 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization in Binary Communication Networks for Neuromorphic Deployment
Apr 21, 2020

Training neural networks for neuromorphic deployment is non-trivial. There have been a variety of approaches proposed to adapt back-propagation or back-propagation-like algorithms appropriate for training. Considering that these networks often have very different performance characteristics than traditional neural networks, it is often unclear how to set either the network topology or the hyperparameters to achieve optimal performance. In this work, we introduce a Bayesian approach for optimizing the hyperparameters of an algorithm for training binary communication networks that can be deployed to neuromorphic hardware. We show that by optimizing the hyperparameters on this algorithm for each dataset, we can achieve improvements in accuracy over the previous state-of-the-art for this algorithm on each dataset (by up to 15 percent). This jump in performance continues to emphasize the potential when converting traditional neural networks to binary communication applicable to neuromorphic hardware.
Multi-Objective Optimization for Size and Resilience of Spiking Neural Networks
Feb 04, 2020
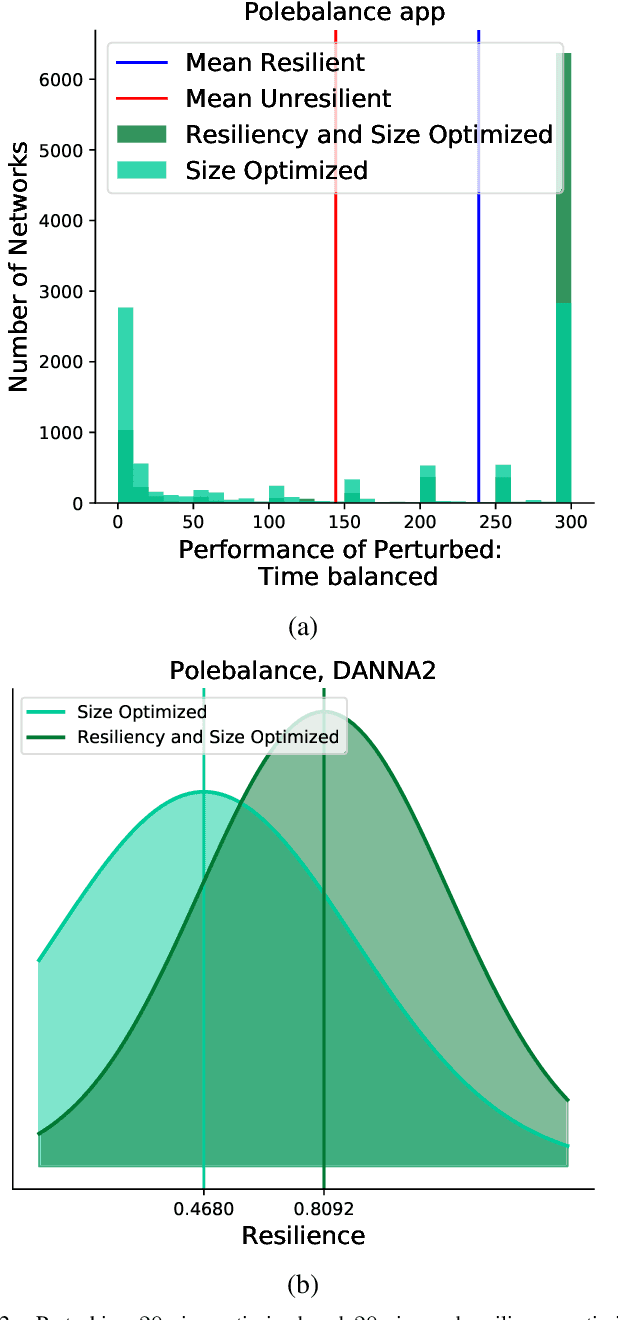
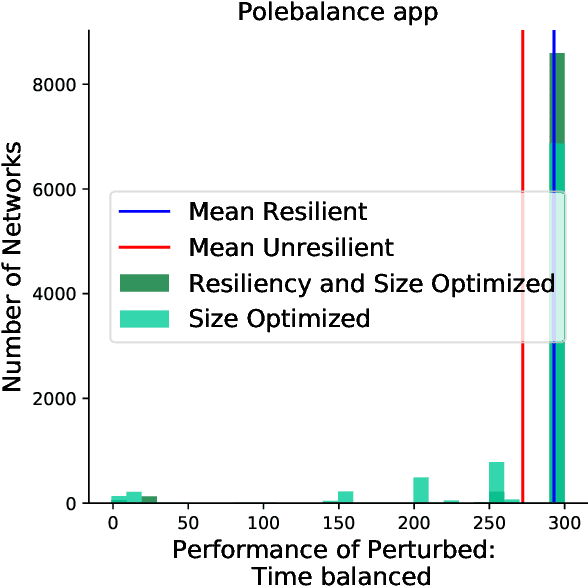
