 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Data-Driven Workflows in Radio Interferometry. I. Principal Demonstration in Calibration
Oct 22, 2024Radio interferometry is an observational technique used to study astrophysical phenomena. Data gathered by an interferometer requires substantial processing before astronomers can extract the scientific information from it. Data processing consists of a sequence of calibration and analysis procedures where choices must be made about the sequence of procedures as well as the specific configuration of the procedure itself. These choices are typically based on a combination of measurable data characteristics, an understanding of the instrument itself, an appreciation of the trade-offs between compute cost and accuracy, and a learned understanding of what is considered "best practice". A metric of absolute correctness is not always available and validity is often subject to human judgment. The underlying principles and software configurations to discern a reasonable workflow for a given dataset is the subject of training workshops for students and scientists. Our goal is to use objective metrics that quantify best practice, and numerically map out the decision space with respect to our metrics. With these objective metrics we demonstrate an automated, data-driven, decision system that is capable of sequencing the optimal action(s) for processing interferometric data. This paper introduces a simplified description of the principles behind interferometry and the procedures required for data processing. We highlight the issues with current automation approaches and propose our ideas for solving these bottlenecks. A prototype is demonstrated and the results are discussed.
Learning with distributional inverters
Dec 23, 2021We generalize the "indirect learning" technique of Furst et. al., 1991 to reduce from learning a concept class over a samplable distribution $\mu$ to learning the same concept class over the uniform distribution. The reduction succeeds when the sampler for $\mu$ is both contained in the target concept class and efficiently invertible in the sense of Impagliazzo & Luby, 1989. We give two applications. - We show that AC0[q] is learnable over any succinctly-described product distribution. AC0[q] is the class of constant-depth Boolean circuits of polynomial size with AND, OR, NOT, and counting modulo $q$ gates of unbounded fanins. Our algorithm runs in randomized quasi-polynomial time and uses membership queries. - If there is a strongly useful natural property in the sense of Razborov & Rudich 1997 -- an efficient algorithm that can distinguish between random strings and strings of non-trivial circuit complexity -- then general polynomial-sized Boolean circuits are learnable over any efficiently samplable distribution in randomized polynomial time, given membership queries to the target function
Mind the Gap: On Bridging the Semantic Gap between Machine Learning and Information Security
May 04, 2020
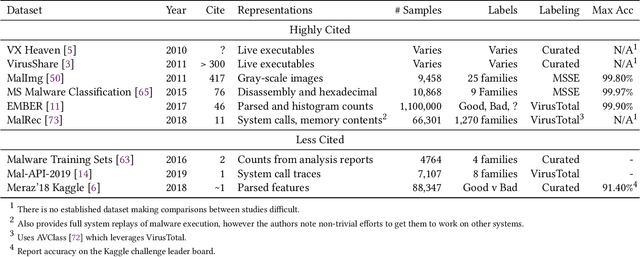

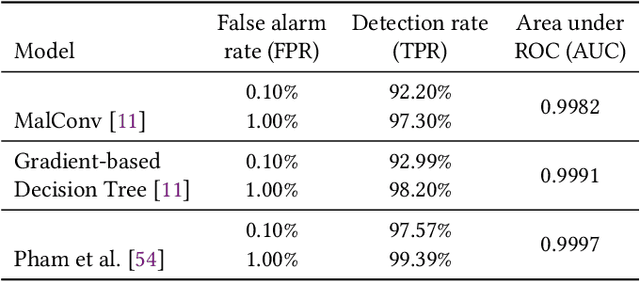
Despite the potential of Machine learning (ML) to learn the behavior of malware, detect novel malware samples, and significantly improve information security (InfoSec) we see few, if any, high-impact ML techniques in deployed systems, notwithstanding multiple reported successes in open literature. We hypothesize that the failure of ML in making high-impacts in InfoSec are rooted in a disconnect between the two communities as evidenced by a semantic gap---a difference in how executables are described (e.g. the data and features extracted from the data). Specifically, current datasets and representations used by ML are not suitable for learning the behaviors of an executable and differ significantly from those used by the InfoSec community. In this paper, we survey existing datasets used for classifying malware by ML algorithms and the features that are extracted from the data. We observe that: 1) the current set of extracted features are primarily syntactic, not behavioral, 2) datasets generally contain extreme exemplars producing a dataset in which it is easy to discriminate classes, and 3) the datasets provide significantly different representations of the data encountered in real-world systems. For ML to make more of an impact in the InfoSec community requires a change in the data (including the features and labels) that is used to bridge the current semantic gap. As a first step in enabling more behavioral analyses, we label existing malware datasets with behavioral features using open-source threat reports associated with malware families. This behavioral labeling alters the analysis from identifying intent (e.g. good vs bad) or malware family membership to an analysis of which behaviors are exhibited by an executable. We offer the annotations with the hope of inspiring future improvements in the data that will further bridge the semantic gap between the ML and InfoSec communities.
Biologically inspired sleep algorithm for artificial neural networks
Aug 01, 2019



Sleep plays an important role in incremental learning and consolidation of memories in biological systems. Motivated by the processes that are known to be involved in sleep generation in biological networks, we developed an algorithm that implements a sleep-like phase in artificial neural networks (ANNs). After initial training phase, we convert the ANN to a spiking neural network (SNN) and simulate an offline sleep-like phase using spike-timing dependent plasticity rules to modify synaptic weights. The SNN is then converted back to the ANN and evaluated or trained on new inputs. We demonstrate several performance improvements after applying this processing to ANNs trained on MNIST, CUB200 and a motivating toy dataset. First, in an incremental learning framework, sleep is able to recover older tasks that were otherwise forgotten in the ANN without sleep phase due to catastrophic forgetting. Second, sleep results in forward transfer learning of unseen tasks. Finally, sleep improves generalization ability of the ANNs to classify images with various types of noise. We provide a theoretical basis for the beneficial role of the brain-inspired sleep-like phase for the ANNs and present an algorithmic way for future implementations of the various features of sleep in deep learning ANNs. Overall, these results suggest that biological sleep can help mitigate a number of problems ANNs suffer from, such as poor generalization and catastrophic forgetting for incremental learning.