 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Co-Design as a Game
Dec 11, 2023Co-design is a prominent topic presently in computing, speaking to the mutual benefit of coordinating design choices of several layers in the technology stack. For example, this may be designing algorithms which can most efficiently take advantage of the acceleration properties of a given architecture, while simultaneously designing the hardware to support the structural needs of a class of computation. The implications of these design decisions are influential enough to be deemed a lottery, enabling an idea to win out over others irrespective of the individual merits. Coordination is a well studied topic in the mathematics of game theory, where in many cases without a coordination mechanism the outcome is sub-optimal. Here we consider what insights game theoretic analysis can offer for computer architecture co-design. In particular, we consider the interplay between algorithm and architecture advances in the field of neuromorphic computing. Analyzing developments of spiking neural network algorithms and neuromorphic hardware as a co-design game we use the Stag Hunt model to illustrate challenges for spiking algorithms or architectures to advance the field independently and advocate for a strategic pursuit to advance neuromorphic computing.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Spiking Neural Streaming Binary Arithmetic
Mar 23, 2022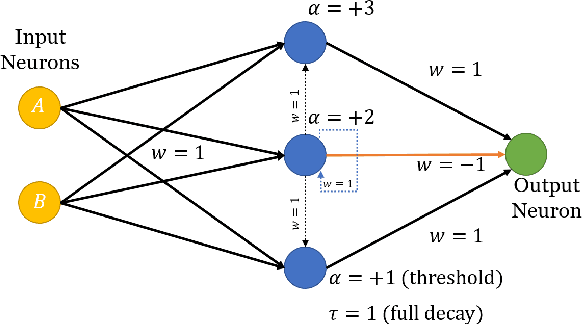
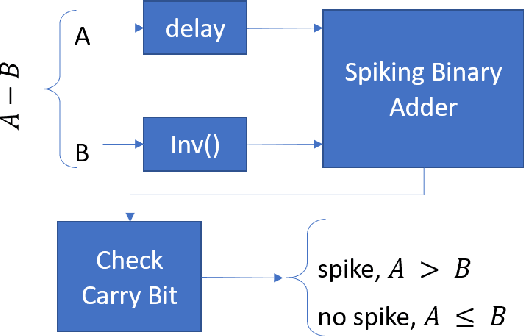
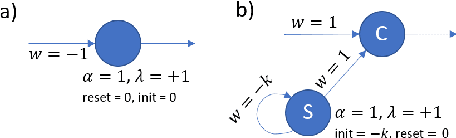

Boolean functions and binary arithmetic operations are central to standard computing paradigms. Accordingly, many advances in computing have focused upon how to make these operations more efficient as well as exploring what they can compute. To best leverage the advantages of novel computing paradigms it is important to consider what unique computing approaches they offer. However, for any special-purpose co-processor, Boolean functions and binary arithmetic operations are useful for, among other things, avoiding unnecessary I/O on-and-off the co-processor by pre- and post-processing data on-device. This is especially true for spiking neuromorphic architectures where these basic operations are not fundamental low-level operations. Instead, these functions require specific implementation. Here we discuss the implications of an advantageous streaming binary encoding method as well as a handful of circuits designed to exactly compute elementary Boolean and binary operations.
RAPDARTS: Resource-Aware Progressive Differentiable Architecture Search
Nov 08, 2019
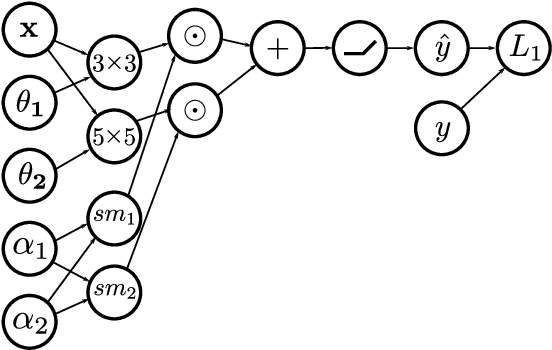

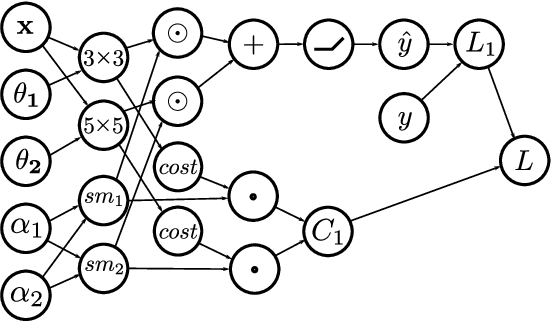
Early neural network architectures were designed by so-called "grad student descent". Since then, the field of Neural Architecture Search (NAS) has developed with the goal of algorithmically designing architectures tailored for a dataset of interest. Recently, gradient-based NAS approaches have been created to rapidly perform the search. Gradient-based approaches impose more structure on the search, compared to alternative NAS methods, enabling faster search phase optimization. In the real-world, neural architecture performance is measured by more than just high accuracy. There is increasing need for efficient neural architectures, where resources such as model size or latency must also be considered. Gradient-based NAS is also suitable for such multi-objective optimization. In this work we extend a popular gradient-based NAS method to support one or more resource costs. We then perform in-depth analysis on the discovery of architectures satisfying single-resource constraints for classification of CIFAR-10.