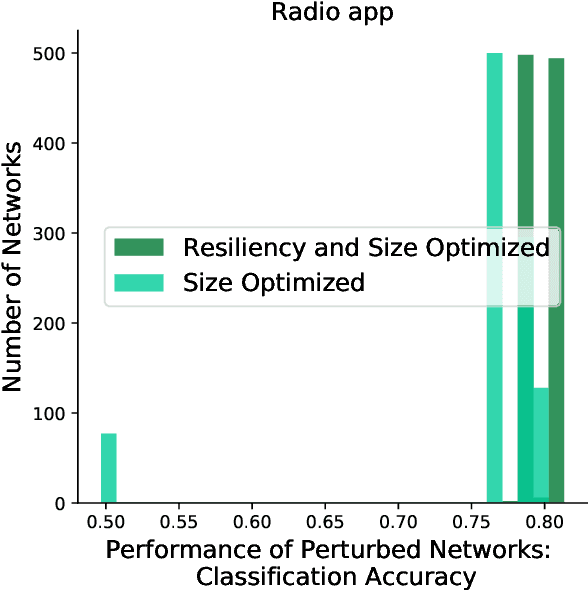
Inspired by the connectivity mechanisms in the brain, neuromorphic computing architectures model Spiking Neural Networks (SNNs) in silicon. As such, neuromorphic architectures are designed and developed with the goal of having small, low power chips that can perform control and machine learning tasks. However, the power consumption of the developed hardware can greatly depend on the size of the network that is being evaluated on the chip. Furthermore, the accuracy of a trained SNN that is evaluated on chip can change due to voltage and current variations in the hardware that perturb the learned weights of the network. While efforts are made on the hardware side to minimize those perturbations, a software based strategy to make the deployed networks more resilient can help further alleviate that issue. In this work, we study Spiking Neural Networks in two neuromorphic architecture implementations with the goal of decreasing their size, while at the same time increasing their resiliency to hardware faults. We leverage an evolutionary algorithm to train the SNNs and propose a multiobjective fitness function to optimize the size and resiliency of the SNN. We demonstrate that this strategy leads to well-performing, small-sized networks that are more resilient to hardware faults.
