 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Updating Models with Error Remediation
May 19, 2020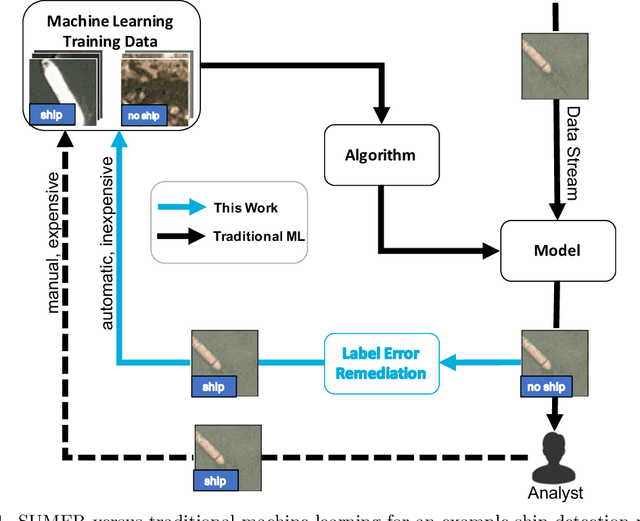
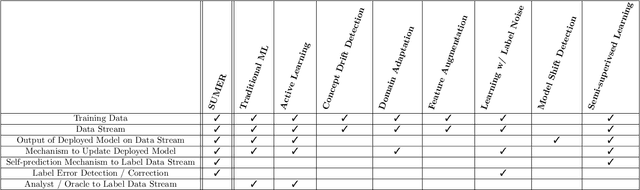

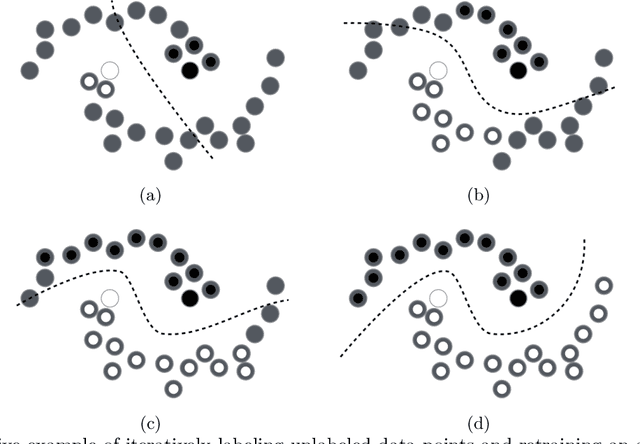
Many environments currently employ machine learning models for data processing and analytics that were built using a limited number of training data points. Once deployed, the models are exposed to significant amounts of previously-unseen data, not all of which is representative of the original, limited training data. However, updating these deployed models can be difficult due to logistical, bandwidth, time, hardware, and/or data sensitivity constraints. We propose a framework, Self-Updating Models with Error Remediation (SUMER), in which a deployed model updates itself as new data becomes available. SUMER uses techniques from semi-supervised learning and noise remediation to iteratively retrain a deployed model using intelligently-chosen predictions from the model as the labels for new training iterations. A key component of SUMER is the notion of error remediation as self-labeled data can be susceptible to the propagation of errors. We investigate the use of SUMER across various data sets and iterations. We find that self-updating models (SUMs) generally perform better than models that do not attempt to self-update when presented with additional previously-unseen data. This performance gap is accentuated in cases where there is only limited amounts of initial training data. We also find that the performance of SUMER is generally better than the performance of SUMs, demonstrating a benefit in applying error remediation. Consequently, SUMER can autonomously enhance the operational capabilities of existing data processing systems by intelligently updating models in dynamic environments.
