 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalog fast Fourier transforms for scalable and efficient signal processing
Sep 27, 2024
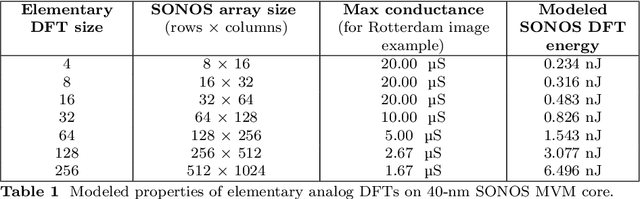


Edge devices are being deployed at increasing volumes to sense and act on information from the physical world. The discrete Fourier transform (DFT) is often necessary to make this sensed data suitable for further processing $\unicode{x2013}$ such as by artificial intelligence (AI) algorithms $\unicode{x2013}$ and for transmission over communication networks. Analog in-memory computing has been shown to be a fast and energy-efficient solution for processing edge AI workloads, but not for Fourier transforms. This is because of the existence of the fast Fourier transform (FFT) algorithm, which enormously reduces the complexity of the DFT but has so far belonged only to digital processors. Here, we show that the FFT can be mapped to analog in-memory computing systems, enabling them to efficiently scale to arbitrarily large Fourier transforms without requiring large sizes or large numbers of non-volatile memory arrays. We experimentally demonstrate analog FFTs on 1D audio and 2D image signals, using a large-scale charge-trapping memory array with precisely tunable, low-conductance analog states. The scalability of both the new analog FFT approach and the charge-trapping memory device is leveraged to compute a 65,536-point analog DFT, a scale that is otherwise inaccessible by analog systems and which is $>$1000$\times$ larger than any previous analog DFT demonstration. The analog FFT also provides more numerically precise DFTs with greater tolerance to device and circuit non-idealities than a direct matrix-vector multiplication approach. We show that the extension of the FFT algorithm to analog in-memory processors leads to design considerations that differ markedly from digital implementations, and that analog Fourier transforms have a substantial power efficiency advantage at all size scales over FFTs implemented on state-of-the-art digital hardware.
On the Accuracy of Analog Neural Network Inference Accelerators
Sep 12, 2021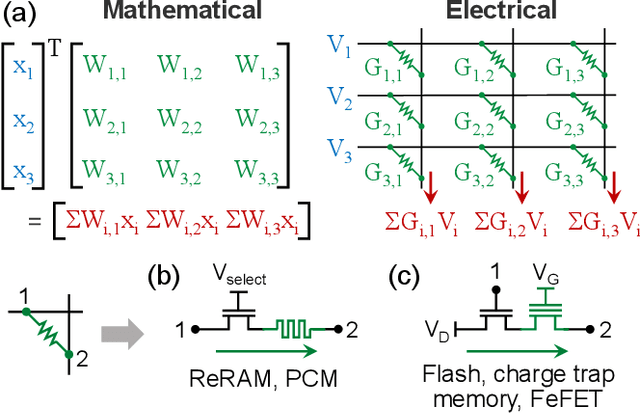
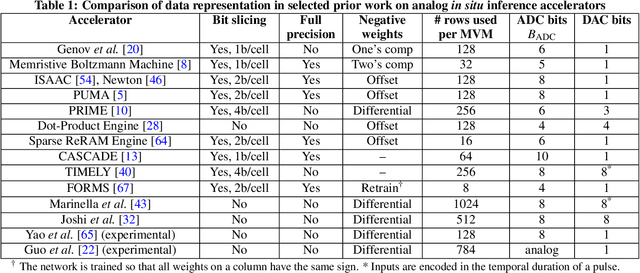
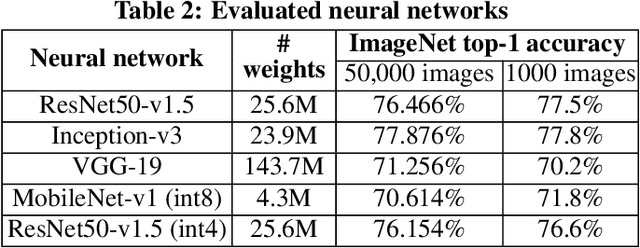
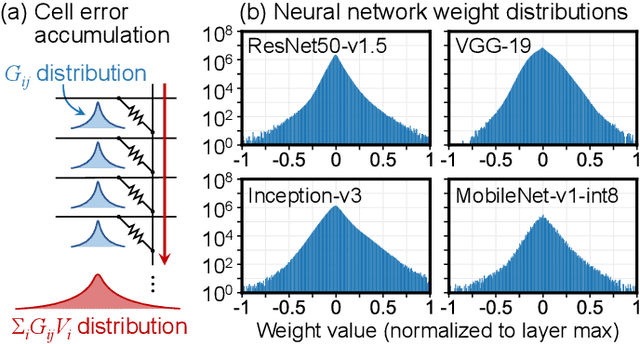
Specialized accelerators have recently garnered attention as a method to reduce the power consumption of neural network inference. A promising category of accelerators utilizes nonvolatile memory arrays to both store weights and perform $\textit{in situ}$ analog computation inside the array. While prior work has explored the design space of analog accelerators to optimize performance and energy efficiency, there is seldom a rigorous evaluation of the accuracy of these accelerators. This work shows how architectural design decisions, particularly in mapping neural network parameters to analog memory cells, influence inference accuracy. When evaluated using ResNet50 on ImageNet, the resilience of the system to analog non-idealities - cell programming errors, analog-to-digital converter resolution, and array parasitic resistances - all improve when analog quantities in the hardware are made proportional to the weights in the network. Moreover, contrary to the assumptions of prior work, nearly equivalent resilience to cell imprecision can be achieved by fully storing weights as analog quantities, rather than spreading weight bits across multiple devices, often referred to as bit slicing. By exploiting proportionality, analog system designers have the freedom to match the precision of the hardware to the needs of the algorithm, rather than attempting to guarantee the same level of precision in the intermediate results as an equivalent digital accelerator. This ultimately results in an analog accelerator that is more accurate, more robust to analog errors, and more energy-efficient.