Exascale Deep Learning to Accelerate Cancer Research
Sep 26, 2019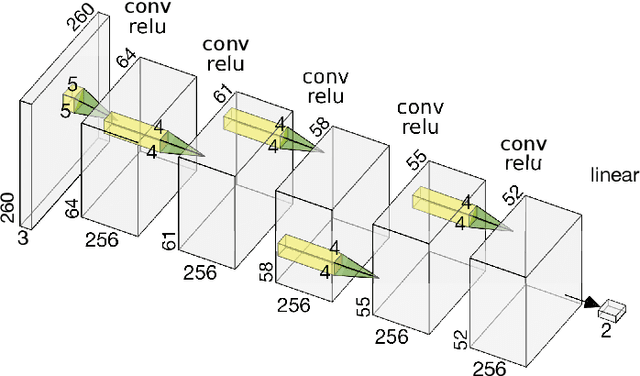
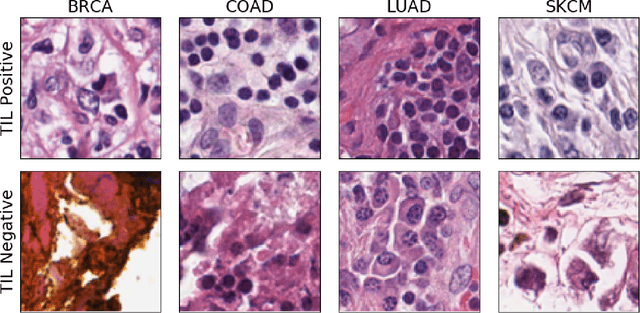
Deep learning, through the use of neural networks, has demonstrated remarkable ability to automate many routine tasks when presented with sufficient data for training. The neural network architecture (e.g. number of layers, types of layers, connections between layers, etc.) plays a critical role in determining what, if anything, the neural network is able to learn from the training data. The trend for neural network architectures, especially those trained on ImageNet, has been to grow ever deeper and more complex. The result has been ever increasing accuracy on benchmark datasets with the cost of increased computational demands. In this paper we demonstrate that neural network architectures can be automatically generated, tailored for a specific application, with dual objectives: accuracy of prediction and speed of prediction. Using MENNDL--an HPC-enabled software stack for neural architecture search--we generate a neural network with comparable accuracy to state-of-the-art networks on a cancer pathology dataset that is also $16\times$ faster at inference. The speedup in inference is necessary because of the volume and velocity of cancer pathology data; specifically, the previous state-of-the-art networks are too slow for individual researchers without access to HPC systems to keep pace with the rate of data generation. Our new model enables researchers with modest computational resources to analyze newly generated data faster than it is collected.
Deep Learning for Vertex Reconstruction of Neutrino-Nucleus Interaction Events with Combined Energy and Time Data
Feb 02, 2019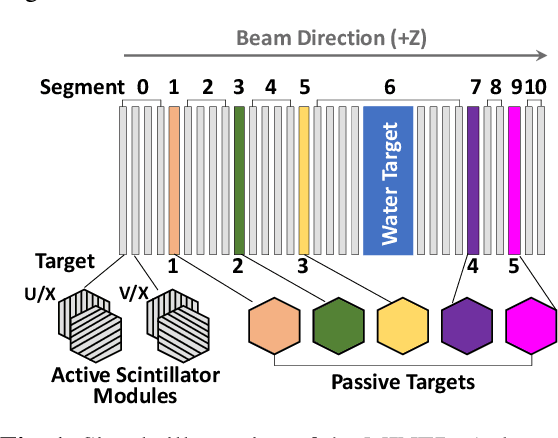
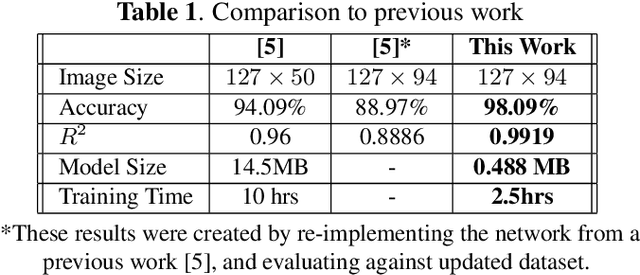
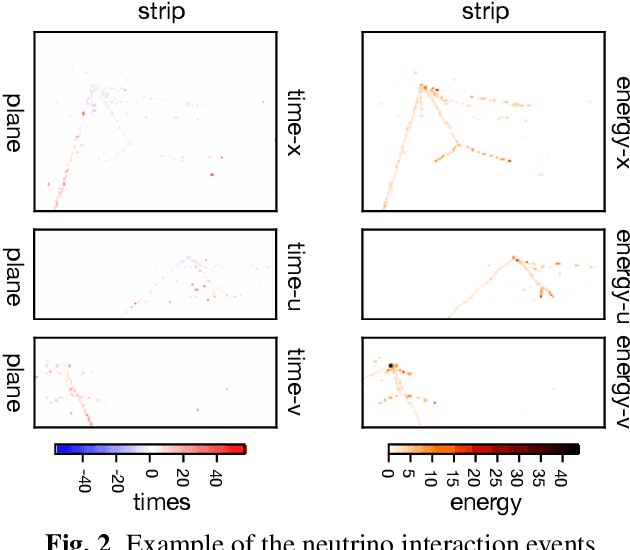
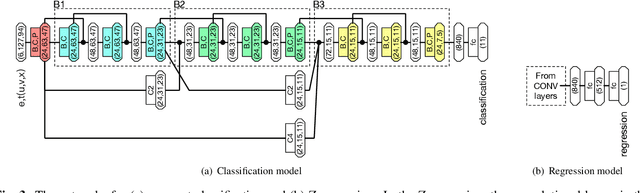
We present a deep learning approach for vertex reconstruction of neutrino-nucleus interaction events, a problem in the domain of high energy physics. In this approach, we combine both energy and timing data that are collected in the MINERvA detector to perform classification and regression tasks. We show that the resulting network achieves higher accuracy than previous results while requiring a smaller model size and less training time. In particular, the proposed model outperforms the state-of-the-art by 4.00% on classification accuracy. For the regression task, our model achieves 0.9919 on the coefficient of determination, higher than the previous work (0.96).