* 17 pages, 13 figures, published in the proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications II conference in the SPIE Defense + Commercial Sensing, 2020 symposium
Mind the Gap: On Bridging the Semantic Gap between Machine Learning and Information Security
May 04, 2020
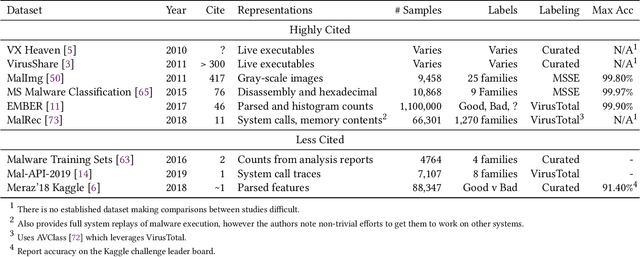

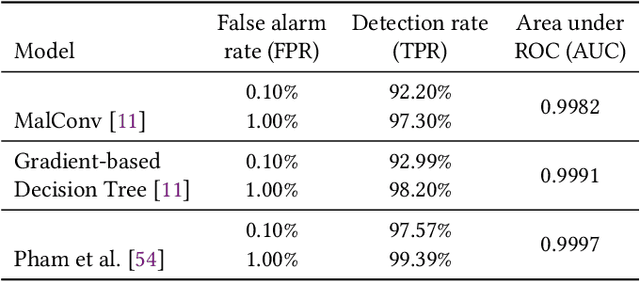
Despite the potential of Machine learning (ML) to learn the behavior of malware, detect novel malware samples, and significantly improve information security (InfoSec) we see few, if any, high-impact ML techniques in deployed systems, notwithstanding multiple reported successes in open literature. We hypothesize that the failure of ML in making high-impacts in InfoSec are rooted in a disconnect between the two communities as evidenced by a semantic gap---a difference in how executables are described (e.g. the data and features extracted from the data). Specifically, current datasets and representations used by ML are not suitable for learning the behaviors of an executable and differ significantly from those used by the InfoSec community. In this paper, we survey existing datasets used for classifying malware by ML algorithms and the features that are extracted from the data. We observe that: 1) the current set of extracted features are primarily syntactic, not behavioral, 2) datasets generally contain extreme exemplars producing a dataset in which it is easy to discriminate classes, and 3) the datasets provide significantly different representations of the data encountered in real-world systems. For ML to make more of an impact in the InfoSec community requires a change in the data (including the features and labels) that is used to bridge the current semantic gap. As a first step in enabling more behavioral analyses, we label existing malware datasets with behavioral features using open-source threat reports associated with malware families. This behavioral labeling alters the analysis from identifying intent (e.g. good vs bad) or malware family membership to an analysis of which behaviors are exhibited by an executable. We offer the annotations with the hope of inspiring future improvements in the data that will further bridge the semantic gap between the ML and InfoSec communities.