Distillation Strategies for Proximal Policy Optimization
Jan 23, 2019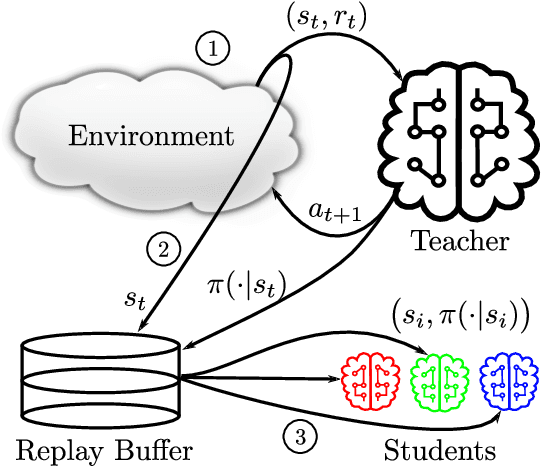
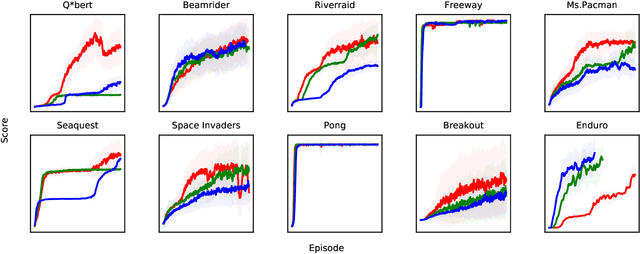
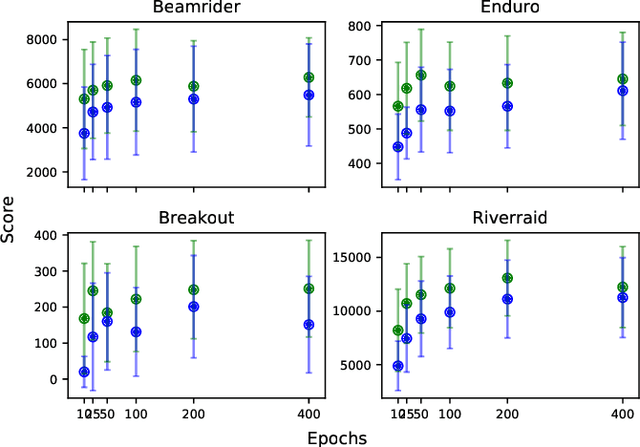
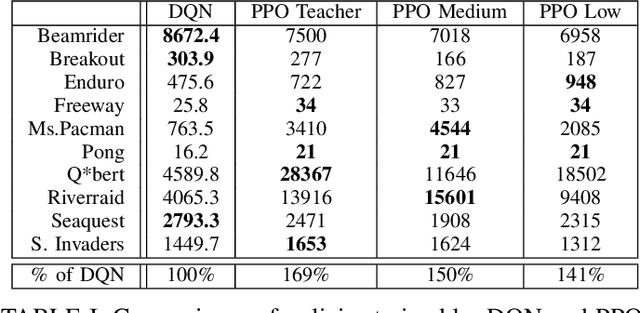
Vision-based deep reinforcement learning (RL), similar to deep learning, typically obtains a performance benefit by using high capacity and relatively large convolutional neural networks (CNN). However, a large network leads to higher inference costs (power, latency, silicon area, MAC count). Many inference optimization have been developed for CNNs. Some optimization techniques offer theoretical efficiency, but designing actual hardware to support them is difficult. On the other hand, "distillation" is a simple general-purpose optimization technique which is broadly applicable for transferring knowledge from a trained, high capacity, teacher network to an untrained, low capacity, student network. "DQN distillation" extended the original distillation idea to transfer information stored in a high performance, high capacity teacher Q-function trained via the Deep Q-Learning (DQN) algorithm. Our work adapts the DQN distillation work to the actor-critic Proximal Policy Optimization algorithm. PPO is simple to implement and has much higher performance than the seminal DQN algorithm. We show that a distilled PPO student can attain far higher performance compared to a DQN teacher. We also show that a low capacity distilled student is generally able to outperform a low capacity agent that directly trains in the environment. Finally, we show that distillation, followed by "fine-tuning" in the environment, enables the distilled PPO student to achieve parity with teacher performance. In general, the lessons learned in this work should transfer to other actor-critic RL algorithms.
