 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstant-Depth and Subcubic-Size Threshold Circuits for Matrix Multiplication
Jun 25, 2020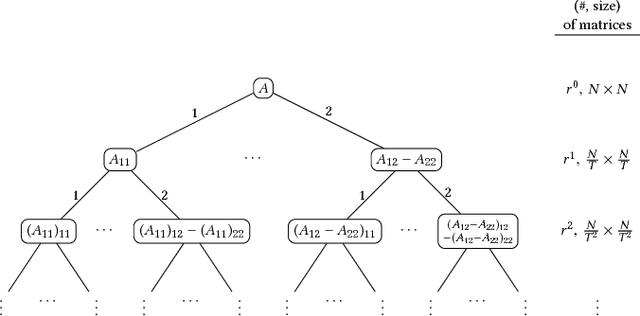
Boolean circuits of McCulloch-Pitts threshold gates are a classic model of neural computation studied heavily in the late 20th century as a model of general computation. Recent advances in large-scale neural computing hardware has made their practical implementation a near-term possibility. We describe a theoretical approach for multiplying two $N$ by $N$ matrices that integrates threshold gate logic with conventional fast matrix multiplication algorithms, that perform $O(N^\omega)$ arithmetic operations for a positive constant $\omega < 3$. Our approach converts such a fast matrix multiplication algorithm into a constant-depth threshold circuit with approximately $O(N^\omega)$ gates. Prior to our work, it was not known whether the $\Theta(N^3)$-gate barrier for matrix multiplication was surmountable by constant-depth threshold circuits. Dense matrix multiplication is a core operation in convolutional neural network training. Performing this work on a neural architecture instead of off-loading it to a GPU may be an appealing option.
Dynamic Analysis of Executables to Detect and Characterize Malware
Sep 28, 2018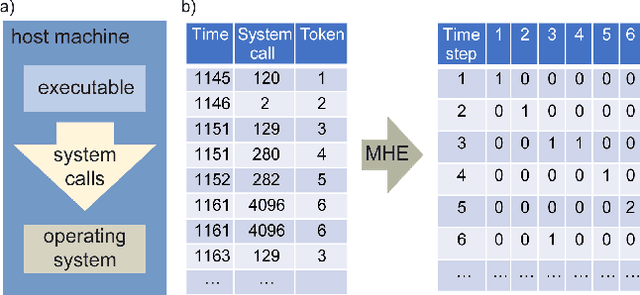
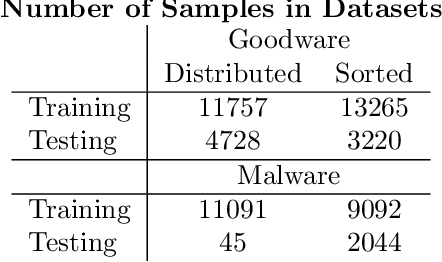
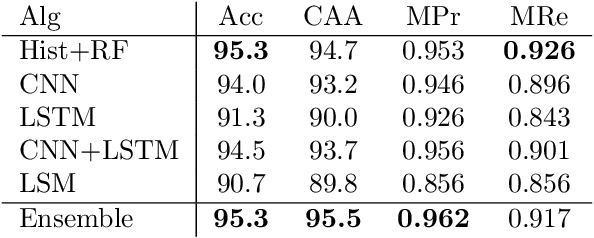
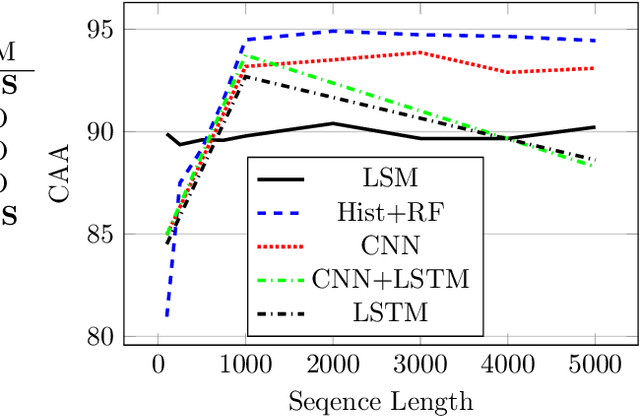
It is needed to ensure the integrity of systems that process sensitive information and control many aspects of everyday life. We examine the use of machine learning algorithms to detect malware using the system calls generated by executables-alleviating attempts at obfuscation as the behavior is monitored rather than the bytes of an executable. We examine several machine learning techniques for detecting malware including random forests, deep learning techniques, and liquid state machines. The experiments examine the effects of concept drift on each algorithm to understand how well the algorithms generalize to novel malware samples by testing them on data that was collected after the training data. The results suggest that each of the examined machine learning algorithms is a viable solution to detect malware-achieving between 90% and 95% class-averaged accuracy (CAA). In real-world scenarios, the performance evaluation on an operational network may not match the performance achieved in training. Namely, the CAA may be about the same, but the values for precision and recall over the malware can change significantly. We structure experiments to highlight these caveats and offer insights into expected performance in operational environments. In addition, we use the induced models to gain a better understanding about what differentiates the malware samples from the goodware, which can further be used as a forensics tool to understand what the malware (or goodware) was doing to provide directions for investigation and remediation.
