 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023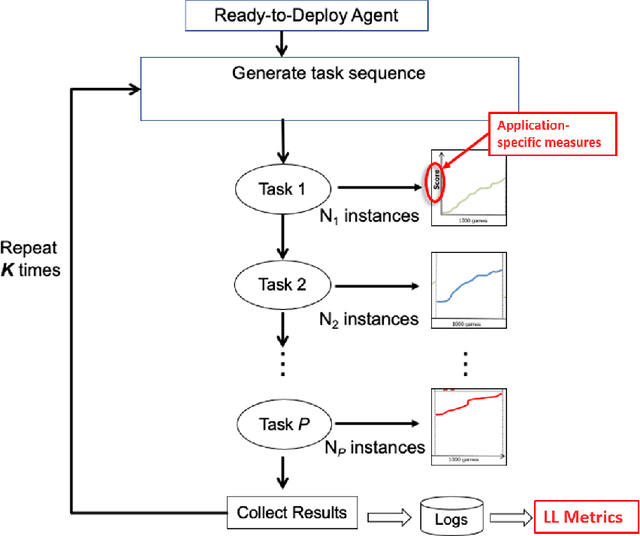


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Hyperparameter Optimization in Binary Communication Networks for Neuromorphic Deployment
Apr 21, 2020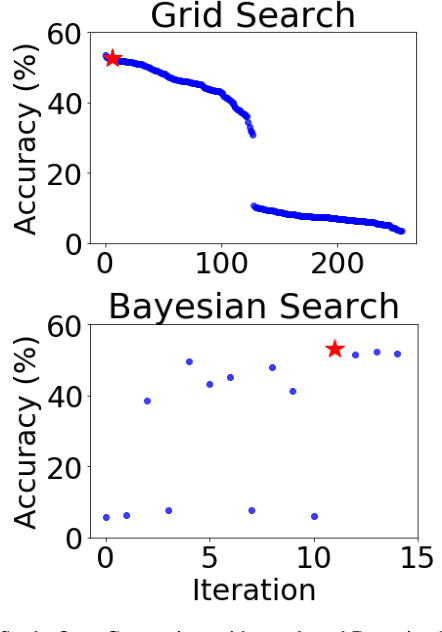
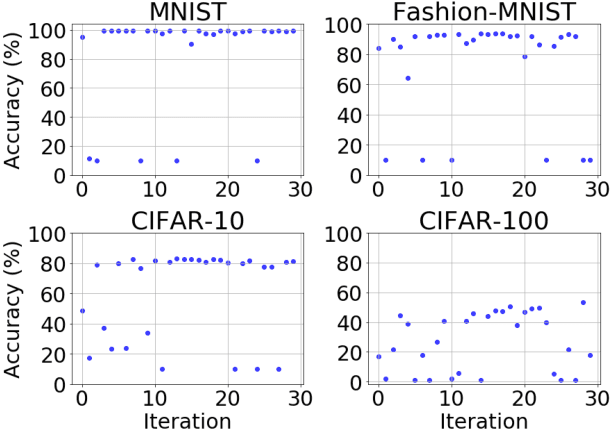
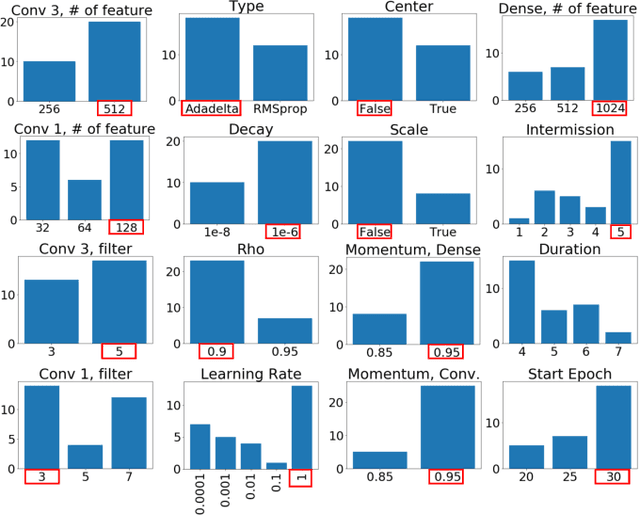

Training neural networks for neuromorphic deployment is non-trivial. There have been a variety of approaches proposed to adapt back-propagation or back-propagation-like algorithms appropriate for training. Considering that these networks often have very different performance characteristics than traditional neural networks, it is often unclear how to set either the network topology or the hyperparameters to achieve optimal performance. In this work, we introduce a Bayesian approach for optimizing the hyperparameters of an algorithm for training binary communication networks that can be deployed to neuromorphic hardware. We show that by optimizing the hyperparameters on this algorithm for each dataset, we can achieve improvements in accuracy over the previous state-of-the-art for this algorithm on each dataset (by up to 15 percent). This jump in performance continues to emphasize the potential when converting traditional neural networks to binary communication applicable to neuromorphic hardware.
