 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Updating Models with Error Remediation
May 19, 2020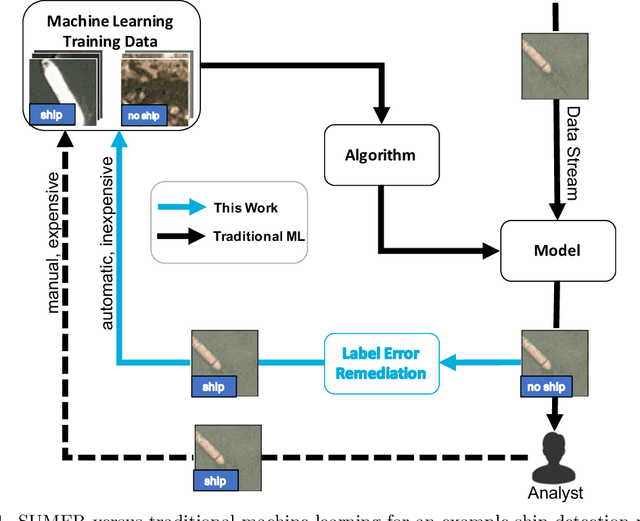
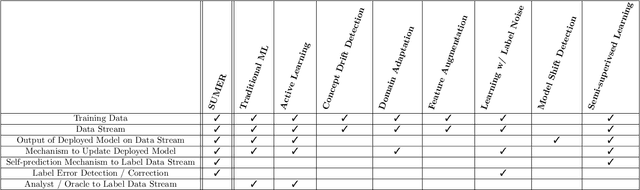

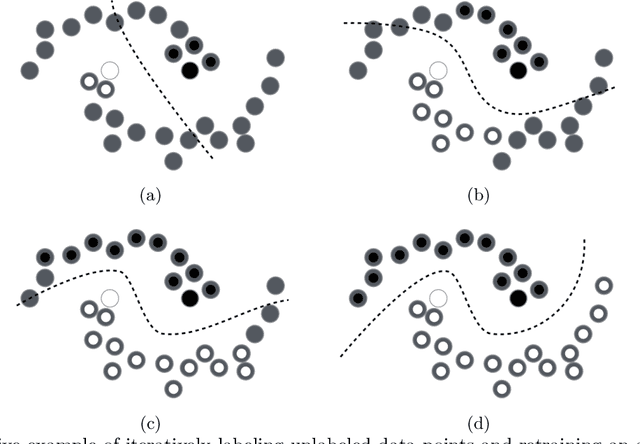
Many environments currently employ machine learning models for data processing and analytics that were built using a limited number of training data points. Once deployed, the models are exposed to significant amounts of previously-unseen data, not all of which is representative of the original, limited training data. However, updating these deployed models can be difficult due to logistical, bandwidth, time, hardware, and/or data sensitivity constraints. We propose a framework, Self-Updating Models with Error Remediation (SUMER), in which a deployed model updates itself as new data becomes available. SUMER uses techniques from semi-supervised learning and noise remediation to iteratively retrain a deployed model using intelligently-chosen predictions from the model as the labels for new training iterations. A key component of SUMER is the notion of error remediation as self-labeled data can be susceptible to the propagation of errors. We investigate the use of SUMER across various data sets and iterations. We find that self-updating models (SUMs) generally perform better than models that do not attempt to self-update when presented with additional previously-unseen data. This performance gap is accentuated in cases where there is only limited amounts of initial training data. We also find that the performance of SUMER is generally better than the performance of SUMs, demonstrating a benefit in applying error remediation. Consequently, SUMER can autonomously enhance the operational capabilities of existing data processing systems by intelligently updating models in dynamic environments.
* 17 pages, 13 figures, published in the proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications II conference in the SPIE Defense + Commercial Sensing, 2020 symposium
Dynamic Analysis of Executables to Detect and Characterize Malware
Sep 28, 2018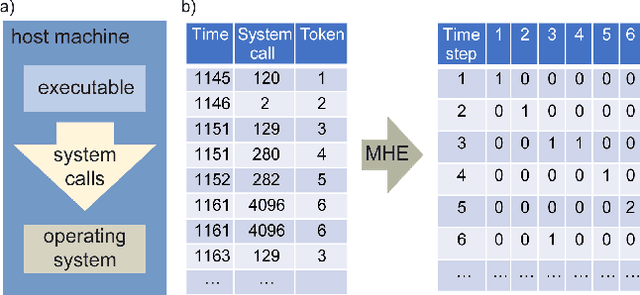
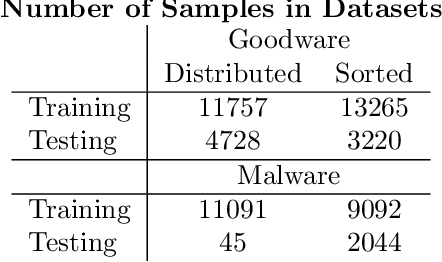
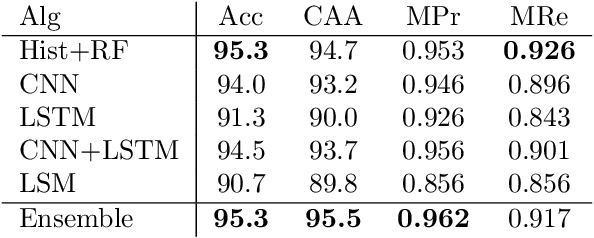
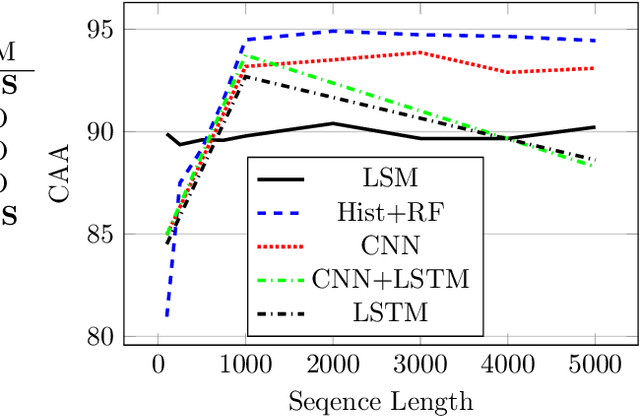
It is needed to ensure the integrity of systems that process sensitive information and control many aspects of everyday life. We examine the use of machine learning algorithms to detect malware using the system calls generated by executables-alleviating attempts at obfuscation as the behavior is monitored rather than the bytes of an executable. We examine several machine learning techniques for detecting malware including random forests, deep learning techniques, and liquid state machines. The experiments examine the effects of concept drift on each algorithm to understand how well the algorithms generalize to novel malware samples by testing them on data that was collected after the training data. The results suggest that each of the examined machine learning algorithms is a viable solution to detect malware-achieving between 90% and 95% class-averaged accuracy (CAA). In real-world scenarios, the performance evaluation on an operational network may not match the performance achieved in training. Namely, the CAA may be about the same, but the values for precision and recall over the malware can change significantly. We structure experiments to highlight these caveats and offer insights into expected performance in operational environments. In addition, we use the induced models to gain a better understanding about what differentiates the malware samples from the goodware, which can further be used as a forensics tool to understand what the malware (or goodware) was doing to provide directions for investigation and remediation.