 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: On Bridging the Semantic Gap between Machine Learning and Information Security
May 04, 2020
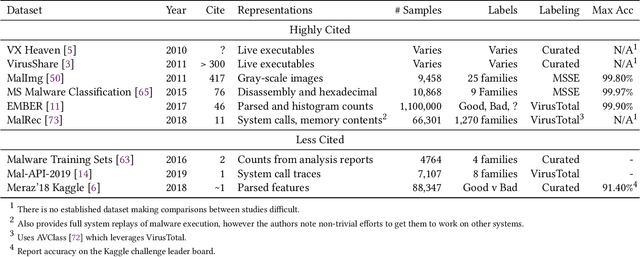

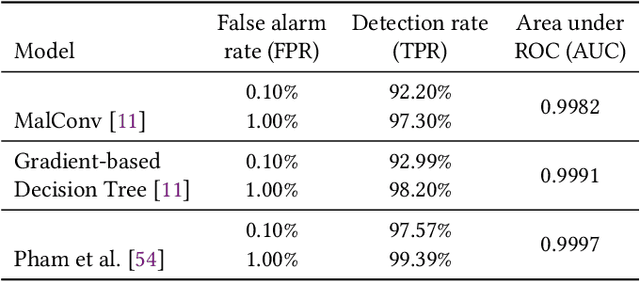
Despite the potential of Machine learning (ML) to learn the behavior of malware, detect novel malware samples, and significantly improve information security (InfoSec) we see few, if any, high-impact ML techniques in deployed systems, notwithstanding multiple reported successes in open literature. We hypothesize that the failure of ML in making high-impacts in InfoSec are rooted in a disconnect between the two communities as evidenced by a semantic gap---a difference in how executables are described (e.g. the data and features extracted from the data). Specifically, current datasets and representations used by ML are not suitable for learning the behaviors of an executable and differ significantly from those used by the InfoSec community. In this paper, we survey existing datasets used for classifying malware by ML algorithms and the features that are extracted from the data. We observe that: 1) the current set of extracted features are primarily syntactic, not behavioral, 2) datasets generally contain extreme exemplars producing a dataset in which it is easy to discriminate classes, and 3) the datasets provide significantly different representations of the data encountered in real-world systems. For ML to make more of an impact in the InfoSec community requires a change in the data (including the features and labels) that is used to bridge the current semantic gap. As a first step in enabling more behavioral analyses, we label existing malware datasets with behavioral features using open-source threat reports associated with malware families. This behavioral labeling alters the analysis from identifying intent (e.g. good vs bad) or malware family membership to an analysis of which behaviors are exhibited by an executable. We offer the annotations with the hope of inspiring future improvements in the data that will further bridge the semantic gap between the ML and InfoSec communities.
COMET: A Recipe for Learning and Using Large Ensembles on Massive Data
Sep 08, 2011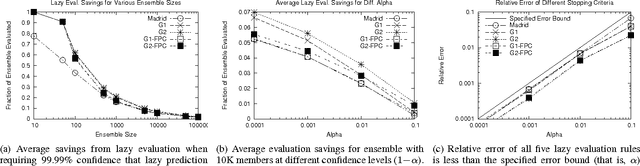
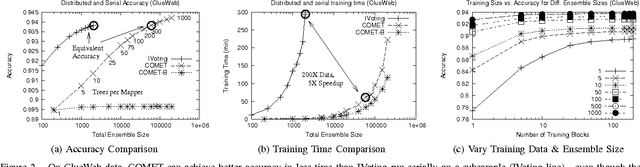
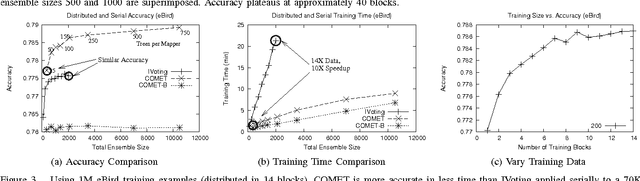
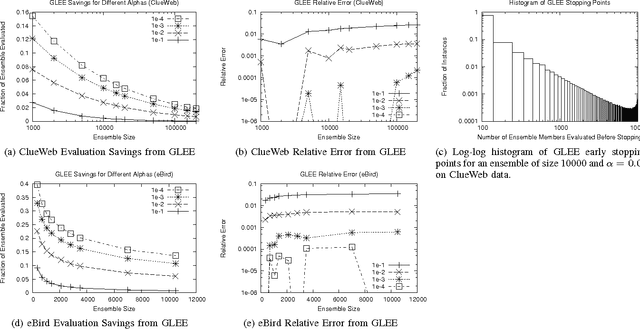
COMET is a single-pass MapReduce algorithm for learning on large-scale data. It builds multiple random forest ensembles on distributed blocks of data and merges them into a mega-ensemble. This approach is appropriate when learning from massive-scale data that is too large to fit on a single machine. To get the best accuracy, IVoting should be used instead of bagging to generate the training subset for each decision tree in the random forest. Experiments with two large datasets (5GB and 50GB compressed) show that COMET compares favorably (in both accuracy and training time) to learning on a subsample of data using a serial algorithm. Finally, we propose a new Gaussian approach for lazy ensemble evaluation which dynamically decides how many ensemble members to evaluate per data point; this can reduce evaluation cost by 100X or more.