 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurogenesis Deep Learning
Mar 28, 2017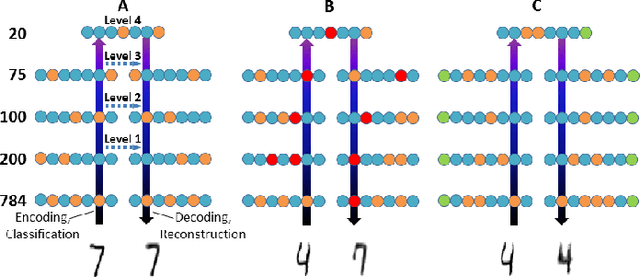
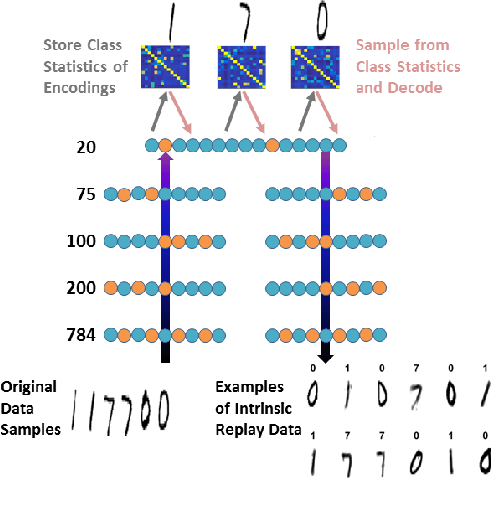

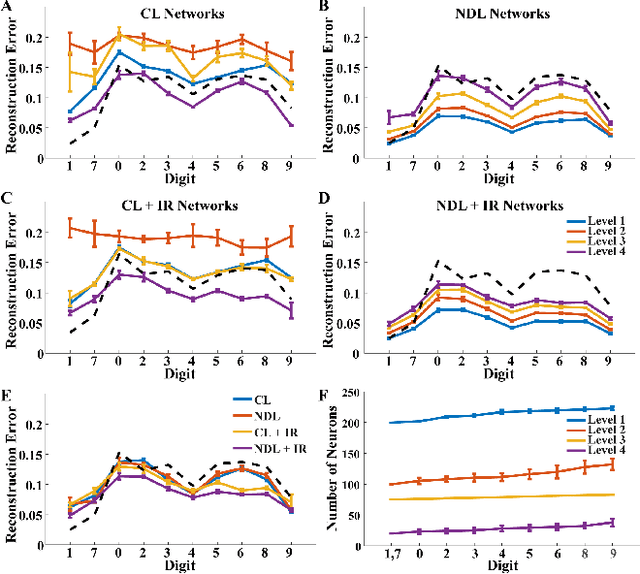
Neural machine learning methods, such as deep neural networks (DNN), have achieved remarkable success in a number of complex data processing tasks. These methods have arguably had their strongest impact on tasks such as image and audio processing - data processing domains in which humans have long held clear advantages over conventional algorithms. In contrast to biological neural systems, which are capable of learning continuously, deep artificial networks have a limited ability for incorporating new information in an already trained network. As a result, methods for continuous learning are potentially highly impactful in enabling the application of deep networks to dynamic data sets. Here, inspired by the process of adult neurogenesis in the hippocampus, we explore the potential for adding new neurons to deep layers of artificial neural networks in order to facilitate their acquisition of novel information while preserving previously trained data representations. Our results on the MNIST handwritten digit dataset and the NIST SD 19 dataset, which includes lower and upper case letters and digits, demonstrate that neurogenesis is well suited for addressing the stability-plasticity dilemma that has long challenged adaptive machine learning algorithms.
Parameter Compression of Recurrent Neural Networks and Degradation of Short-term Memory
Feb 24, 2017



The significant computational costs of deploying neural networks in large-scale or resource constrained environments, such as data centers and mobile devices, has spurred interest in model compression, which can achieve a reduction in both arithmetic operations and storage memory. Several techniques have been proposed for reducing or compressing the parameters for feed-forward and convolutional neural networks, but less is understood about the effect of parameter compression on recurrent neural networks (RNN). In particular, the extent to which the recurrent parameters can be compressed and the impact on short-term memory performance, is not well understood. In this paper, we study the effect of complexity reduction, through singular value decomposition rank reduction, on RNN and minimal gated recurrent unit (MGRU) networks for several tasks. We show that considerable rank reduction is possible when compressing recurrent weights, even without fine tuning. Furthermore, we propose a perturbation model for the effect of general perturbations, such as a compression, on the recurrent parameters of RNNs. The model is tested against a noiseless memorization experiment that elucidates the short-term memory performance. In this way, we demonstrate that the effect of compression of recurrent parameters is dependent on the degree of temporal coherence present in the data and task. This work can guide on-the-fly RNN compression for novel environments or tasks, and provides insight for applying RNN compression in low-power devices, such as hearing aids.