Resilient Computing with Reinforcement Learning on a Dynamical System: Case Study in Sorting
Sep 25, 2018

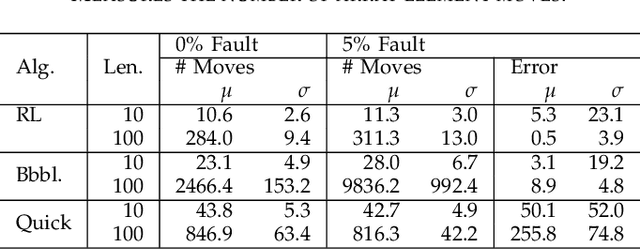

Robots and autonomous agents often complete goal-based tasks with limited resources, relying on imperfect models and sensor measurements. In particular, reinforcement learning (RL) and feedback control can be used to help a robot achieve a goal. Taking advantage of this body of work, this paper formulates general computation as a feedback-control problem, which allows the agent to autonomously overcome some limitations of standard procedural language programming: resilience to errors and early program termination. Our formulation considers computation to be trajectory generation in the program's variable space. The computing then becomes a sequential decision making problem, solved with reinforcement learning (RL), and analyzed with Lyapunov stability theory to assess the agent's resilience and progression to the goal. We do this through a case study on a quintessential computer science problem, array sorting. Evaluations show that our RL sorting agent makes steady progress to an asymptotically stable goal, is resilient to faulty components, and performs less array manipulations than traditional Quicksort and Bubble sort.
Multiscale Co-Design Analysis of Energy, Latency, Area, and Accuracy of a ReRAM Analog Neural Training Accelerator
Feb 17, 2018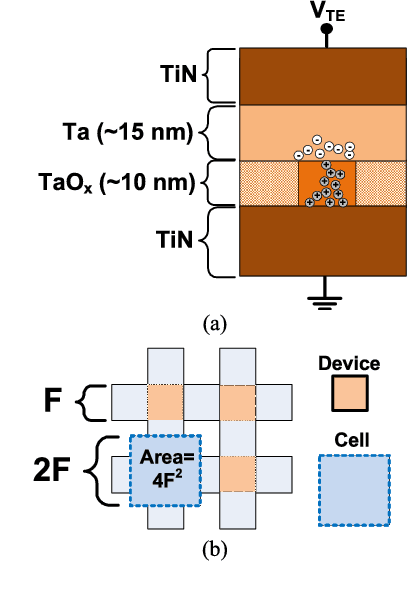
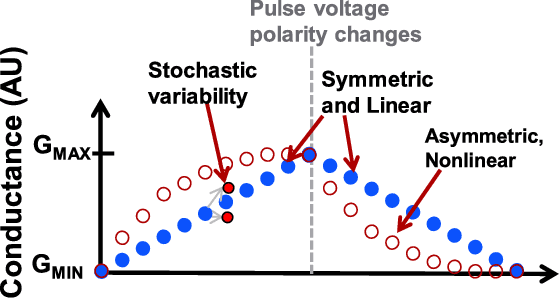
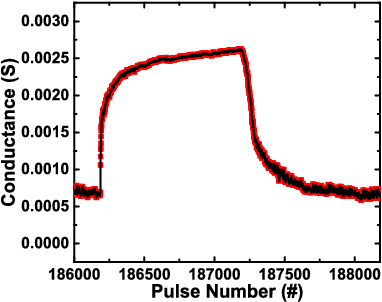
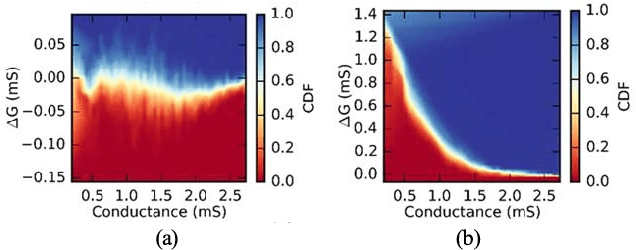
Neural networks are an increasingly attractive algorithm for natural language processing and pattern recognition. Deep networks with >50M parameters are made possible by modern GPU clusters operating at <50 pJ per op and more recently, production accelerators capable of <5pJ per operation at the board level. However, with the slowing of CMOS scaling, new paradigms will be required to achieve the next several orders of magnitude in performance per watt gains. Using an analog resistive memory (ReRAM) crossbar to perform key matrix operations in an accelerator is an attractive option. This work presents a detailed design using a state of the art 14/16 nm PDK for of an analog crossbar circuit block designed to process three key kernels required in training and inference of neural networks. A detailed circuit and device-level analysis of energy, latency, area, and accuracy are given and compared to relevant designs using standard digital ReRAM and SRAM operations. It is shown that the analog accelerator has a 270x energy and 540x latency advantage over a similar block utilizing only digital ReRAM and takes only 11 fJ per multiply and accumulate (MAC). Compared to an SRAM based accelerator, the energy is 430X better and latency is 34X better. Although training accuracy is degraded in the analog accelerator, several options to improve this are presented. The possible gains over a similar digital-only version of this accelerator block suggest that continued optimization of analog resistive memories is valuable. This detailed circuit and device analysis of a training accelerator may serve as a foundation for further architecture-level studies.
