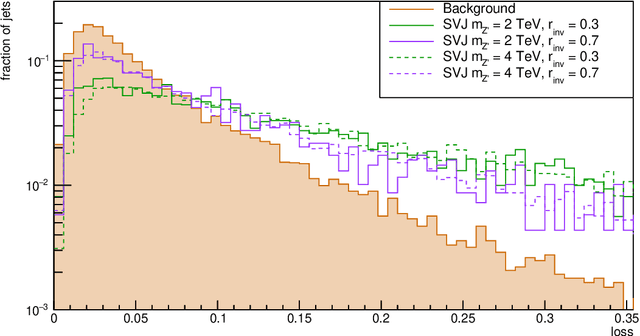
The production of dark matter particles from confining dark sectors may lead to many novel experimental signatures. Depending on the details of the theory, dark quark production in proton-proton collisions could result in semivisible jets of particles: collimated sprays of dark hadrons of which only some are detectable by particle collider experiments. The experimental signature is characterised by the presence of reconstructed missing momentum collinear with the visible components of the jets. This complex topology is sensitive to detector inefficiencies and mis-reconstruction that generate artificial missing momentum. With this work, we propose a signal-agnostic strategy to reject ordinary jets and identify semivisible jets via anomaly detection techniques. A deep neural autoencoder network with jet substructure variables as input proves highly useful for analyzing anomalous jets. The study focuses on the semivisible jet signature; however, the technique can apply to any new physics model that predicts signatures with jets from non-SM particles.
Fast convolutional neural networks on FPGAs with hls4ml
Jan 13, 2021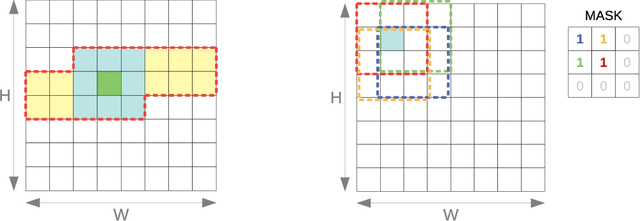
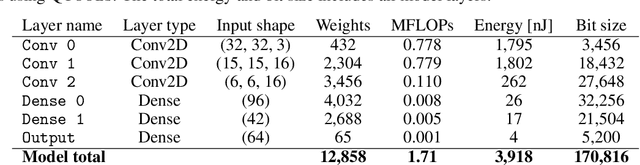
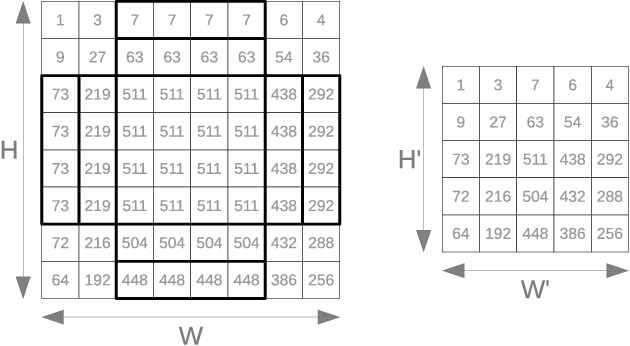

We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with large convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate how to achieve inference latency of $5\,\mu$s using convolutional architectures, while preserving state-of-the-art model performance. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be reduced by over 90% while maintaining the original model accuracy.
Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics
Aug 08, 2020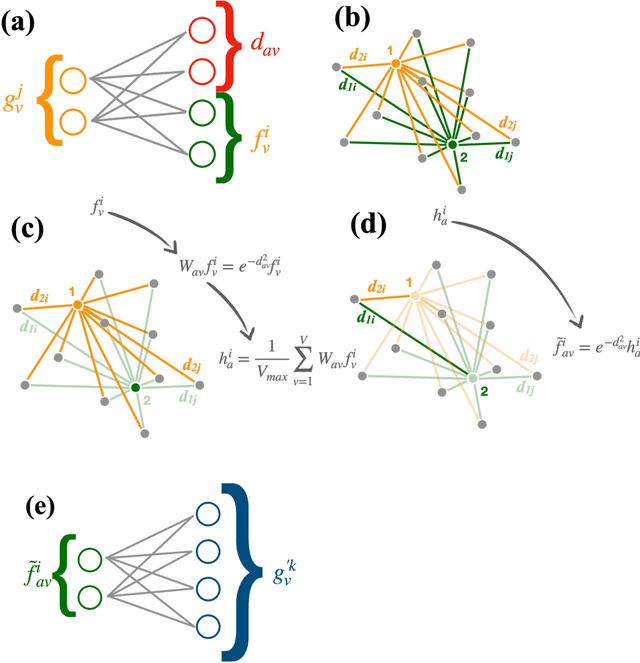


