 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynaptic Sampling of Neural Networks
Nov 21, 2023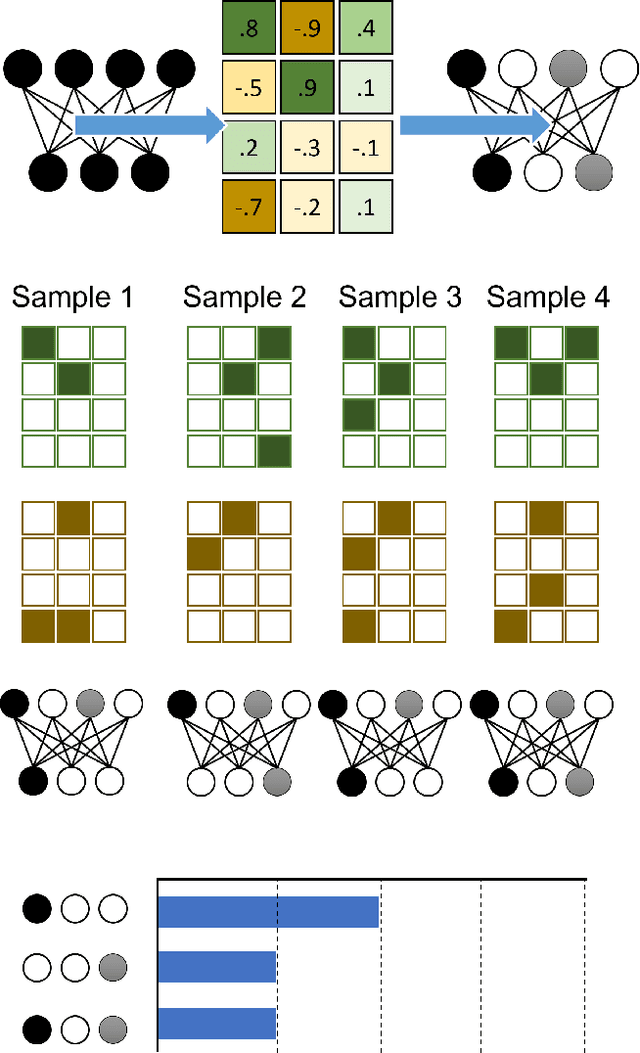
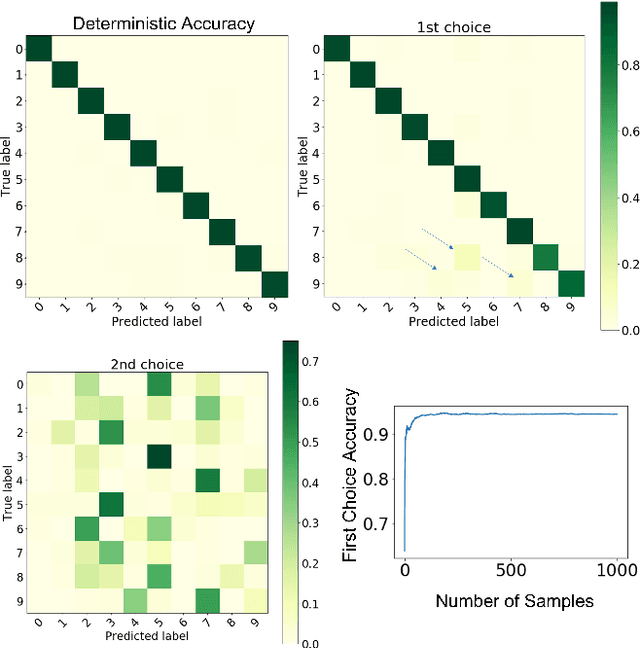
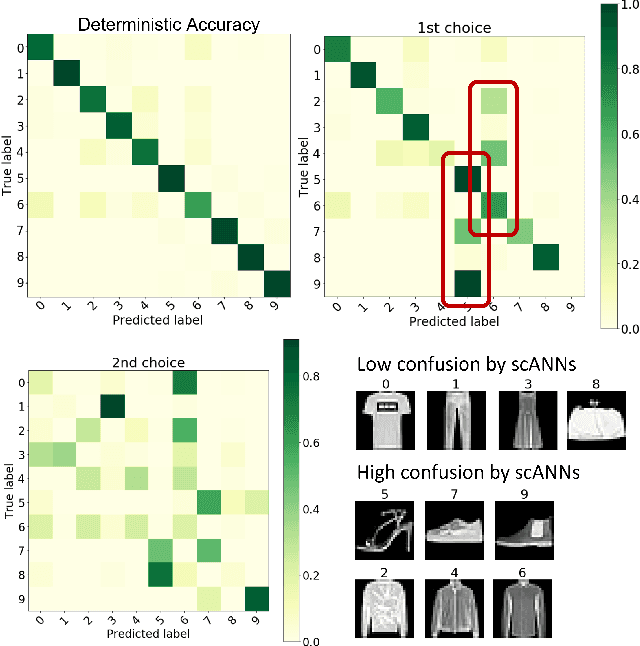
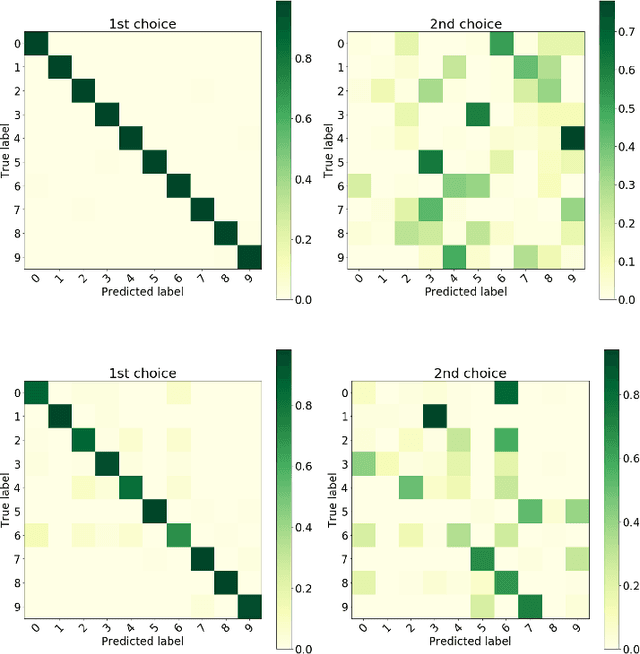
Probabilistic artificial neural networks offer intriguing prospects for enabling the uncertainty of artificial intelligence methods to be described explicitly in their function; however, the development of techniques that quantify uncertainty by well-understood methods such as Monte Carlo sampling has been limited by the high costs of stochastic sampling on deterministic computing hardware. Emerging computing systems that are amenable to hardware-level probabilistic computing, such as those that leverage stochastic devices, may make probabilistic neural networks more feasible in the not-too-distant future. This paper describes the scANN technique -- \textit{sampling (by coinflips) artificial neural networks} -- which enables neural networks to be sampled directly by treating the weights as Bernoulli coin flips. This method is natively well suited for probabilistic computing techniques that focus on tunable stochastic devices, nearly matches fully deterministic performance while also describing the uncertainty of correct and incorrect neural network outputs.
Stochastic Neuromorphic Circuits for Solving MAXCUT
Oct 05, 2022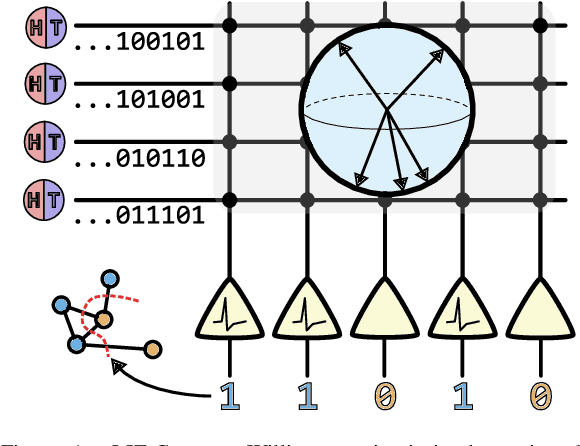
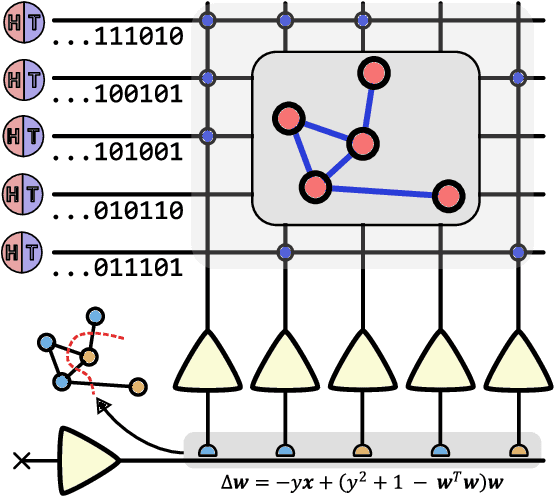