Whetstone: A Method for Training Deep Artificial Neural Networks for Binary Communication
Oct 26, 2018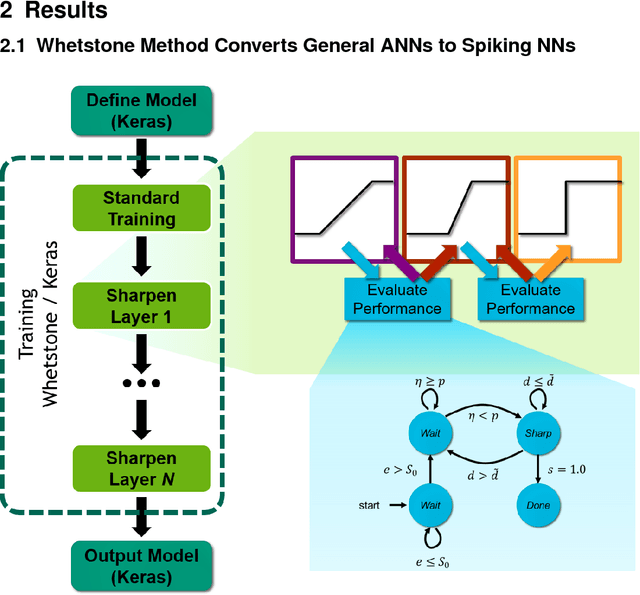
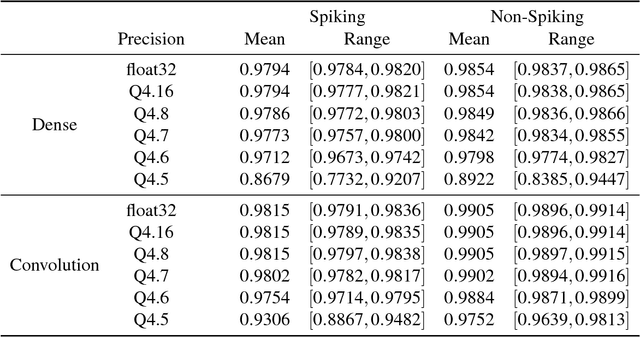
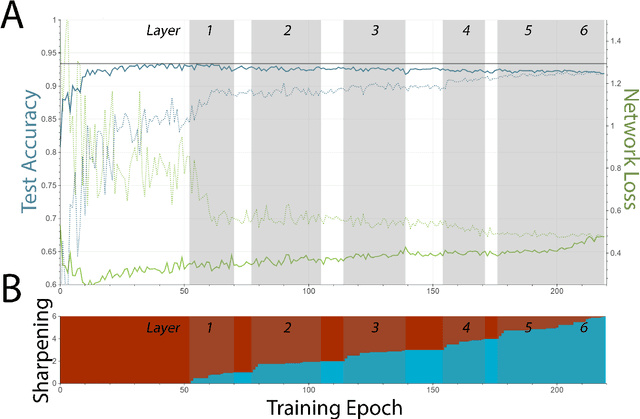

This paper presents a new technique for training networks for low-precision communication. Targeting minimal communication between nodes not only enables the use of emerging spiking neuromorphic platforms, but may additionally streamline processing conventionally. Low-power and embedded neuromorphic processors potentially offer dramatic performance-per-Watt improvements over traditional von Neumann processors, however programming these brain-inspired platforms generally requires platform-specific expertise which limits their applicability. To date, the majority of artificial neural networks have not operated using discrete spike-like communication. We present a method for training deep spiking neural networks using an iterative modification of the backpropagation optimization algorithm. This method, which we call Whetstone, effectively and reliably configures a network for a spiking hardware target with little, if any, loss in performance. Whetstone networks use single time step binary communication and do not require a rate code or other spike-based coding scheme, thus producing networks comparable in timing and size to conventional ANNs, albeit with binarized communication. We demonstrate Whetstone on a number of image classification networks, describing how the sharpening process interacts with different training optimizers and changes the distribution of activity within the network. We further note that Whetstone is compatible with several non-classification neural network applications, such as autoencoders and semantic segmentation. Whetstone is widely extendable and currently implemented using custom activation functions within the Keras wrapper to the popular TensorFlow machine learning framework.
