 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Every Layer Knows the Token Beneath the Context
May 07, 2026We revisit a universally accepted but under-examined design choice in every modern LLM: a token index is looked up once at the input embedding layer and then permanently discarded. This single-injection assumption induces two structural failures: (i) the Rare Token Problem, where a Zipf-type distribution of vocabulary causes rare-token embeddings are chronically under-trained due to receiving a fraction of the cumulative gradient signal compared to common tokens; and (ii) the Contextual Collapse Problem, where limited parameters models map distributionally similar tokens to indistinguishable hidden states. As an attempt to address both, we propose TIDE, which augments the standard transformer with EmbeddingMemory: an ensemble of K independent MemoryBlocks that map token indices to context-free semantic vectors, computed once and injected into every layer through a depth-conditioned softmax router with a learnable null bank. We theoretically and empirically establish the benefits of TIDE in addressing the issues associated with single-token identity injection as well as improve performance across multiple language modeling and downstream tasks.
SpecMD: A Comprehensive Study On Speculative Expert Prefetching
Feb 03, 2026Mixture-of-Experts (MoE) models enable sparse expert activation, meaning that only a subset of the model's parameters is used during each inference. However, to translate this sparsity into practical performance, an expert caching mechanism is required. Previous works have proposed hardware-centric caching policies, but how these various caching policies interact with each other and different hardware specification remains poorly understood. To address this gap, we develop \textbf{SpecMD}, a standardized framework for benchmarking ad-hoc cache policies on various hardware configurations. Using SpecMD, we perform an exhaustive benchmarking of several MoE caching strategies, reproducing and extending prior approaches in controlled settings with realistic constraints. Our experiments reveal that MoE expert access is not consistent with temporal locality assumptions (e.g LRU, LFU). Motivated by this observation, we propose \textbf{Least-Stale}, a novel eviction policy that exploits MoE's predictable expert access patterns to reduce collision misses by up to $85\times$ over LRU. With such gains, we achieve over $88\%$ hit rates with up to $34.7\%$ Time-to-first-token (TTFT) reduction on OLMoE at only $5\%$ or $0.6GB$ of VRAM cache capacity.
Position: The Need for Ultrafast Training
Feb 02, 2026Domain-specialized FPGAs have delivered unprecedented performance for low-latency inference across scientific and industrial workloads, yet nearly all existing accelerators assume static models trained offline, relegating learning and adaptation to slower CPUs or GPUs. This separation fundamentally limits systems that must operate in non-stationary, high-frequency environments, where model updates must occur at the timescale of the underlying physics. In this paper, I argue for a shift from inference-only accelerators to ultrafast on-chip learning, in which both inference and training execute directly within the FPGA fabric under deterministic, sub-microsecond latency constraints. Bringing learning into the same real-time datapath as inference would enable closed-loop systems that adapt as fast as the physical processes they control, with applications spanning quantum error correction, cryogenic qubit calibration, plasma and fusion control, accelerator tuning, and autonomous scientific experiments. Enabling such regimes requires rethinking algorithms, architectures, and toolflows jointly, but promises to transform FPGAs from static inference engines into real-time learning machines.
Ultrafast On-chip Online Learning via Spline Locality in Kolmogorov-Arnold Networks
Feb 02, 2026Ultrafast online learning is essential for high-frequency systems, such as controls for quantum computing and nuclear fusion, where adaptation must occur on sub-microsecond timescales. Meeting these requirements demands low-latency, fixed-precision computation under strict memory constraints, a regime in which conventional Multi-Layer Perceptrons (MLPs) are both inefficient and numerically unstable. We identify key properties of Kolmogorov-Arnold Networks (KANs) that align with these constraints. Specifically, we show that: (i) KAN updates exploiting B-spline locality are sparse, enabling superior on-chip resource scaling, and (ii) KANs are inherently robust to fixed-point quantization. By implementing fixed-point online training on Field-Programmable Gate Arrays (FPGAs), a representative platform for on-chip computation, we demonstrate that KAN-based online learners are significantly more efficient and expressive than MLPs across a range of low-latency and resource-constrained tasks. To our knowledge, this work is the first to demonstrate model-free online learning at sub-microsecond latencies.
MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
Jan 30, 2026Understanding how transformer components operate in LLMs is important, as it is at the core of recent technological advances in artificial intelligence. In this work, we revisit the challenges associated with interpretability of feed-forward modules (FFNs) and propose MemoryLLM, which aims to decouple FFNs from self-attention and enables us to study the decoupled FFNs as context-free token-wise neural retrieval memory. In detail, we investigate how input tokens access memory locations within FFN parameters and the importance of FFN memory across different downstream tasks. MemoryLLM achieves context-free FFNs by training them in isolation from self-attention directly using the token embeddings. This approach allows FFNs to be pre-computed as token-wise lookups (ToLs), enabling on-demand transfer between VRAM and storage, additionally enhancing inference efficiency. We also introduce Flex-MemoryLLM, positioning it between a conventional transformer design and MemoryLLM. This architecture bridges the performance gap caused by training FFNs with context-free token-wise embeddings.