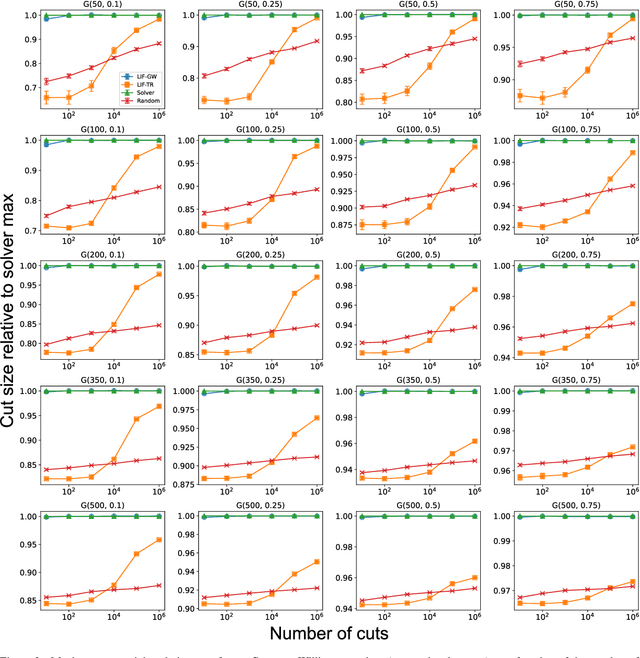
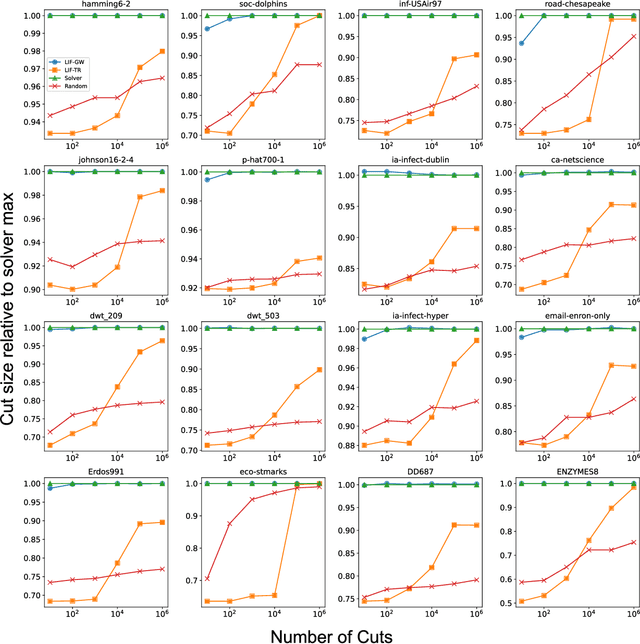
Finding the maximum cut of a graph (MAXCUT) is a classic optimization problem that has motivated parallel algorithm development. While approximate algorithms to MAXCUT offer attractive theoretical guarantees and demonstrate compelling empirical performance, such approximation approaches can shift the dominant computational cost to the stochastic sampling operations. Neuromorphic computing, which uses the organizing principles of the nervous system to inspire new parallel computing architectures, offers a possible solution. One ubiquitous feature of natural brains is stochasticity: the individual elements of biological neural networks possess an intrinsic randomness that serves as a resource enabling their unique computational capacities. By designing circuits and algorithms that make use of randomness similarly to natural brains, we hypothesize that the intrinsic randomness in microelectronics devices could be turned into a valuable component of a neuromorphic architecture enabling more efficient computations. Here, we present neuromorphic circuits that transform the stochastic behavior of a pool of random devices into useful correlations that drive stochastic solutions to MAXCUT. We show that these circuits perform favorably in comparison to software solvers and argue that this neuromorphic hardware implementation provides a path for scaling advantages. This work demonstrates the utility of combining neuromorphic principles with intrinsic randomness as a computational resource for new computational architectures.
