 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Neuromorphic Circuits for Solving MAXCUT
Oct 05, 2022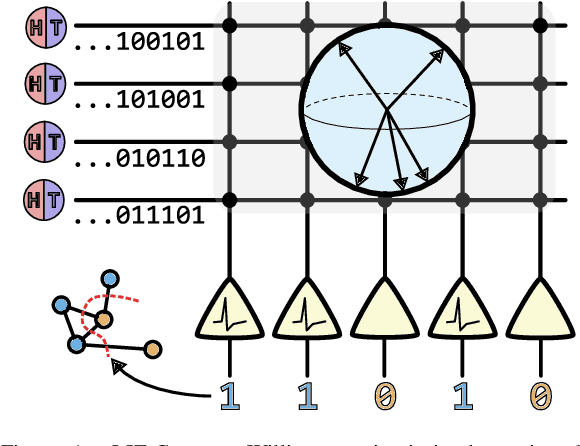
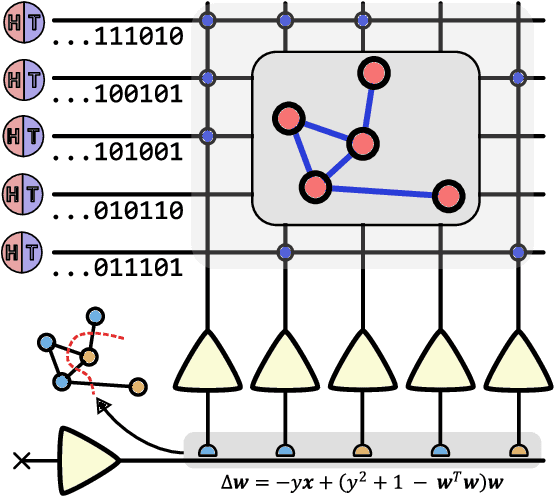
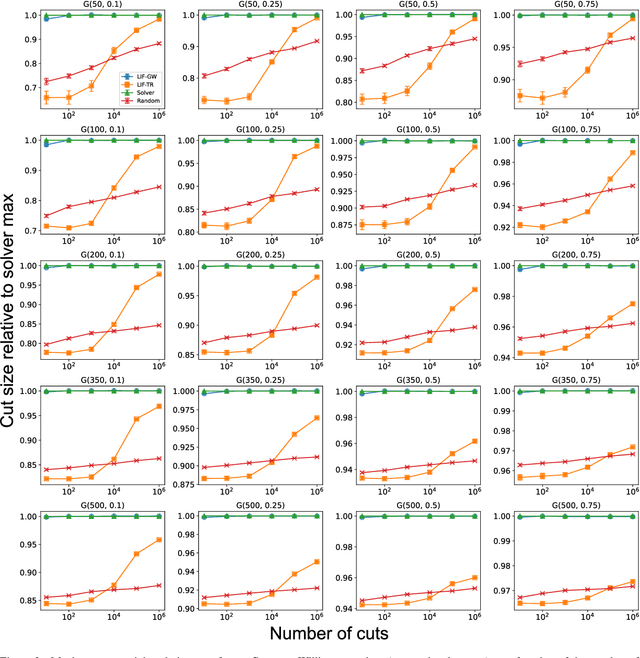
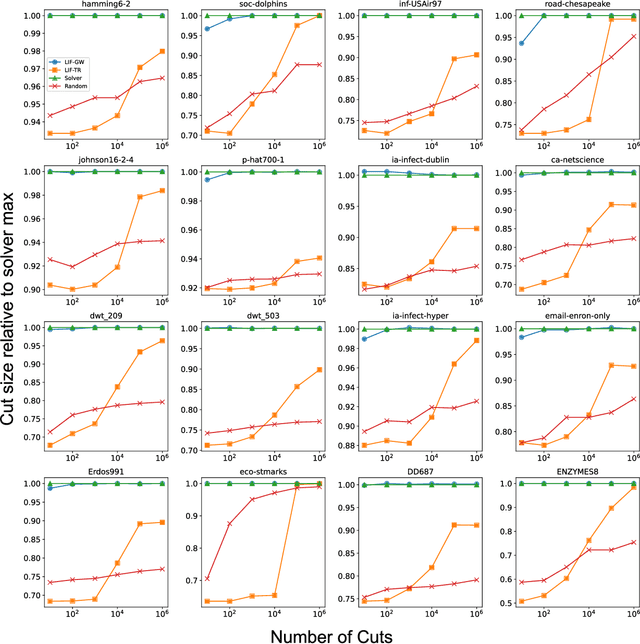
Finding the maximum cut of a graph (MAXCUT) is a classic optimization problem that has motivated parallel algorithm development. While approximate algorithms to MAXCUT offer attractive theoretical guarantees and demonstrate compelling empirical performance, such approximation approaches can shift the dominant computational cost to the stochastic sampling operations. Neuromorphic computing, which uses the organizing principles of the nervous system to inspire new parallel computing architectures, offers a possible solution. One ubiquitous feature of natural brains is stochasticity: the individual elements of biological neural networks possess an intrinsic randomness that serves as a resource enabling their unique computational capacities. By designing circuits and algorithms that make use of randomness similarly to natural brains, we hypothesize that the intrinsic randomness in microelectronics devices could be turned into a valuable component of a neuromorphic architecture enabling more efficient computations. Here, we present neuromorphic circuits that transform the stochastic behavior of a pool of random devices into useful correlations that drive stochastic solutions to MAXCUT. We show that these circuits perform favorably in comparison to software solvers and argue that this neuromorphic hardware implementation provides a path for scaling advantages. This work demonstrates the utility of combining neuromorphic principles with intrinsic randomness as a computational resource for new computational architectures.
