 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Computing with Reinforcement Learning on a Dynamical System: Case Study in Sorting
Paper and Code
Sep 25, 2018

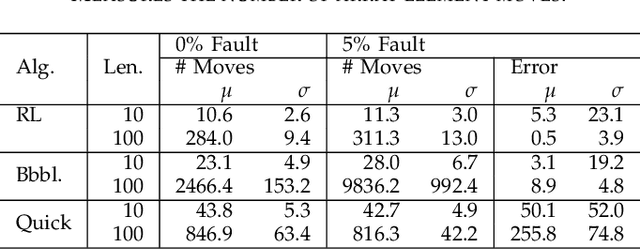

Robots and autonomous agents often complete goal-based tasks with limited resources, relying on imperfect models and sensor measurements. In particular, reinforcement learning (RL) and feedback control can be used to help a robot achieve a goal. Taking advantage of this body of work, this paper formulates general computation as a feedback-control problem, which allows the agent to autonomously overcome some limitations of standard procedural language programming: resilience to errors and early program termination. Our formulation considers computation to be trajectory generation in the program's variable space. The computing then becomes a sequential decision making problem, solved with reinforcement learning (RL), and analyzed with Lyapunov stability theory to assess the agent's resilience and progression to the goal. We do this through a case study on a quintessential computer science problem, array sorting. Evaluations show that our RL sorting agent makes steady progress to an asymptotically stable goal, is resilient to faulty components, and performs less array manipulations than traditional Quicksort and Bubble sort.