KANELÉ: Kolmogorov-Arnold Networks for Efficient LUT-based Evaluation
Dec 14, 2025Low-latency, resource-efficient neural network inference on FPGAs is essential for applications demanding real-time capability and low power. Lookup table (LUT)-based neural networks are a common solution, combining strong representational power with efficient FPGA implementation. In this work, we introduce KANELÉ, a framework that exploits the unique properties of Kolmogorov-Arnold Networks (KANs) for FPGA deployment. Unlike traditional multilayer perceptrons (MLPs), KANs employ learnable one-dimensional splines with fixed domains as edge activations, a structure naturally suited to discretization and efficient LUT mapping. We present the first systematic design flow for implementing KANs on FPGAs, co-optimizing training with quantization and pruning to enable compact, high-throughput, and low-latency KAN architectures. Our results demonstrate up to a 2700x speedup and orders of magnitude resource savings compared to prior KAN-on-FPGA approaches. Moreover, KANELÉ matches or surpasses other LUT-based architectures on widely used benchmarks, particularly for tasks involving symbolic or physical formulas, while balancing resource usage across FPGA hardware. Finally, we showcase the versatility of the framework by extending it to real-time, power-efficient control systems.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
SPD: Sync-Point Drop for efficient tensor parallelism of Large Language Models
Feb 28, 2025With the rapid expansion in the scale of large language models (LLMs), enabling efficient distributed inference across multiple computing units has become increasingly critical. However, communication overheads from popular distributed inference techniques such as Tensor Parallelism pose a significant challenge to achieve scalability and low latency. Therefore, we introduce a novel optimization technique, Sync-Point Drop (SPD), to reduce communication overheads in tensor parallelism by selectively dropping synchronization on attention outputs. In detail, we first propose a block design that allows execution to proceed without communication through SPD. Second, we apply different SPD strategies to attention blocks based on their sensitivity to the model accuracy. The proposed methods effectively alleviate communication bottlenecks while minimizing accuracy degradation during LLM inference, offering a scalable solution for diverse distributed environments: SPD offered about 20% overall inference latency reduction with < 1% accuracy regression for LLaMA2-70B inference over 8 GPUs.
Zero-Shot Neural Architecture Search: Challenges, Solutions, and Opportunities
Jul 05, 2023Recently, zero-shot (or training-free) Neural Architecture Search (NAS) approaches have been proposed to liberate the NAS from training requirements. The key idea behind zero-shot NAS approaches is to design proxies that predict the accuracies of the given networks without training network parameters. The proxies proposed so far are usually inspired by recent progress in theoretical deep learning and have shown great potential on several NAS benchmark datasets. This paper aims to comprehensively review and compare the state-of-the-art (SOTA) zero-shot NAS approaches, with an emphasis on their hardware awareness. To this end, we first review the mainstream zero-shot proxies and discuss their theoretical underpinnings. We then compare these zero-shot proxies through large-scale experiments and demonstrate their effectiveness in both hardware-aware and hardware-oblivious NAS scenarios. Finally, we point out several promising ideas to design better proxies. Our source code and the related paper list are available on https://github.com/SLDGroup/survey-zero-shot-nas.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021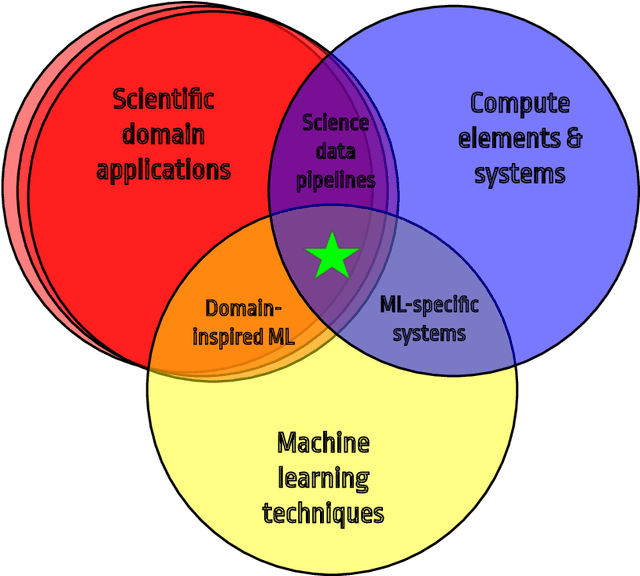
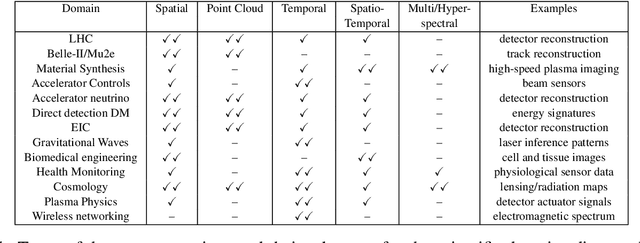
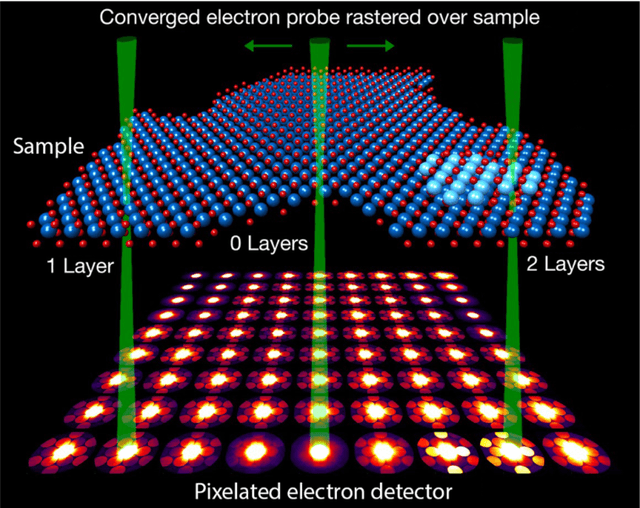
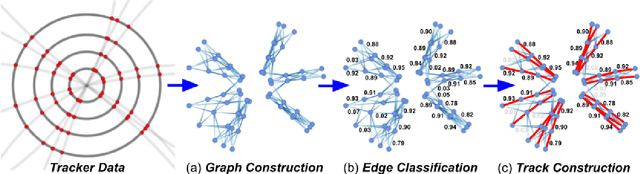
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.