Neurogenesis Deep Learning
Mar 28, 2017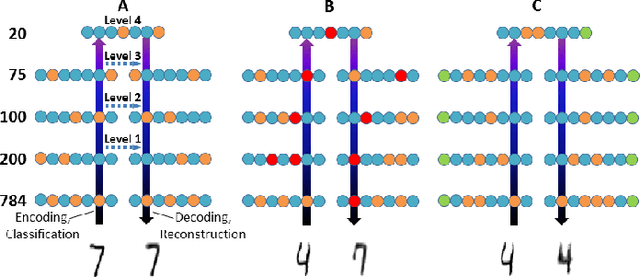
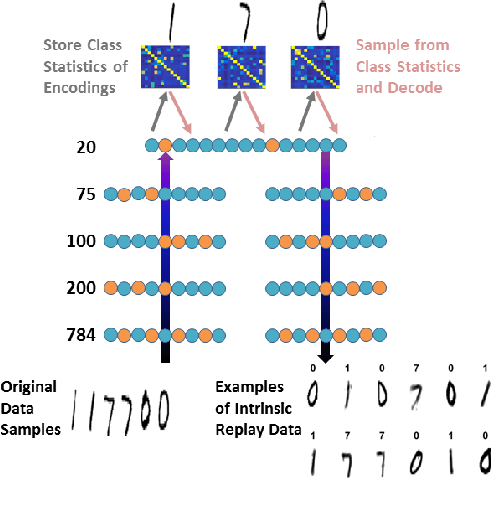

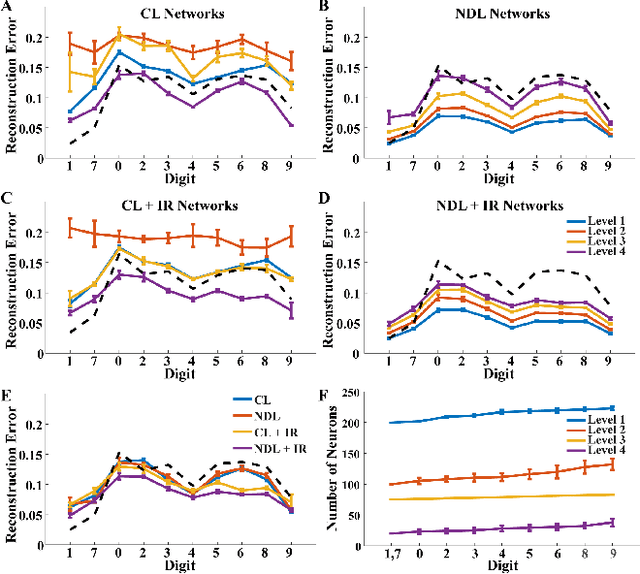
Neural machine learning methods, such as deep neural networks (DNN), have achieved remarkable success in a number of complex data processing tasks. These methods have arguably had their strongest impact on tasks such as image and audio processing - data processing domains in which humans have long held clear advantages over conventional algorithms. In contrast to biological neural systems, which are capable of learning continuously, deep artificial networks have a limited ability for incorporating new information in an already trained network. As a result, methods for continuous learning are potentially highly impactful in enabling the application of deep networks to dynamic data sets. Here, inspired by the process of adult neurogenesis in the hippocampus, we explore the potential for adding new neurons to deep layers of artificial neural networks in order to facilitate their acquisition of novel information while preserving previously trained data representations. Our results on the MNIST handwritten digit dataset and the NIST SD 19 dataset, which includes lower and upper case letters and digits, demonstrate that neurogenesis is well suited for addressing the stability-plasticity dilemma that has long challenged adaptive machine learning algorithms.