Neuromorphic scaling advantages for energy-efficient random walk computation
Jul 27, 2021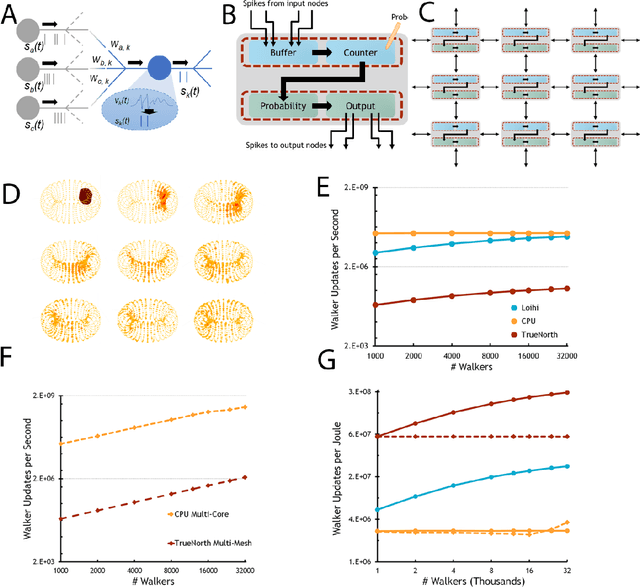


Computing stands to be radically improved by neuromorphic computing (NMC) approaches inspired by the brain's incredible efficiency and capabilities. Most NMC research, which aims to replicate the brain's computational structure and architecture in man-made hardware, has focused on artificial intelligence; however, less explored is whether this brain-inspired hardware can provide value beyond cognitive tasks. We demonstrate that high-degree parallelism and configurability of spiking neuromorphic architectures makes them well-suited to implement random walks via discrete time Markov chains. Such random walks are useful in Monte Carlo methods, which represent a fundamental computational tool for solving a wide range of numerical computing tasks. Additionally, we show how the mathematical basis for a probabilistic solution involving a class of stochastic differential equations can leverage those simulations to provide solutions for a range of broadly applicable computational tasks. Despite being in an early development stage, we find that NMC platforms, at a sufficient scale, can drastically reduce the energy demands of high-performance computing (HPC) platforms.