Dynamic Analysis of Executables to Detect and Characterize Malware
Sep 28, 2018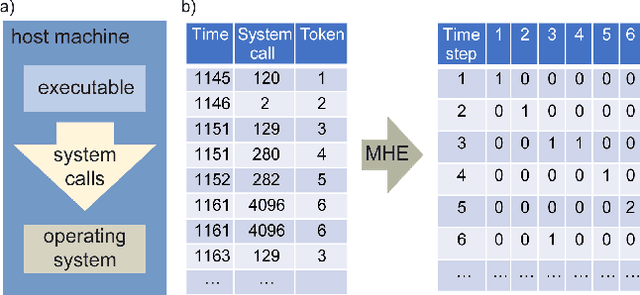
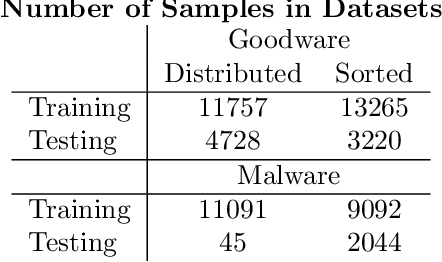
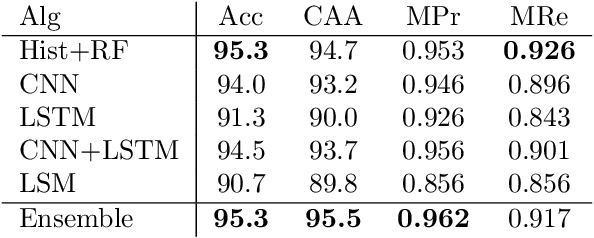
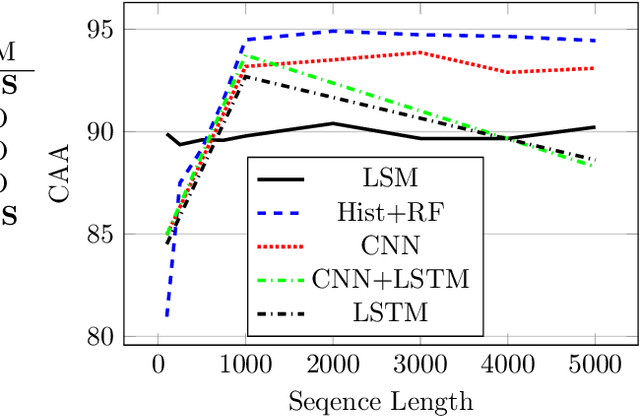
It is needed to ensure the integrity of systems that process sensitive information and control many aspects of everyday life. We examine the use of machine learning algorithms to detect malware using the system calls generated by executables-alleviating attempts at obfuscation as the behavior is monitored rather than the bytes of an executable. We examine several machine learning techniques for detecting malware including random forests, deep learning techniques, and liquid state machines. The experiments examine the effects of concept drift on each algorithm to understand how well the algorithms generalize to novel malware samples by testing them on data that was collected after the training data. The results suggest that each of the examined machine learning algorithms is a viable solution to detect malware-achieving between 90% and 95% class-averaged accuracy (CAA). In real-world scenarios, the performance evaluation on an operational network may not match the performance achieved in training. Namely, the CAA may be about the same, but the values for precision and recall over the malware can change significantly. We structure experiments to highlight these caveats and offer insights into expected performance in operational environments. In addition, we use the induced models to gain a better understanding about what differentiates the malware samples from the goodware, which can further be used as a forensics tool to understand what the malware (or goodware) was doing to provide directions for investigation and remediation.
A Digital Neuromorphic Architecture Efficiently Facilitating Complex Synaptic Response Functions Applied to Liquid State Machines
Mar 21, 2017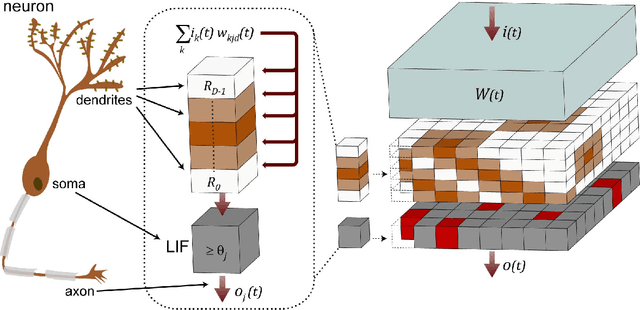
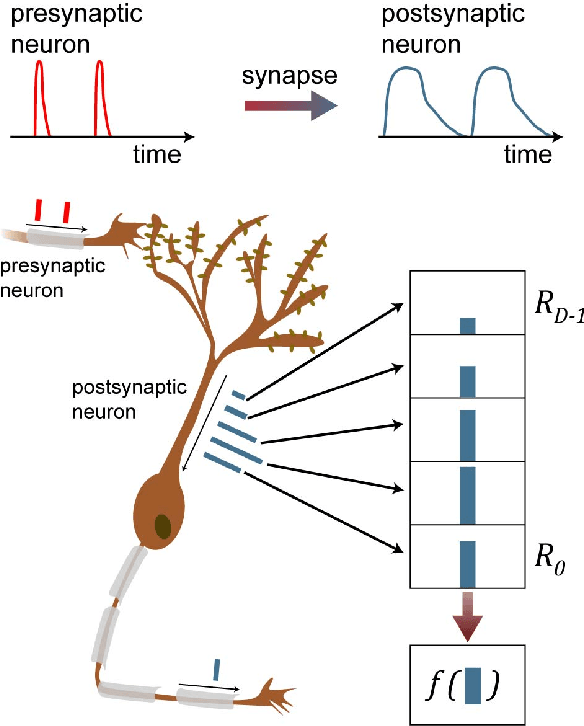
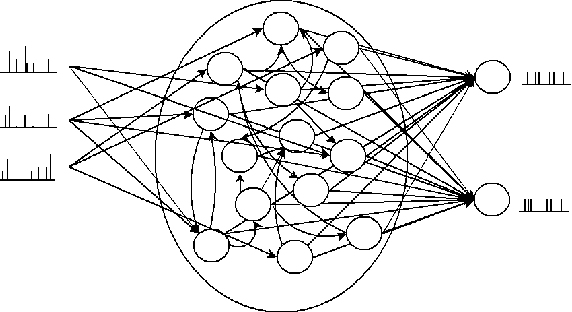

