 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Double-Edged Sword of Data-Driven Super-Resolution: Adversarial Super-Resolution Models
Feb 06, 2026Data-driven super-resolution (SR) methods are often integrated into imaging pipelines as preprocessing steps to improve downstream tasks such as classification and detection. However, these SR models introduce a previously unexplored attack surface into imaging pipelines. In this paper, we present AdvSR, a framework demonstrating that adversarial behavior can be embedded directly into SR model weights during training, requiring no access to inputs at inference time. Unlike prior attacks that perturb inputs or rely on backdoor triggers, AdvSR operates entirely at the model level. By jointly optimizing for reconstruction quality and targeted adversarial outcomes, AdvSR produces models that appear benign under standard image quality metrics while inducing downstream misclassification. We evaluate AdvSR on three SR architectures (SRCNN, EDSR, SwinIR) paired with a YOLOv11 classifier and demonstrate that AdvSR models can achieve high attack success rates with minimal quality degradation. These findings highlight a new model-level threat for imaging pipelines, with implications for how practitioners source and validate models in safety-critical applications.
Hyperparameter Optimization in Binary Communication Networks for Neuromorphic Deployment
Apr 21, 2020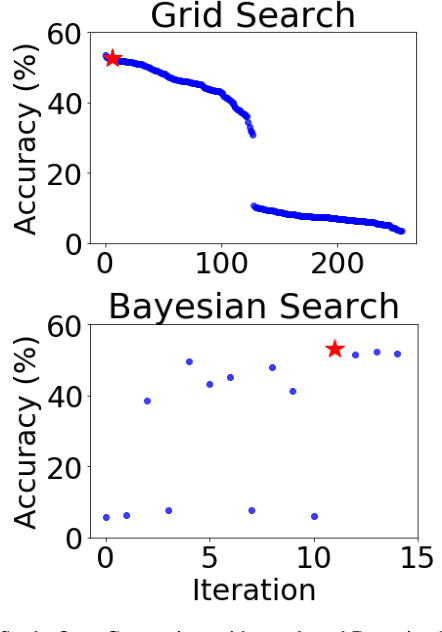
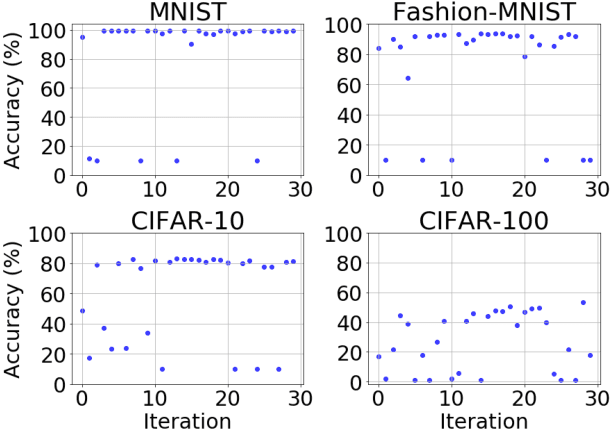

Training neural networks for neuromorphic deployment is non-trivial. There have been a variety of approaches proposed to adapt back-propagation or back-propagation-like algorithms appropriate for training. Considering that these networks often have very different performance characteristics than traditional neural networks, it is often unclear how to set either the network topology or the hyperparameters to achieve optimal performance. In this work, we introduce a Bayesian approach for optimizing the hyperparameters of an algorithm for training binary communication networks that can be deployed to neuromorphic hardware. We show that by optimizing the hyperparameters on this algorithm for each dataset, we can achieve improvements in accuracy over the previous state-of-the-art for this algorithm on each dataset (by up to 15 percent). This jump in performance continues to emphasize the potential when converting traditional neural networks to binary communication applicable to neuromorphic hardware.