Device-aware inference operations in SONOS nonvolatile memory arrays
Apr 02, 2020
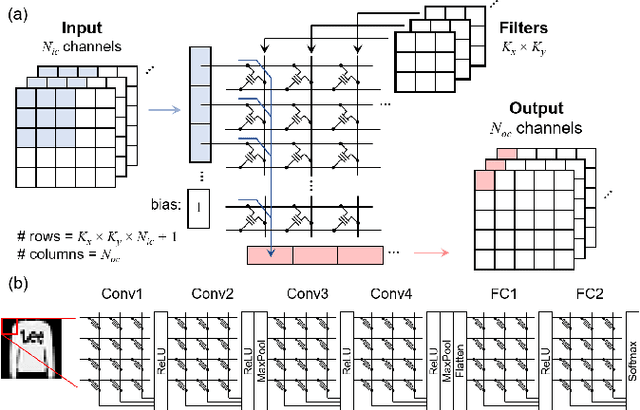


Non-volatile memory arrays can deploy pre-trained neural network models for edge inference. However, these systems are affected by device-level noise and retention issues. Here, we examine damage caused by these effects, introduce a mitigation strategy, and demonstrate its use in fabricated array of SONOS (Silicon-Oxide-Nitride-Oxide-Silicon) devices. On MNIST, fashion-MNIST, and CIFAR-10 tasks, our approach increases resilience to synaptic noise and drift. We also show strong performance can be realized with ADCs of 5-8 bits precision.
Evaluating complexity and resilience trade-offs in emerging memory inference machines
Feb 25, 2020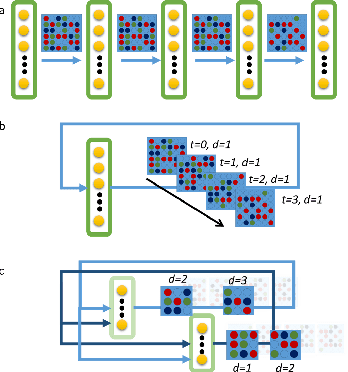
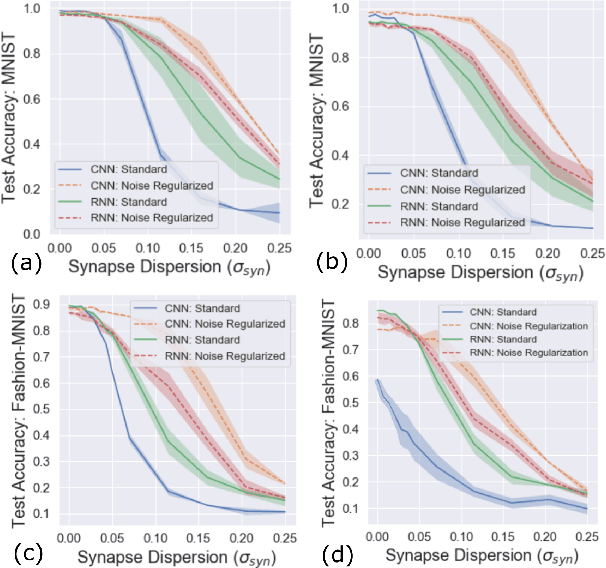
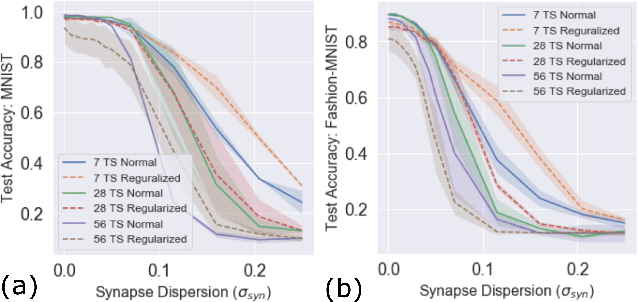
Neuromorphic-style inference only works well if limited hardware resources are maximized properly, e.g. accuracy continues to scale with parameters and complexity in the face of potential disturbance. In this work, we use realistic crossbar simulations to highlight that compact implementations of deep neural networks are unexpectedly susceptible to collapse from multiple system disturbances. Our work proposes a middle path towards high performance and strong resilience utilizing the Mosaics framework, and specifically by re-using synaptic connections in a recurrent neural network implementation that possesses a natural form of noise-immunity.