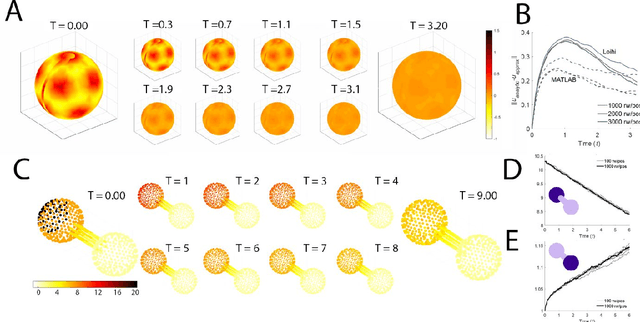
Solving a steady-state PDE using spiking networks and neuromorphic hardware
May 21, 2020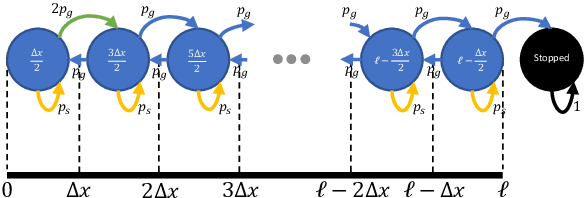
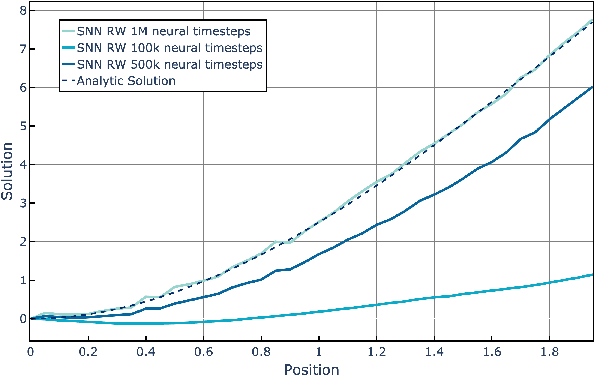
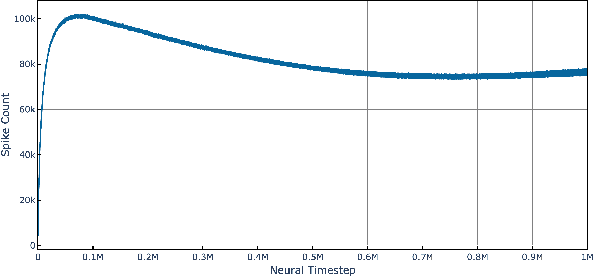
The widely parallel, spiking neural networks of neuromorphic processors can enable computationally powerful formulations. While recent interest has focused on primarily machine learning tasks, the space of appropriate applications is wide and continually expanding. Here, we leverage the parallel and event-driven structure to solve a steady state heat equation using a random walk method. The random walk can be executed fully within a spiking neural network using stochastic neuron behavior, and we provide results from both IBM TrueNorth and Intel Loihi implementations. Additionally, we position this algorithm as a potential scalable benchmark for neuromorphic systems.