Inferring Convolutional Neural Networks' accuracies from their architectural characterizations
Jan 10, 2020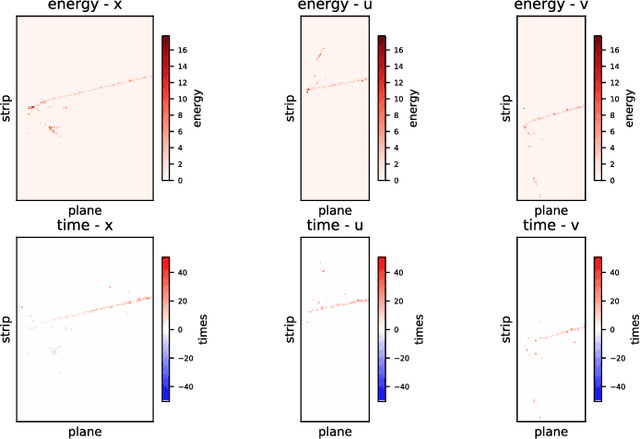
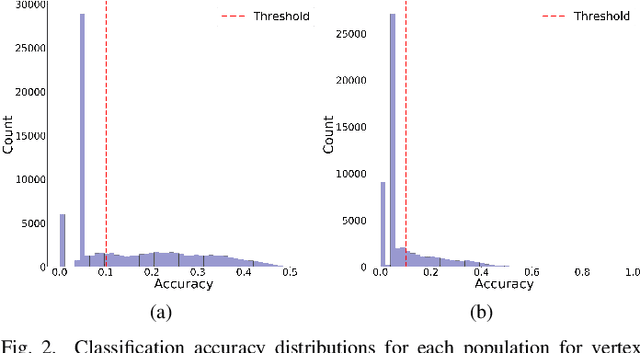
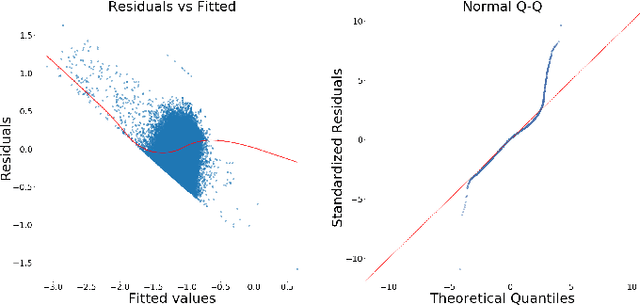
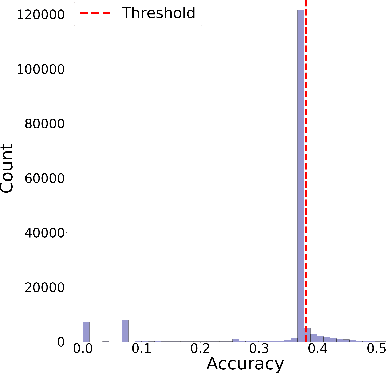
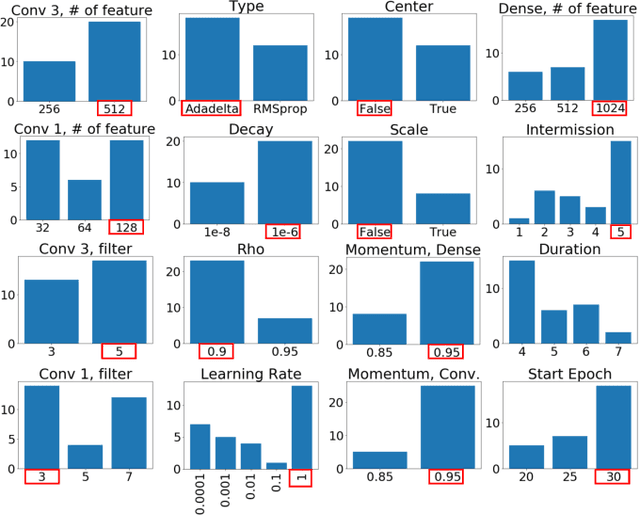
Convolutional Neural Networks (CNNs) have shown strong promise for analyzing scientific data from many domains including particle imaging detectors. However, the challenge of choosing the appropriate network architecture (depth, kernel shapes, activation functions, etc.) for specific applications and different data sets is still poorly understood. In this paper, we study the relationships between a CNN's architecture and its performance by proposing a systematic language that is useful for comparison between different CNN's architectures before training time. We characterize CNN's architecture by different attributes, and demonstrate that the attributes can be predictive of the networks' performance in two specific computer vision-based physics problems -- event vertex finding and hadron multiplicity classification in the MINERvA experiment at Fermi National Accelerator Laboratory. In doing so, we extract several architectural attributes from optimized networks' architecture for the physics problems, which are outputs of a model selection algorithm called Multi-node Evolutionary Neural Networks for Deep Learning (MENNDL). We use machine learning models to predict whether a network can perform better than a certain threshold accuracy before training. The models perform 16-20% better than random guessing. Additionally, we found an coefficient of determination of 0.966 for an Ordinary Least Squares model in a regression on accuracy over a large population of networks.