Information in neural networks is represented as weighted connections, or synapses, between neurons. This poses a problem as the primary computational bottleneck for neural networks is the vector-matrix multiply when inputs are multiplied by the neural network weights. Conventional processing architectures are not well suited for simulating neural networks, often requiring large amounts of energy and time. Additionally, synapses in biological neural networks are not binary connections, but exhibit a nonlinear response function as neurotransmitters are emitted and diffuse between neurons. Inspired by neuroscience principles, we present a digital neuromorphic architecture, the Spiking Temporal Processing Unit (STPU), capable of modeling arbitrary complex synaptic response functions without requiring additional hardware components. We consider the paradigm of spiking neurons with temporally coded information as opposed to non-spiking rate coded neurons used in most neural networks. In this paradigm we examine liquid state machines applied to speech recognition and show how a liquid state machine with temporal dynamics maps onto the STPU-demonstrating the flexibility and efficiency of the STPU for instantiating neural algorithms.
A Minimal Architecture for General Cognition
Jul 31, 2015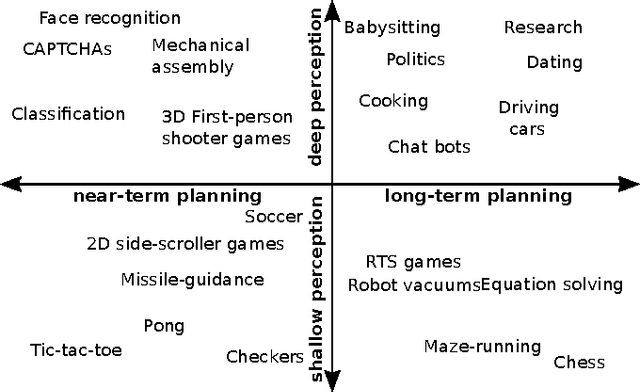
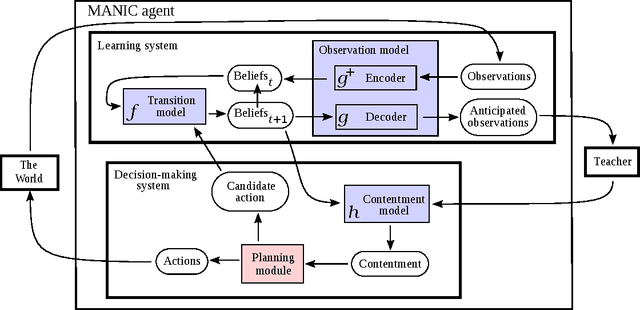
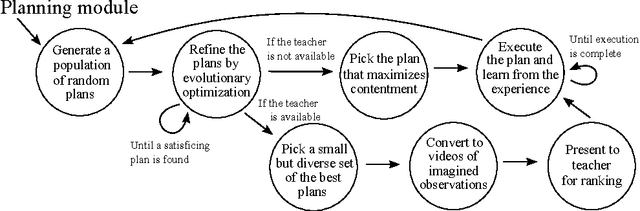

A minimalistic cognitive architecture called MANIC is presented. The MANIC architecture requires only three function approximating models, and one state machine. Even with so few major components, it is theoretically sufficient to achieve functional equivalence with all other cognitive architectures, and can be practically trained. Instead of seeking to transfer architectural inspiration from biology into artificial intelligence, MANIC seeks to minimize novelty and follow the most well-established constructs that have evolved within various sub-fields of data science. From this perspective, MANIC offers an alternate approach to a long-standing objective of artificial intelligence. This paper provides a theoretical analysis of the MANIC architecture.