A Digital Neuromorphic Architecture Efficiently Facilitating Complex Synaptic Response Functions Applied to Liquid State Machines
Mar 21, 2017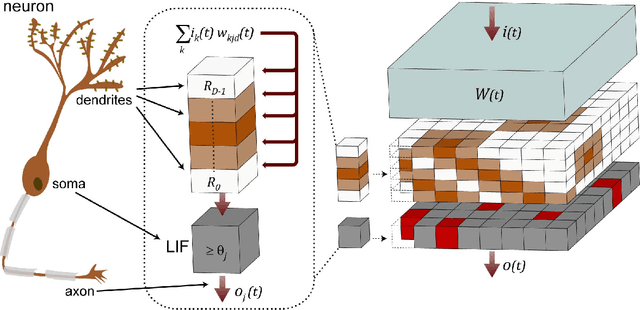
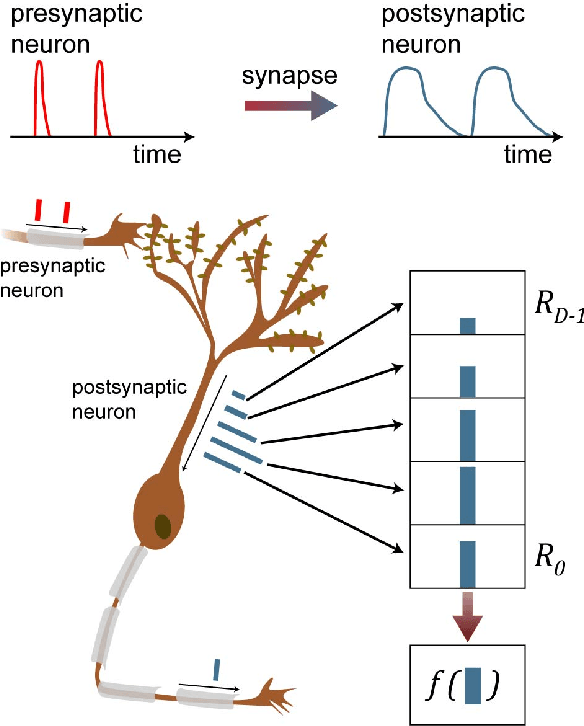
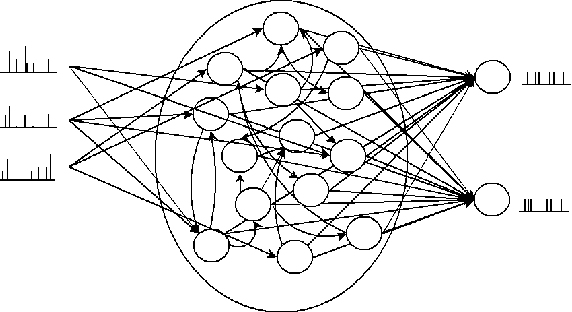

Information in neural networks is represented as weighted connections, or synapses, between neurons. This poses a problem as the primary computational bottleneck for neural networks is the vector-matrix multiply when inputs are multiplied by the neural network weights. Conventional processing architectures are not well suited for simulating neural networks, often requiring large amounts of energy and time. Additionally, synapses in biological neural networks are not binary connections, but exhibit a nonlinear response function as neurotransmitters are emitted and diffuse between neurons. Inspired by neuroscience principles, we present a digital neuromorphic architecture, the Spiking Temporal Processing Unit (STPU), capable of modeling arbitrary complex synaptic response functions without requiring additional hardware components. We consider the paradigm of spiking neurons with temporally coded information as opposed to non-spiking rate coded neurons used in most neural networks. In this paradigm we examine liquid state machines applied to speech recognition and show how a liquid state machine with temporal dynamics maps onto the STPU-demonstrating the flexibility and efficiency of the STPU for instantiating neural algorithms.