Solving a steady-state PDE using spiking networks and neuromorphic hardware
May 21, 2020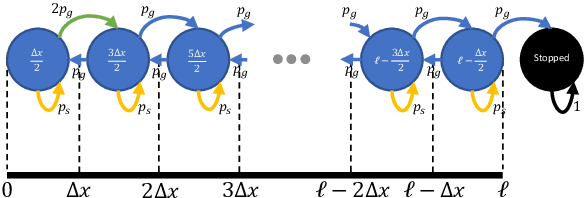
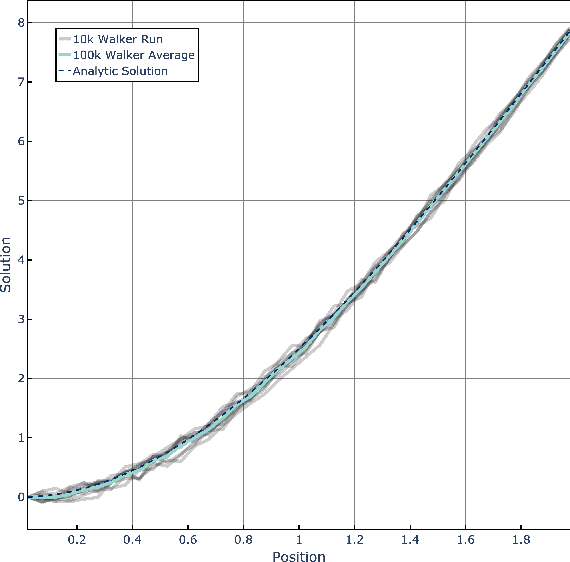
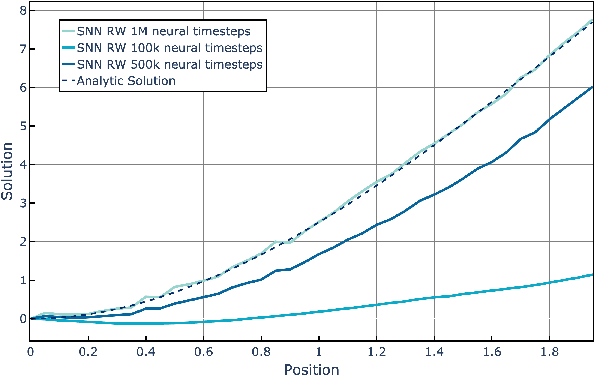
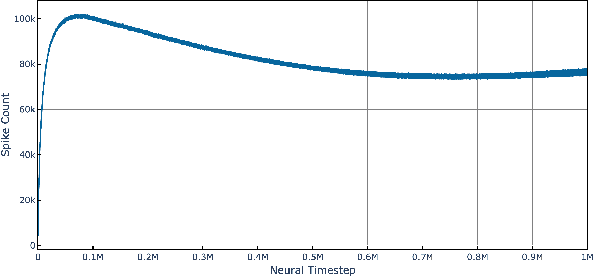
The widely parallel, spiking neural networks of neuromorphic processors can enable computationally powerful formulations. While recent interest has focused on primarily machine learning tasks, the space of appropriate applications is wide and continually expanding. Here, we leverage the parallel and event-driven structure to solve a steady state heat equation using a random walk method. The random walk can be executed fully within a spiking neural network using stochastic neuron behavior, and we provide results from both IBM TrueNorth and Intel Loihi implementations. Additionally, we position this algorithm as a potential scalable benchmark for neuromorphic systems.