Hyperparameter Optimization in Binary Communication Networks for Neuromorphic Deployment
Apr 21, 2020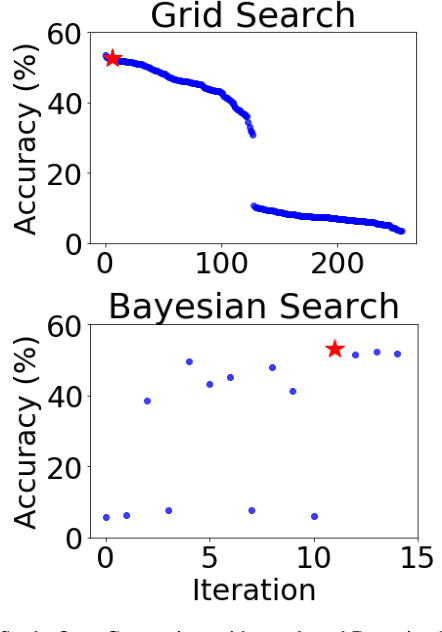
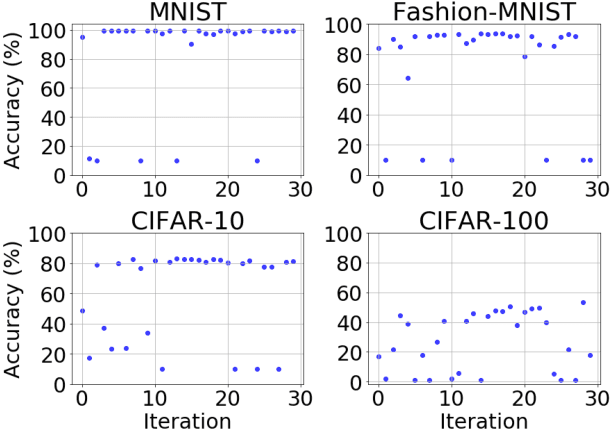
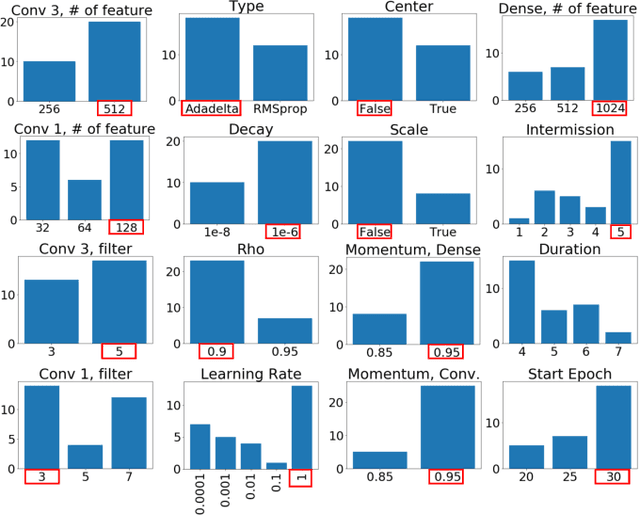

Training neural networks for neuromorphic deployment is non-trivial. There have been a variety of approaches proposed to adapt back-propagation or back-propagation-like algorithms appropriate for training. Considering that these networks often have very different performance characteristics than traditional neural networks, it is often unclear how to set either the network topology or the hyperparameters to achieve optimal performance. In this work, we introduce a Bayesian approach for optimizing the hyperparameters of an algorithm for training binary communication networks that can be deployed to neuromorphic hardware. We show that by optimizing the hyperparameters on this algorithm for each dataset, we can achieve improvements in accuracy over the previous state-of-the-art for this algorithm on each dataset (by up to 15 percent). This jump in performance continues to emphasize the potential when converting traditional neural networks to binary communication applicable to neuromorphic hardware.
Evaluating complexity and resilience trade-offs in emerging memory inference machines
Feb 25, 2020
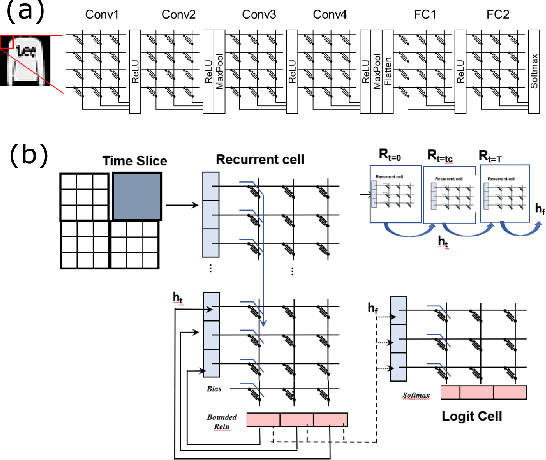
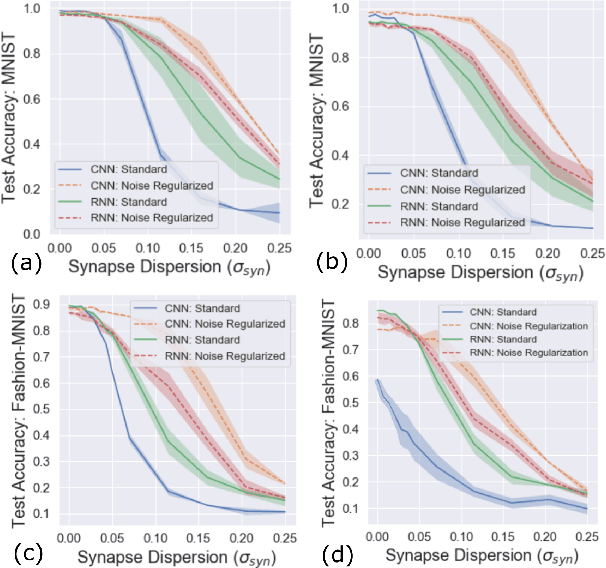
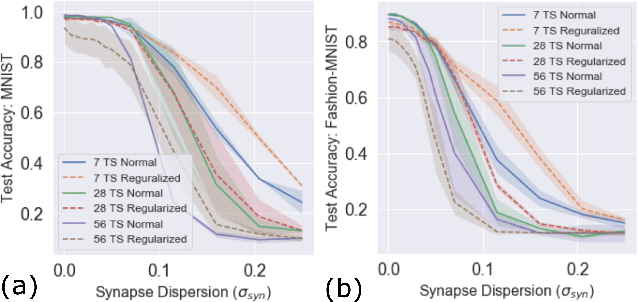
Neuromorphic-style inference only works well if limited hardware resources are maximized properly, e.g. accuracy continues to scale with parameters and complexity in the face of potential disturbance. In this work, we use realistic crossbar simulations to highlight that compact implementations of deep neural networks are unexpectedly susceptible to collapse from multiple system disturbances. Our work proposes a middle path towards high performance and strong resilience utilizing the Mosaics framework, and specifically by re-using synaptic connections in a recurrent neural network implementation that possesses a natural form of noise-immunity.