Data-driven Feature Sampling for Deep Hyperspectral Classification and Segmentation
Oct 26, 2017



The high dimensionality of hyperspectral imaging forces unique challenges in scope, size and processing requirements. Motivated by the potential for an in-the-field cell sorting detector, we examine a $\textit{Synechocystis sp.}$ PCC 6803 dataset wherein cells are grown alternatively in nitrogen rich or deplete cultures. We use deep learning techniques to both successfully classify cells and generate a mask segmenting the cells/condition from the background. Further, we use the classification accuracy to guide a data-driven, iterative feature selection method, allowing the design neural networks requiring 90% fewer input features with little accuracy degradation.
Neurogenesis Deep Learning
Mar 28, 2017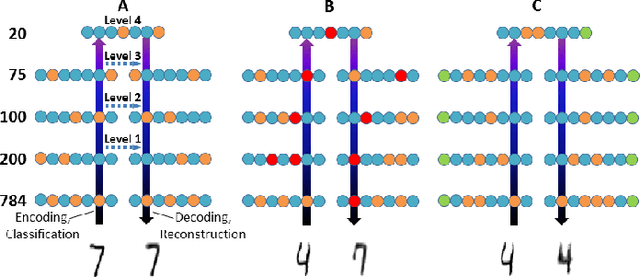
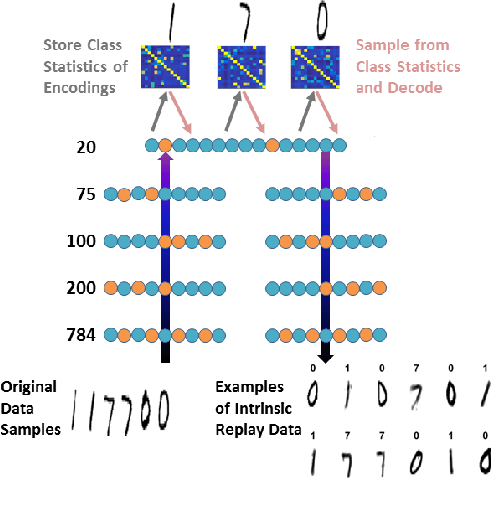

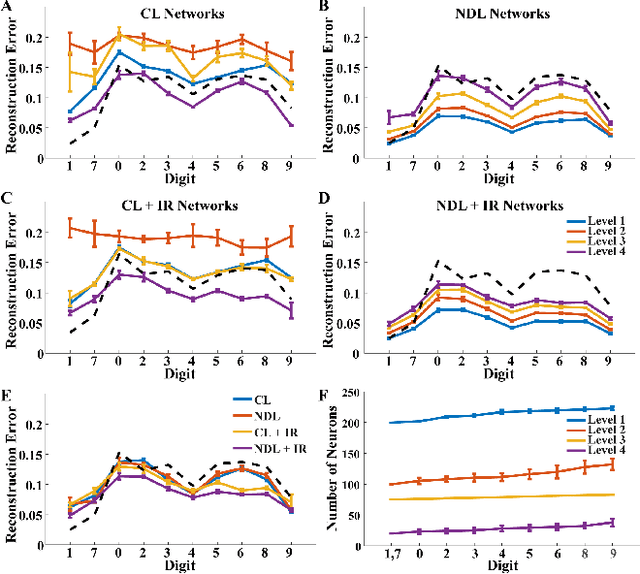
Neural machine learning methods, such as deep neural networks (DNN), have achieved remarkable success in a number of complex data processing tasks. These methods have arguably had their strongest impact on tasks such as image and audio processing - data processing domains in which humans have long held clear advantages over conventional algorithms. In contrast to biological neural systems, which are capable of learning continuously, deep artificial networks have a limited ability for incorporating new information in an already trained network. As a result, methods for continuous learning are potentially highly impactful in enabling the application of deep networks to dynamic data sets. Here, inspired by the process of adult neurogenesis in the hippocampus, we explore the potential for adding new neurons to deep layers of artificial neural networks in order to facilitate their acquisition of novel information while preserving previously trained data representations. Our results on the MNIST handwritten digit dataset and the NIST SD 19 dataset, which includes lower and upper case letters and digits, demonstrate that neurogenesis is well suited for addressing the stability-plasticity dilemma that has long challenged adaptive machine learning algorithms.
