 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreprocessor Selection for Machine Learning Pipelines
Oct 23, 2018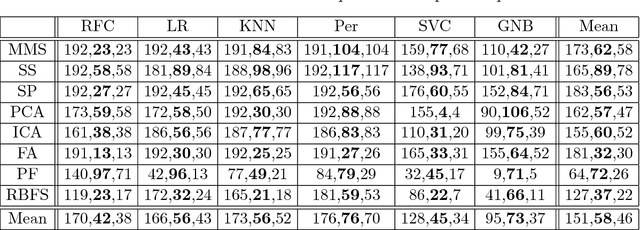
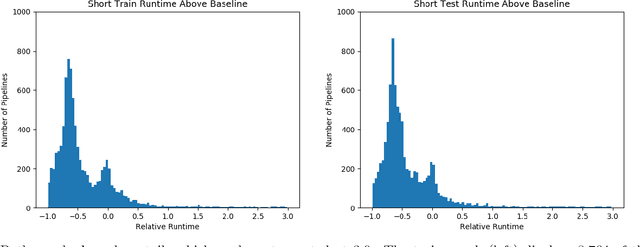
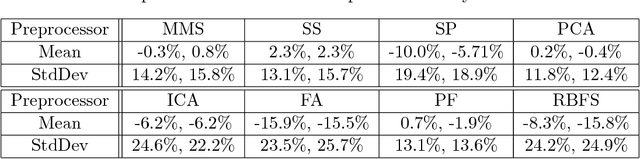

Much of the work in metalearning has focused on classifier selection, combined more recently with hyperparameter optimization, with little concern for data preprocessing. Yet, it is generally well accepted that machine learning applications require not only model building, but also data preprocessing. In other words, practical solutions consist of pipelines of machine learning operators rather than single algorithms. Interestingly, our experiments suggest that, on average, data preprocessing hinders accuracy, while the best performing pipelines do actually make use of preprocessors. Here, we conduct an extensive empirical study over a wide range of learning algorithms and preprocessors, and use metalearning to determine when one should make use of preprocessors in ML pipeline design.
Recommending Learning Algorithms and Their Associated Hyperparameters
Jul 07, 2014

The success of machine learning on a given task dependson, among other things, which learning algorithm is selected and its associated hyperparameters. Selecting an appropriate learning algorithm and setting its hyperparameters for a given data set can be a challenging task, especially for users who are not experts in machine learning. Previous work has examined using meta-features to predict which learning algorithm and hyperparameters should be used. However, choosing a set of meta-features that are predictive of algorithm performance is difficult. Here, we propose to apply collaborative filtering techniques to learning algorithm and hyperparameter selection, and find that doing so avoids determining which meta-features to use and outperforms traditional meta-learning approaches in many cases.
An Easy to Use Repository for Comparing and Improving Machine Learning Algorithm Usage
Jun 05, 2014
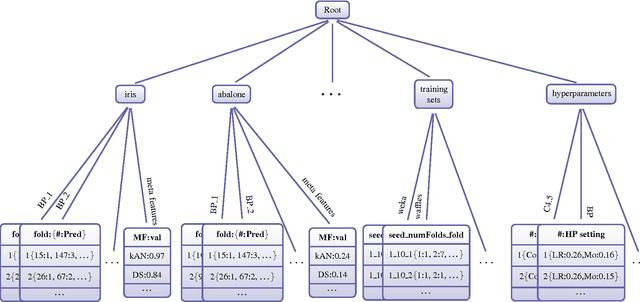

The results from most machine learning experiments are used for a specific purpose and then discarded. This results in a significant loss of information and requires rerunning experiments to compare learning algorithms. This also requires implementation of another algorithm for comparison, that may not always be correctly implemented. By storing the results from previous experiments, machine learning algorithms can be compared easily and the knowledge gained from them can be used to improve their performance. The purpose of this work is to provide easy access to previous experimental results for learning and comparison. These stored results are comprehensive -- storing the prediction for each test instance as well as the learning algorithm, hyperparameters, and training set that were used. Previous results are particularly important for meta-learning, which, in a broad sense, is the process of learning from previous machine learning results such that the learning process is improved. While other experiment databases do exist, one of our focuses is on easy access to the data. We provide meta-learning data sets that are ready to be downloaded for meta-learning experiments. In addition, queries to the underlying database can be made if specific information is desired. We also differ from previous experiment databases in that our databases is designed at the instance level, where an instance is an example in a data set. We store the predictions of a learning algorithm trained on a specific training set for each instance in the test set. Data set level information can then be obtained by aggregating the results from the instances. The instance level information can be used for many tasks such as determining the diversity of a classifier or algorithmically determining the optimal subset of training instances for a learning algorithm.
The Potential Benefits of Filtering Versus Hyper-Parameter Optimization
Mar 13, 2014



The quality of an induced model by a learning algorithm is dependent on the quality of the training data and the hyper-parameters supplied to the learning algorithm. Prior work has shown that improving the quality of the training data (i.e., by removing low quality instances) or tuning the learning algorithm hyper-parameters can significantly improve the quality of an induced model. A comparison of the two methods is lacking though. In this paper, we estimate and compare the potential benefits of filtering and hyper-parameter optimization. Estimating the potential benefit gives an overly optimistic estimate but also empirically demonstrates an approximation of the maximum potential benefit of each method. We find that, while both significantly improve the induced model, improving the quality of the training set has a greater potential effect than hyper-parameter optimization.