 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPDARTS: Resource-Aware Progressive Differentiable Architecture Search
Nov 08, 2019
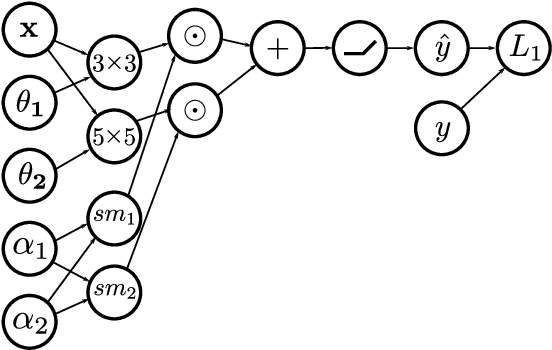

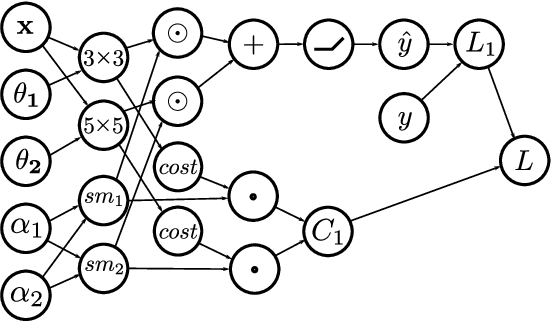
Early neural network architectures were designed by so-called "grad student descent". Since then, the field of Neural Architecture Search (NAS) has developed with the goal of algorithmically designing architectures tailored for a dataset of interest. Recently, gradient-based NAS approaches have been created to rapidly perform the search. Gradient-based approaches impose more structure on the search, compared to alternative NAS methods, enabling faster search phase optimization. In the real-world, neural architecture performance is measured by more than just high accuracy. There is increasing need for efficient neural architectures, where resources such as model size or latency must also be considered. Gradient-based NAS is also suitable for such multi-objective optimization. In this work we extend a popular gradient-based NAS method to support one or more resource costs. We then perform in-depth analysis on the discovery of architectures satisfying single-resource constraints for classification of CIFAR-10.
Distillation Strategies for Proximal Policy Optimization
Jan 23, 2019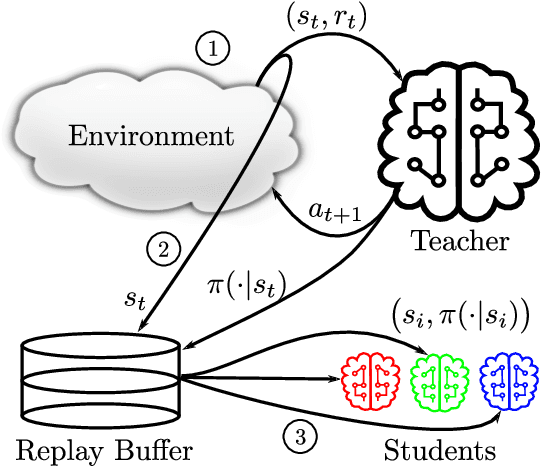
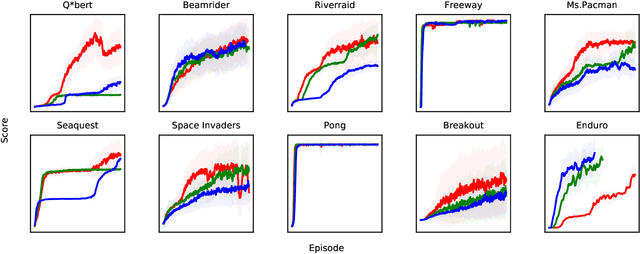
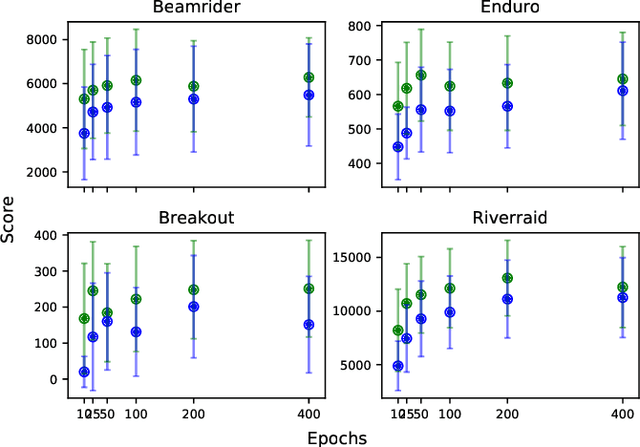
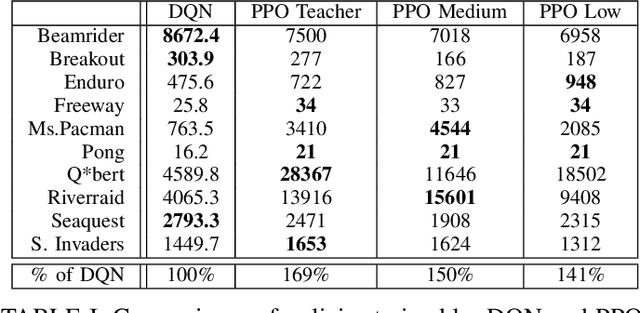
Vision-based deep reinforcement learning (RL), similar to deep learning, typically obtains a performance benefit by using high capacity and relatively large convolutional neural networks (CNN). However, a large network leads to higher inference costs (power, latency, silicon area, MAC count). Many inference optimization have been developed for CNNs. Some optimization techniques offer theoretical efficiency, but designing actual hardware to support them is difficult. On the other hand, "distillation" is a simple general-purpose optimization technique which is broadly applicable for transferring knowledge from a trained, high capacity, teacher network to an untrained, low capacity, student network. "DQN distillation" extended the original distillation idea to transfer information stored in a high performance, high capacity teacher Q-function trained via the Deep Q-Learning (DQN) algorithm. Our work adapts the DQN distillation work to the actor-critic Proximal Policy Optimization algorithm. PPO is simple to implement and has much higher performance than the seminal DQN algorithm. We show that a distilled PPO student can attain far higher performance compared to a DQN teacher. We also show that a low capacity distilled student is generally able to outperform a low capacity agent that directly trains in the environment. Finally, we show that distillation, followed by "fine-tuning" in the environment, enables the distilled PPO student to achieve parity with teacher performance. In general, the lessons learned in this work should transfer to other actor-critic RL algorithms.
Visual Diagnostics for Deep Reinforcement Learning Policy Development
Sep 26, 2018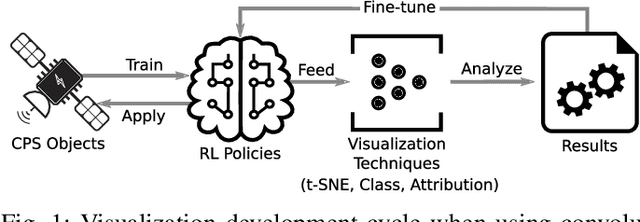


Modern vision-based reinforcement learning techniques often use convolutional neural networks (CNN) as universal function approximators to choose which action to take for a given visual input. Until recently, CNNs have been treated like black-box functions, but this mindset is especially dangerous when used for control in safety-critical settings. In this paper, we present our extensions of CNN visualization algorithms to the domain of vision-based reinforcement learning. We use a simulated drone environment as an example scenario. These visualization algorithms are an important tool for behavior introspection and provide insight into the qualities and flaws of trained policies when interacting with the physical world. A video may be seen at https://sites.google.com/view/drlvisual .