A Digital Neuromorphic Architecture Efficiently Facilitating Complex Synaptic Response Functions Applied to Liquid State Machines
Mar 21, 2017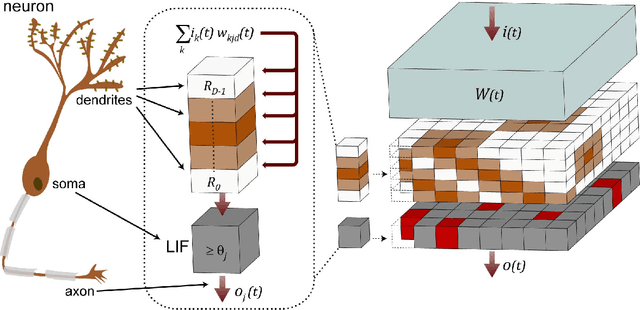
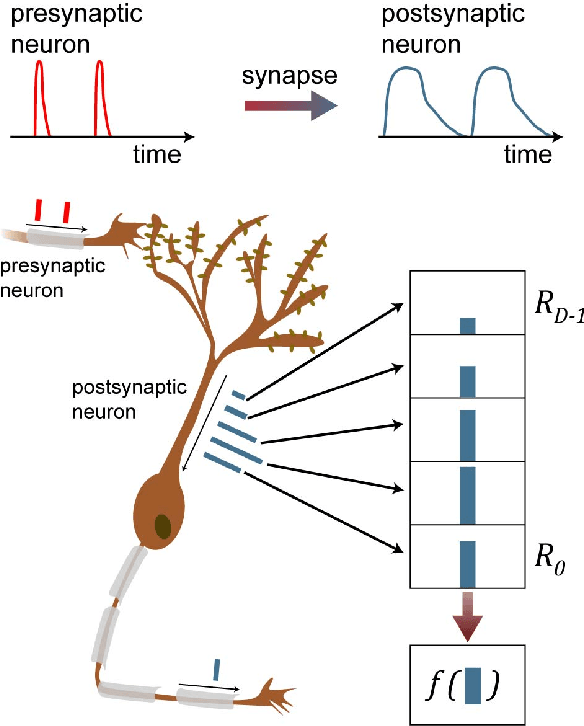
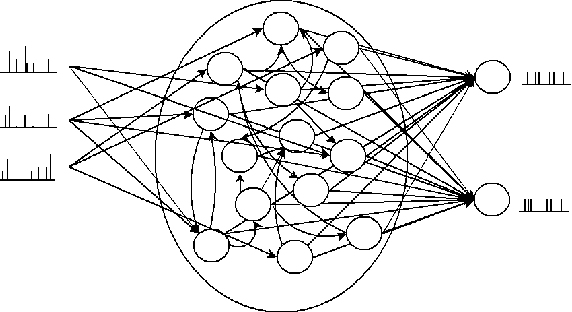

Information in neural networks is represented as weighted connections, or synapses, between neurons. This poses a problem as the primary computational bottleneck for neural networks is the vector-matrix multiply when inputs are multiplied by the neural network weights. Conventional processing architectures are not well suited for simulating neural networks, often requiring large amounts of energy and time. Additionally, synapses in biological neural networks are not binary connections, but exhibit a nonlinear response function as neurotransmitters are emitted and diffuse between neurons. Inspired by neuroscience principles, we present a digital neuromorphic architecture, the Spiking Temporal Processing Unit (STPU), capable of modeling arbitrary complex synaptic response functions without requiring additional hardware components. We consider the paradigm of spiking neurons with temporally coded information as opposed to non-spiking rate coded neurons used in most neural networks. In this paradigm we examine liquid state machines applied to speech recognition and show how a liquid state machine with temporal dynamics maps onto the STPU-demonstrating the flexibility and efficiency of the STPU for instantiating neural algorithms.