Exascale Deep Learning to Accelerate Cancer Research
Sep 26, 2019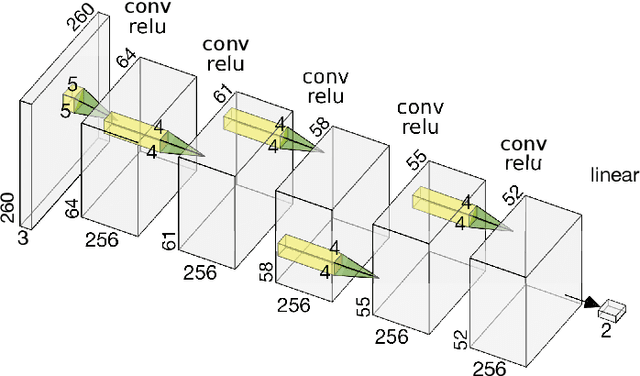
Deep learning, through the use of neural networks, has demonstrated remarkable ability to automate many routine tasks when presented with sufficient data for training. The neural network architecture (e.g. number of layers, types of layers, connections between layers, etc.) plays a critical role in determining what, if anything, the neural network is able to learn from the training data. The trend for neural network architectures, especially those trained on ImageNet, has been to grow ever deeper and more complex. The result has been ever increasing accuracy on benchmark datasets with the cost of increased computational demands. In this paper we demonstrate that neural network architectures can be automatically generated, tailored for a specific application, with dual objectives: accuracy of prediction and speed of prediction. Using MENNDL--an HPC-enabled software stack for neural architecture search--we generate a neural network with comparable accuracy to state-of-the-art networks on a cancer pathology dataset that is also $16\times$ faster at inference. The speedup in inference is necessary because of the volume and velocity of cancer pathology data; specifically, the previous state-of-the-art networks are too slow for individual researchers without access to HPC systems to keep pace with the rate of data generation. Our new model enables researchers with modest computational resources to analyze newly generated data faster than it is collected.
Deep Learning for Vertex Reconstruction of Neutrino-Nucleus Interaction Events with Combined Energy and Time Data
Feb 02, 2019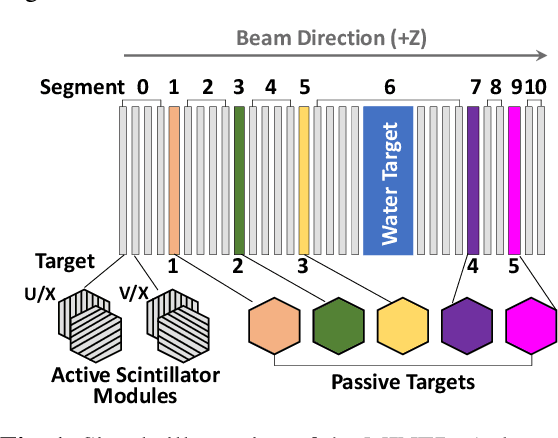
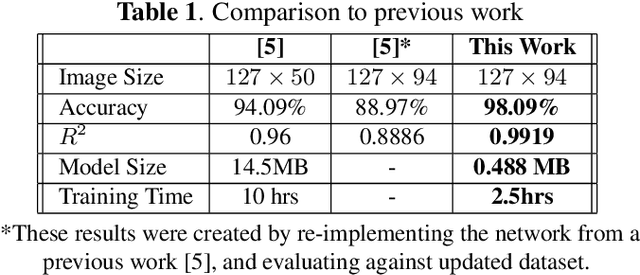
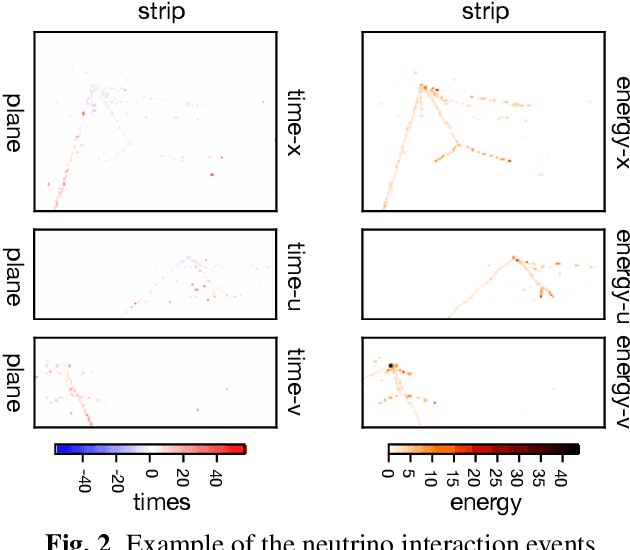
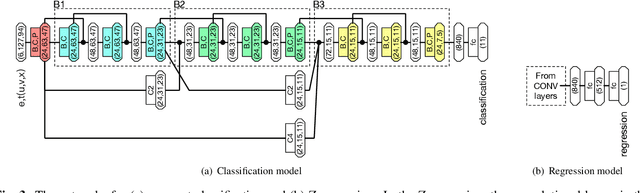
We present a deep learning approach for vertex reconstruction of neutrino-nucleus interaction events, a problem in the domain of high energy physics. In this approach, we combine both energy and timing data that are collected in the MINERvA detector to perform classification and regression tasks. We show that the resulting network achieves higher accuracy than previous results while requiring a smaller model size and less training time. In particular, the proposed model outperforms the state-of-the-art by 4.00% on classification accuracy. For the regression task, our model achieves 0.9919 on the coefficient of determination, higher than the previous work (0.96).