Whetstone: A Method for Training Deep Artificial Neural Networks for Binary Communication
Oct 26, 2018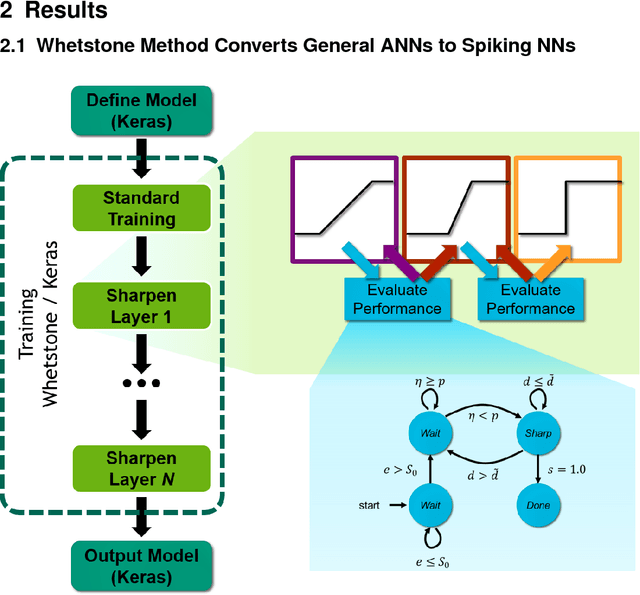
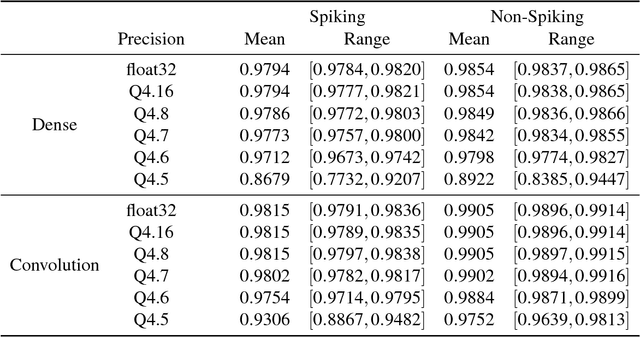
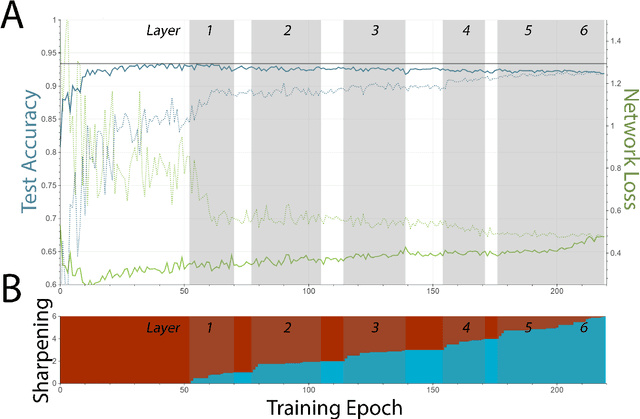

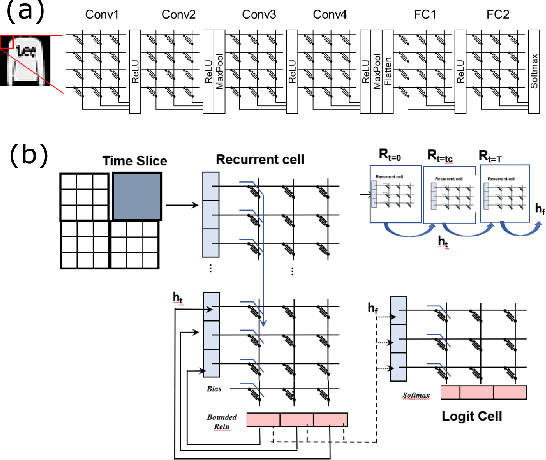
This paper presents a new technique for training networks for low-precision communication. Targeting minimal communication between nodes not only enables the use of emerging spiking neuromorphic platforms, but may additionally streamline processing conventionally. Low-power and embedded neuromorphic processors potentially offer dramatic performance-per-Watt improvements over traditional von Neumann processors, however programming these brain-inspired platforms generally requires platform-specific expertise which limits their applicability. To date, the majority of artificial neural networks have not operated using discrete spike-like communication. We present a method for training deep spiking neural networks using an iterative modification of the backpropagation optimization algorithm. This method, which we call Whetstone, effectively and reliably configures a network for a spiking hardware target with little, if any, loss in performance. Whetstone networks use single time step binary communication and do not require a rate code or other spike-based coding scheme, thus producing networks comparable in timing and size to conventional ANNs, albeit with binarized communication. We demonstrate Whetstone on a number of image classification networks, describing how the sharpening process interacts with different training optimizers and changes the distribution of activity within the network. We further note that Whetstone is compatible with several non-classification neural network applications, such as autoencoders and semantic segmentation. Whetstone is widely extendable and currently implemented using custom activation functions within the Keras wrapper to the popular TensorFlow machine learning framework.