Device-aware inference operations in SONOS nonvolatile memory arrays
Apr 02, 2020
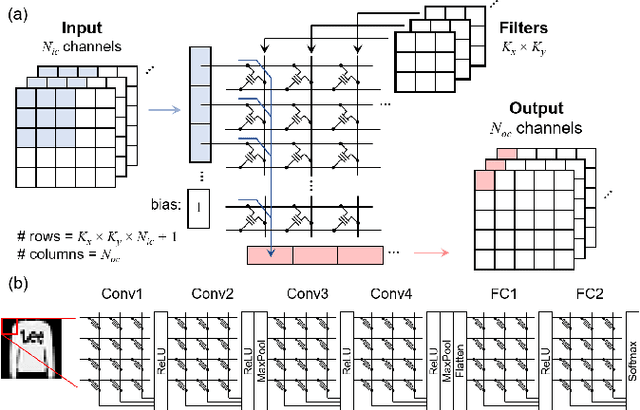


Non-volatile memory arrays can deploy pre-trained neural network models for edge inference. However, these systems are affected by device-level noise and retention issues. Here, we examine damage caused by these effects, introduce a mitigation strategy, and demonstrate its use in fabricated array of SONOS (Silicon-Oxide-Nitride-Oxide-Silicon) devices. On MNIST, fashion-MNIST, and CIFAR-10 tasks, our approach increases resilience to synaptic noise and drift. We also show strong performance can be realized with ADCs of 5-8 bits precision.
Evaluating complexity and resilience trade-offs in emerging memory inference machines
Feb 25, 2020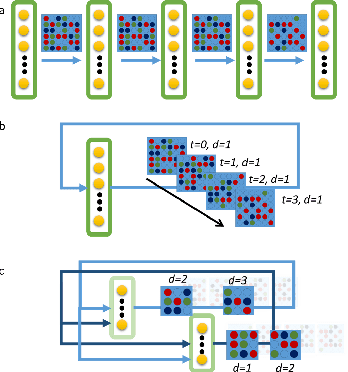
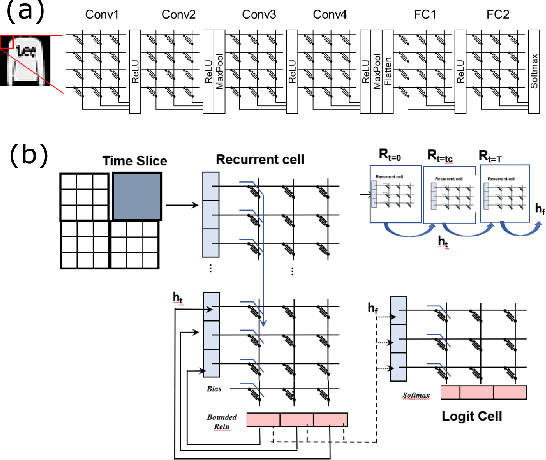
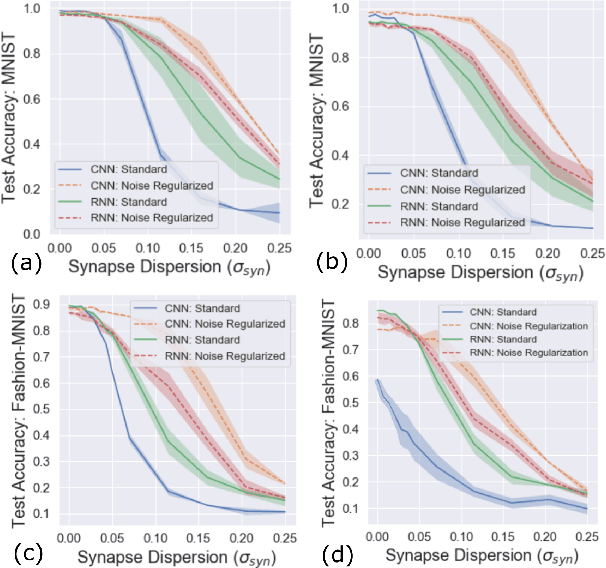
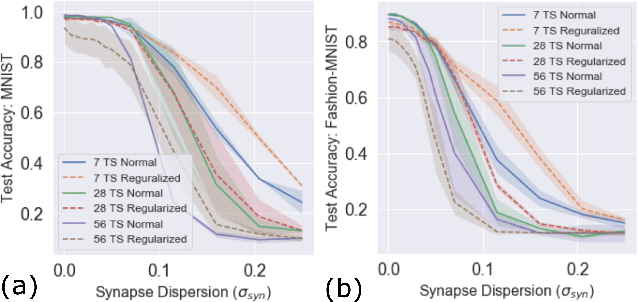
Neuromorphic-style inference only works well if limited hardware resources are maximized properly, e.g. accuracy continues to scale with parameters and complexity in the face of potential disturbance. In this work, we use realistic crossbar simulations to highlight that compact implementations of deep neural networks are unexpectedly susceptible to collapse from multiple system disturbances. Our work proposes a middle path towards high performance and strong resilience utilizing the Mosaics framework, and specifically by re-using synaptic connections in a recurrent neural network implementation that possesses a natural form of noise-immunity.