Unsupervised Identification of Study Descriptors in Toxicology Research: An Experimental Study
Nov 03, 2018
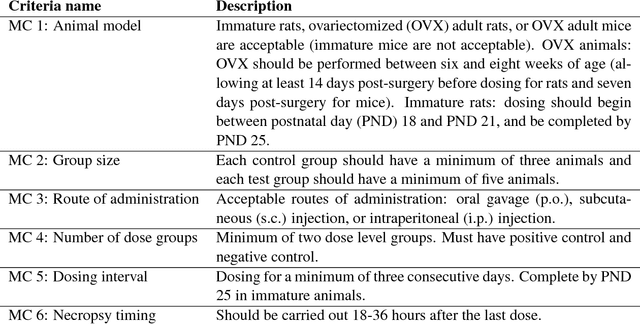
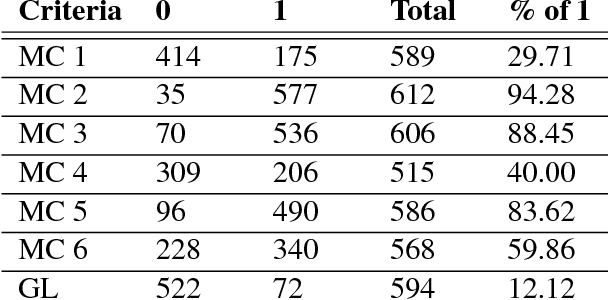
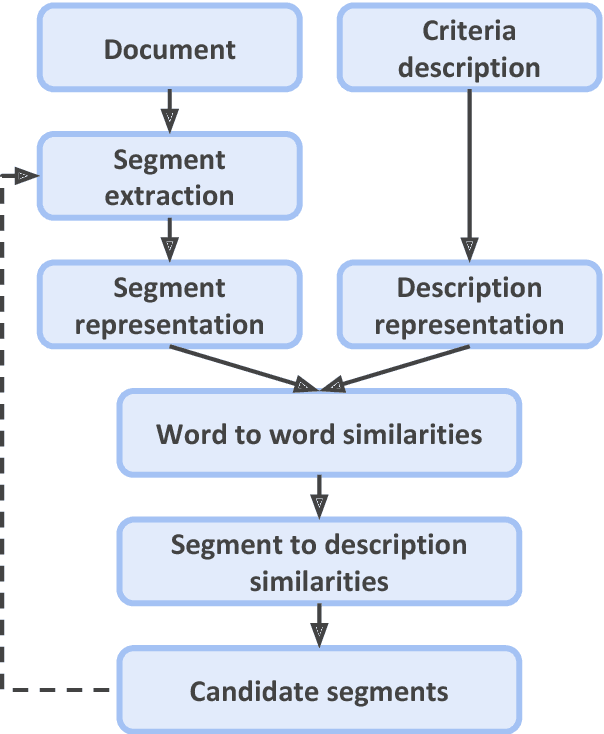
Identifying and extracting data elements such as study descriptors in publication full texts is a critical yet manual and labor-intensive step required in a number of tasks. In this paper we address the question of identifying data elements in an unsupervised manner. Specifically, provided a set of criteria describing specific study parameters, such as species, route of administration, and dosing regimen, we develop an unsupervised approach to identify text segments (sentences) relevant to the criteria. A binary classifier trained to identify publications that met the criteria performs better when trained on the candidate sentences than when trained on sentences randomly picked from the text, supporting the intuition that our method is able to accurately identify study descriptors.