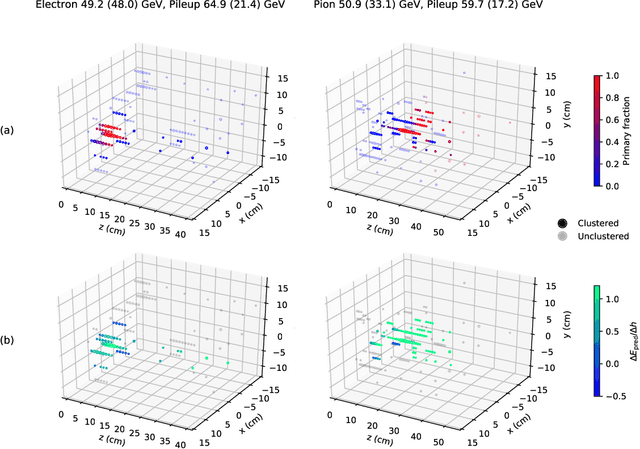
Graph neural networks have been shown to achieve excellent performance for several crucial tasks in particle physics, such as charged particle tracking, jet tagging, and clustering. An important domain for the application of these networks is the FGPA-based first layer of real-time data filtering at the CERN Large Hadron Collider, which has strict latency and resource constraints. We discuss how to design distance-weighted graph networks that can be executed with a latency of less than 1$\mu\mathrm{s}$ on an FPGA. To do so, we consider a representative task associated to particle reconstruction and identification in a next-generation calorimeter operating at a particle collider. We use a graph network architecture developed for such purposes, and apply additional simplifications to match the computing constraints of Level-1 trigger systems, including weight quantization. Using the $\mathtt{hls4ml}$ library, we convert the compressed models into firmware to be implemented on an FPGA. Performance of the synthesized models is presented both in terms of inference accuracy and resource usage.
Compressing deep neural networks on FPGAs to binary and ternary precision with HLS4ML
Mar 11, 2020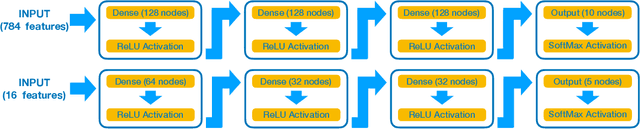
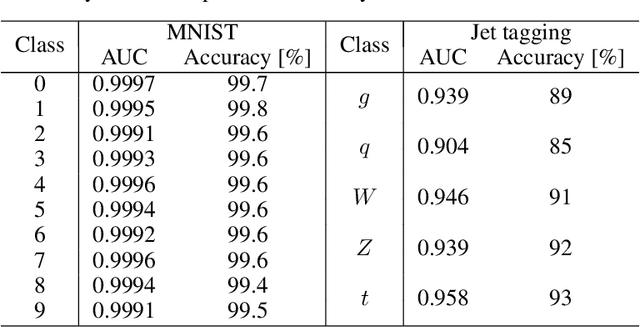
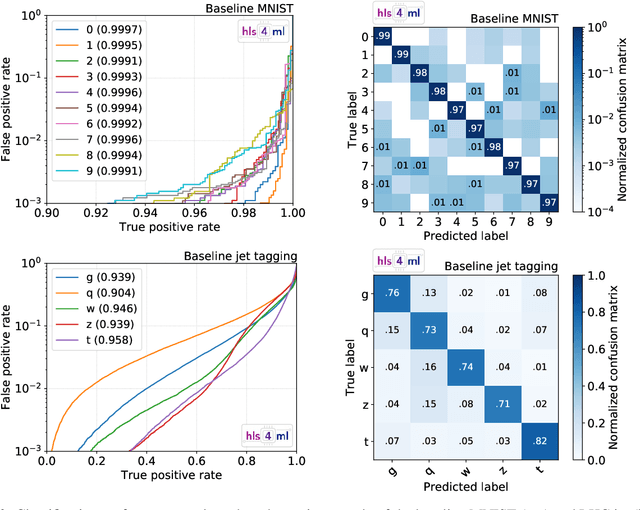

We present the implementation of binary and ternary neural networks in the hls4ml library, designed to automatically convert deep neural network models to digital circuits with FPGA firmware. Starting from benchmark models trained with floating point precision, we investigate different strategies to reduce the network's resource consumption by reducing the numerical precision of the network parameters to binary or ternary. We discuss the trade-off between model accuracy and resource consumption. In addition, we show how to balance between latency and accuracy by retaining full precision on a selected subset of network components. As an example, we consider two multiclass classification tasks: handwritten digit recognition with the MNIST data set and jet identification with simulated proton-proton collisions at the CERN Large Hadron Collider. The binary and ternary implementation has similar performance to the higher precision implementation while using drastically fewer FPGA resources.