A Hierarchical Multi-Output Nearest Neighbor Model for Multi-Output Dependence Learning
Oct 17, 2014


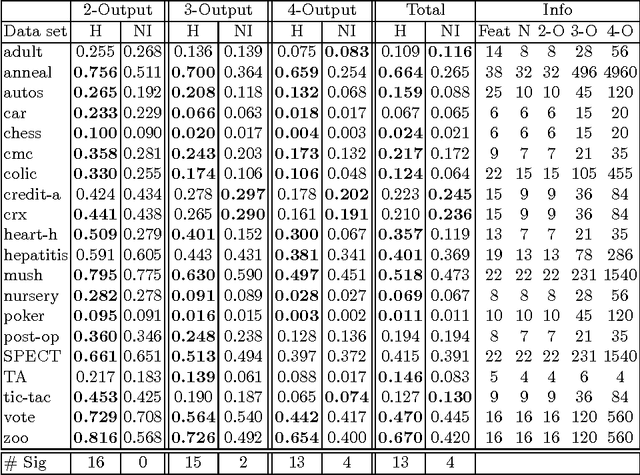
Multi-Output Dependence (MOD) learning is a generalization of standard classification problems that allows for multiple outputs that are dependent on each other. A primary issue that arises in the context of MOD learning is that for any given input pattern there can be multiple correct output patterns. This changes the learning task from function approximation to relation approximation. Previous algorithms do not consider this problem, and thus cannot be readily applied to MOD problems. To perform MOD learning, we introduce the Hierarchical Multi-Output Nearest Neighbor model (HMONN) that employs a basic learning model for each output and a modified nearest neighbor approach to refine the initial results.
Reducing the Effects of Detrimental Instances
Oct 14, 2014



Not all instances in a data set are equally beneficial for inducing a model of the data. Some instances (such as outliers or noise) can be detrimental. However, at least initially, the instances in a data set are generally considered equally in machine learning algorithms. Many current approaches for handling noisy and detrimental instances make a binary decision about whether an instance is detrimental or not. In this paper, we 1) extend this paradigm by weighting the instances on a continuous scale and 2) present a methodology for measuring how detrimental an instance may be for inducing a model of the data. We call our method of identifying and weighting detrimental instances reduced detrimental instance learning (RDIL). We examine RIDL on a set of 54 data sets and 5 learning algorithms and compare RIDL with other weighting and filtering approaches. RDIL is especially useful for learning algorithms where every instance can affect the classification boundary and the training instances are considered individually, such as multilayer perceptrons trained with backpropagation (MLPs). Our results also suggest that a more accurate estimate of which instances are detrimental can have a significant positive impact for handling them.
Recommending Learning Algorithms and Their Associated Hyperparameters
Jul 07, 2014

The success of machine learning on a given task dependson, among other things, which learning algorithm is selected and its associated hyperparameters. Selecting an appropriate learning algorithm and setting its hyperparameters for a given data set can be a challenging task, especially for users who are not experts in machine learning. Previous work has examined using meta-features to predict which learning algorithm and hyperparameters should be used. However, choosing a set of meta-features that are predictive of algorithm performance is difficult. Here, we propose to apply collaborative filtering techniques to learning algorithm and hyperparameter selection, and find that doing so avoids determining which meta-features to use and outperforms traditional meta-learning approaches in many cases.