Composing Neural Algorithms with Fugu
May 28, 2019

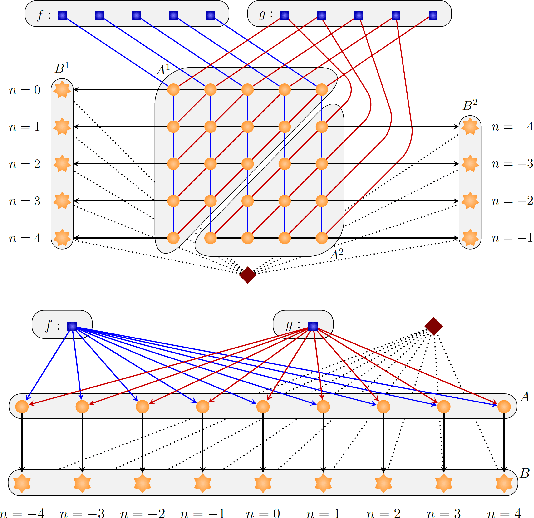
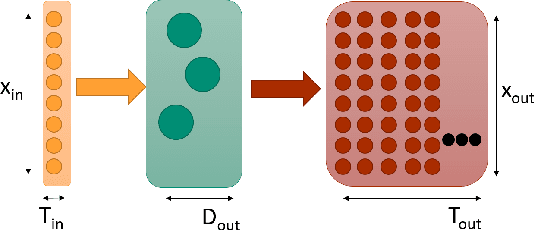
Neuromorphic hardware architectures represent a growing family of potential post-Moore's Law Era platforms. Largely due to event-driving processing inspired by the human brain, these computer platforms can offer significant energy benefits compared to traditional von Neumann processors. Unfortunately there still remains considerable difficulty in successfully programming, configuring and deploying neuromorphic systems. We present the Fugu framework as an answer to this need. Rather than necessitating a developer attain intricate knowledge of how to program and exploit spiking neural dynamics to utilize the potential benefits of neuromorphic computing, Fugu is designed to provide a higher level abstraction as a hardware-independent mechanism for linking a variety of scalable spiking neural algorithms from a variety of sources. Individual kernels linked together provide sophisticated processing through compositionality. Fugu is intended to be suitable for a wide-range of neuromorphic applications, including machine learning, scientific computing, and more brain-inspired neural algorithms. Ultimately, we hope the community adopts this and other open standardization attempts allowing for free exchange and easy implementations of the ever-growing list of spiking neural algorithms.