A Study of Complex Deep Learning Networks on High Performance, Neuromorphic, and Quantum Computers
Jul 13, 2017
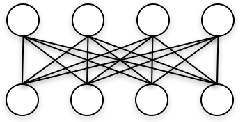
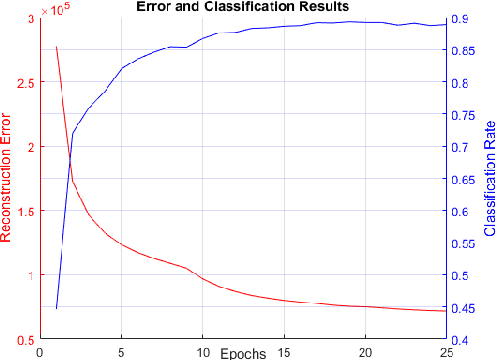
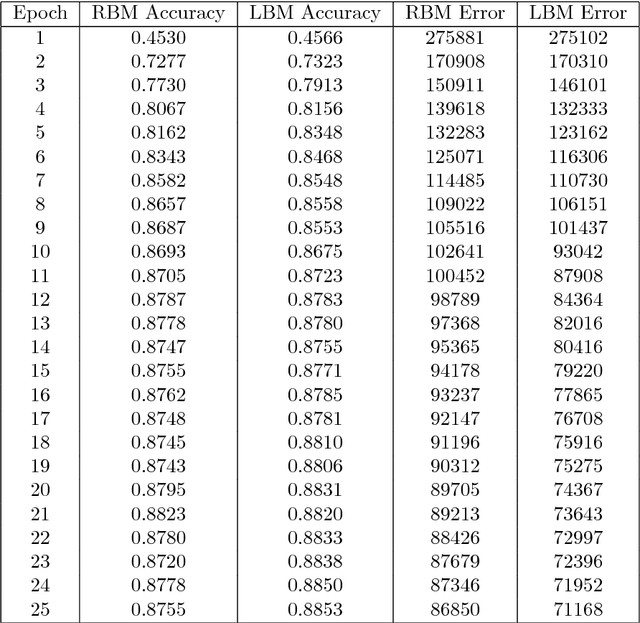
Current Deep Learning approaches have been very successful using convolutional neural networks (CNN) trained on large graphical processing units (GPU)-based computers. Three limitations of this approach are: 1) they are based on a simple layered network topology, i.e., highly connected layers, without intra-layer connections; 2) the networks are manually configured to achieve optimal results, and 3) the implementation of neuron model is expensive in both cost and power. In this paper, we evaluate deep learning models using three different computing architectures to address these problems: quantum computing to train complex topologies, high performance computing (HPC) to automatically determine network topology, and neuromorphic computing for a low-power hardware implementation. We use the MNIST dataset for our experiment, due to input size limitations of current quantum computers. Our results show the feasibility of using the three architectures in tandem to address the above deep learning limitations. We show a quantum computer can find high quality values of intra-layer connections weights, in a tractable time as the complexity of the network increases; a high performance computer can find optimal layer-based topologies; and a neuromorphic computer can represent the complex topology and weights derived from the other architectures in low power memristive hardware.
Recurrent Online Clustering as a Spatio-Temporal Feature Extractor in DeSTIN
Jan 16, 2013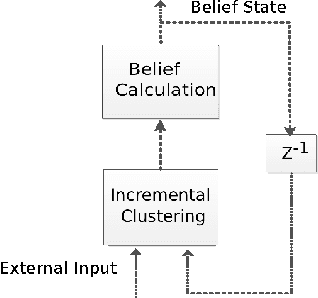
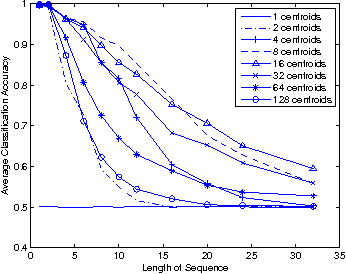
This paper presents a basic enhancement to the DeSTIN deep learning architecture by replacing the explicitly calculated transition tables that are used to capture temporal features with a simpler, more scalable mechanism. This mechanism uses feedback of state information to cluster over a space comprised of both the spatial input and the current state. The resulting architecture achieves state-of-the-art results on the MNIST classification benchmark.