A Hybrid Latent Variable Neural Network Model for Item Recommendation
Jun 09, 2014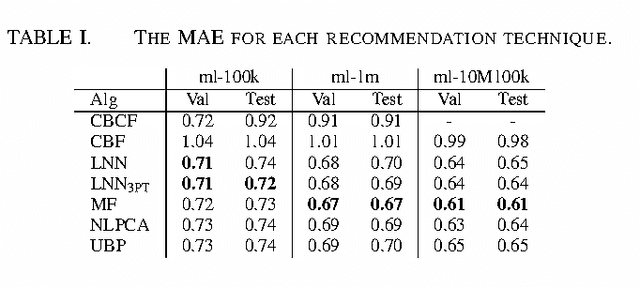
Collaborative filtering is used to recommend items to a user without requiring a knowledge of the item itself and tends to outperform other techniques. However, collaborative filtering suffers from the cold-start problem, which occurs when an item has not yet been rated or a user has not rated any items. Incorporating additional information, such as item or user descriptions, into collaborative filtering can address the cold-start problem. In this paper, we present a neural network model with latent input variables (latent neural network or LNN) as a hybrid collaborative filtering technique that addresses the cold-start problem. LNN outperforms a broad selection of content-based filters (which make recommendations based on item descriptions) and other hybrid approaches while maintaining the accuracy of state-of-the-art collaborative filtering techniques.
An Easy to Use Repository for Comparing and Improving Machine Learning Algorithm Usage
Jun 05, 2014
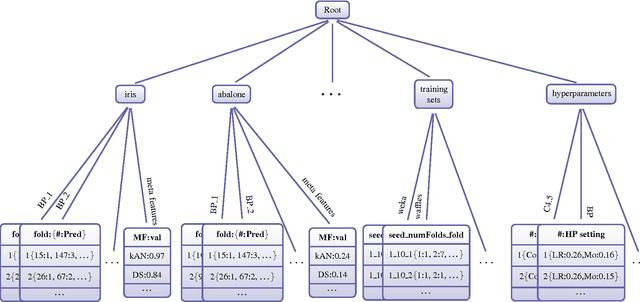
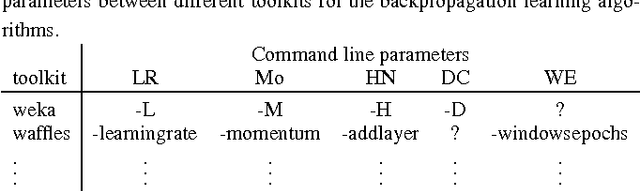

The results from most machine learning experiments are used for a specific purpose and then discarded. This results in a significant loss of information and requires rerunning experiments to compare learning algorithms. This also requires implementation of another algorithm for comparison, that may not always be correctly implemented. By storing the results from previous experiments, machine learning algorithms can be compared easily and the knowledge gained from them can be used to improve their performance. The purpose of this work is to provide easy access to previous experimental results for learning and comparison. These stored results are comprehensive -- storing the prediction for each test instance as well as the learning algorithm, hyperparameters, and training set that were used. Previous results are particularly important for meta-learning, which, in a broad sense, is the process of learning from previous machine learning results such that the learning process is improved. While other experiment databases do exist, one of our focuses is on easy access to the data. We provide meta-learning data sets that are ready to be downloaded for meta-learning experiments. In addition, queries to the underlying database can be made if specific information is desired. We also differ from previous experiment databases in that our databases is designed at the instance level, where an instance is an example in a data set. We store the predictions of a learning algorithm trained on a specific training set for each instance in the test set. Data set level information can then be obtained by aggregating the results from the instances. The instance level information can be used for many tasks such as determining the diversity of a classifier or algorithmically determining the optimal subset of training instances for a learning algorithm.