Making BREAD: Biomimetic strategies for Artificial Intelligence Now and in the Future
Dec 04, 2018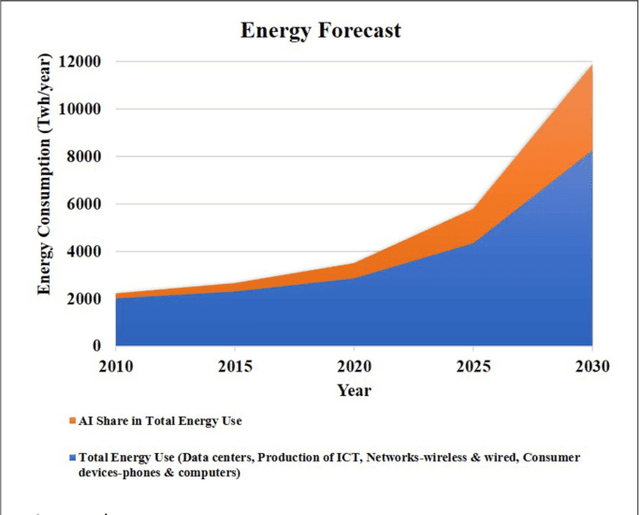
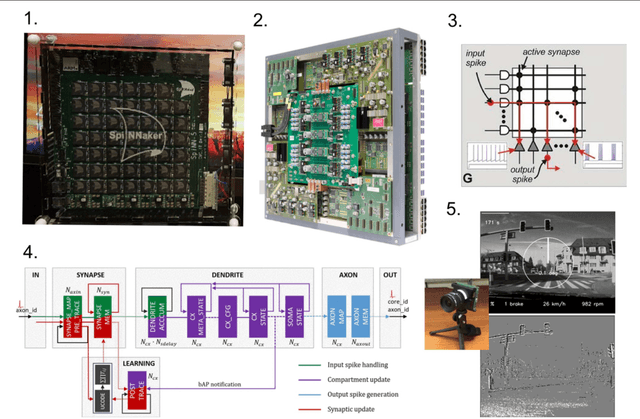
The Artificial Intelligence (AI) revolution foretold of during the 1960s is well underway in the second decade of the 21st century. Its period of phenomenal growth likely lies ahead. Still, we believe, there are crucial lessons that biology can offer that will enable a prosperous future for AI. For machines in general, and for AI's especially, operating over extended periods or in extreme environments will require energy usage orders of magnitudes more efficient than exists today. In many operational environments, energy sources will be constrained. Any plans for AI devices operating in a challenging environment must begin with the question of how they are powered, where fuel is located, how energy is stored and made available to the machine, and how long the machine can operate on specific energy units. Hence, the materials and technologies that provide the needed energy represent a critical challenge towards future use-scenarios of AI and should be integrated into their design. Here we make four recommendations for stakeholders and especially decision makers to facilitate a successful trajectory for this technology. First, that scientific societies and governments coordinate Biomimetic Research for Energy-efficient, AI Designs (BREAD); a multinational initiative and a funding strategy for investments in the future integrated design of energetics into AI. Second, that biomimetic energetic solutions be central to design consideration for future AI. Third, that a pre-competitive space be organized between stakeholder partners and fourth, that a trainee pipeline be established to ensure the human capital required for success in this area.
Whetstone: A Method for Training Deep Artificial Neural Networks for Binary Communication
Oct 26, 2018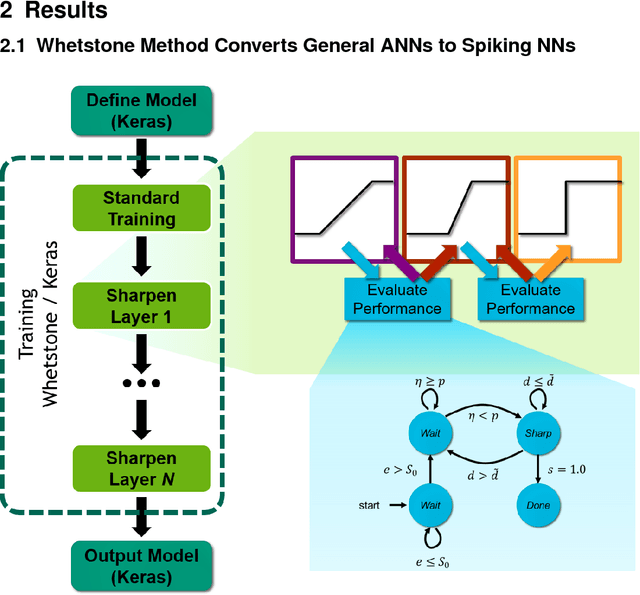
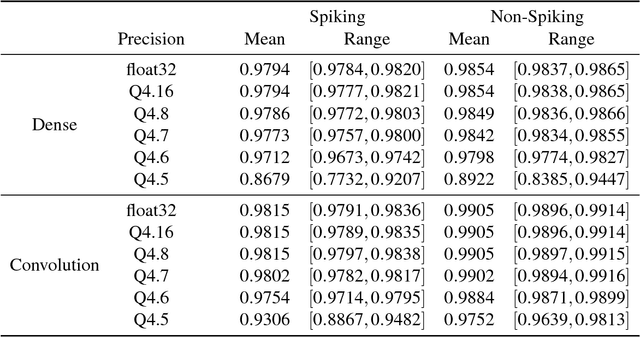
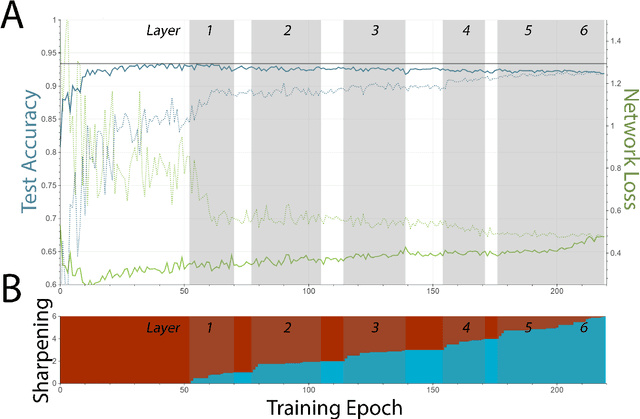

This paper presents a new technique for training networks for low-precision communication. Targeting minimal communication between nodes not only enables the use of emerging spiking neuromorphic platforms, but may additionally streamline processing conventionally. Low-power and embedded neuromorphic processors potentially offer dramatic performance-per-Watt improvements over traditional von Neumann processors, however programming these brain-inspired platforms generally requires platform-specific expertise which limits their applicability. To date, the majority of artificial neural networks have not operated using discrete spike-like communication. We present a method for training deep spiking neural networks using an iterative modification of the backpropagation optimization algorithm. This method, which we call Whetstone, effectively and reliably configures a network for a spiking hardware target with little, if any, loss in performance. Whetstone networks use single time step binary communication and do not require a rate code or other spike-based coding scheme, thus producing networks comparable in timing and size to conventional ANNs, albeit with binarized communication. We demonstrate Whetstone on a number of image classification networks, describing how the sharpening process interacts with different training optimizers and changes the distribution of activity within the network. We further note that Whetstone is compatible with several non-classification neural network applications, such as autoencoders and semantic segmentation. Whetstone is widely extendable and currently implemented using custom activation functions within the Keras wrapper to the popular TensorFlow machine learning framework.
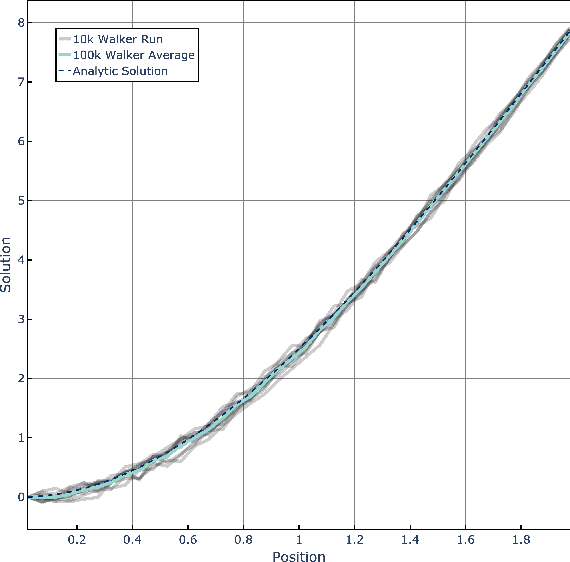
Spiking Neural Algorithms for Markov Process Random Walk
May 01, 2018
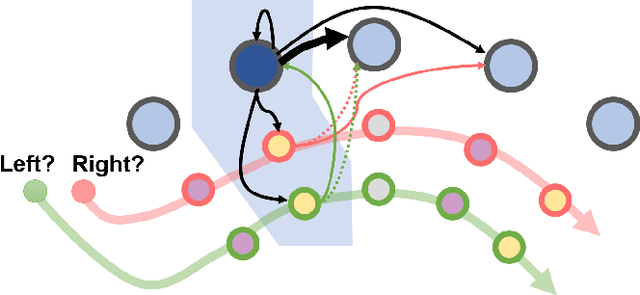
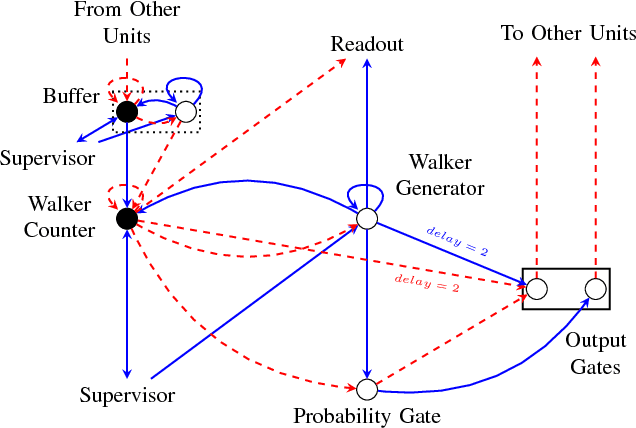

The random walk is a fundamental stochastic process that underlies many numerical tasks in scientific computing applications. We consider here two neural algorithms that can be used to efficiently implement random walks on spiking neuromorphic hardware. The first method tracks the positions of individual walkers independently by using a modular code inspired by the grid cell spatial representation in the brain. The second method tracks the densities of random walkers at each spatial location directly. We analyze the scaling complexity of each of these methods and illustrate their ability to model random walkers under different probabilistic conditions.