A Study of Complex Deep Learning Networks on High Performance, Neuromorphic, and Quantum Computers
Jul 13, 2017
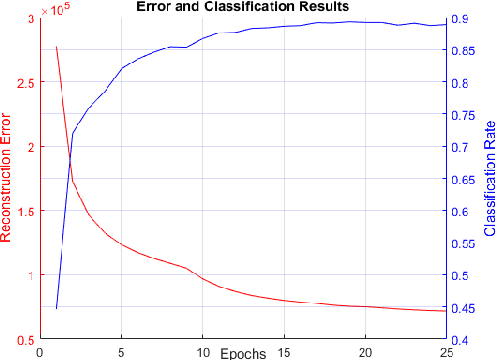
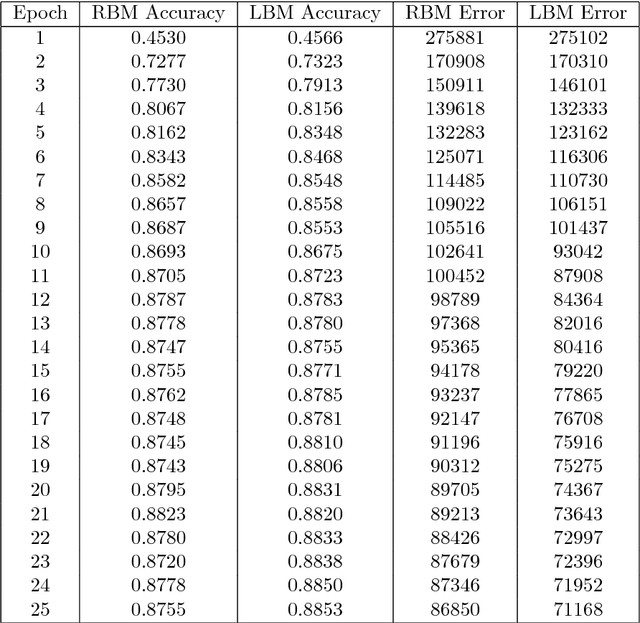
Current Deep Learning approaches have been very successful using convolutional neural networks (CNN) trained on large graphical processing units (GPU)-based computers. Three limitations of this approach are: 1) they are based on a simple layered network topology, i.e., highly connected layers, without intra-layer connections; 2) the networks are manually configured to achieve optimal results, and 3) the implementation of neuron model is expensive in both cost and power. In this paper, we evaluate deep learning models using three different computing architectures to address these problems: quantum computing to train complex topologies, high performance computing (HPC) to automatically determine network topology, and neuromorphic computing for a low-power hardware implementation. We use the MNIST dataset for our experiment, due to input size limitations of current quantum computers. Our results show the feasibility of using the three architectures in tandem to address the above deep learning limitations. We show a quantum computer can find high quality values of intra-layer connections weights, in a tractable time as the complexity of the network increases; a high performance computer can find optimal layer-based topologies; and a neuromorphic computer can represent the complex topology and weights derived from the other architectures in low power memristive hardware.
A Survey of Neuromorphic Computing and Neural Networks in Hardware
May 19, 2017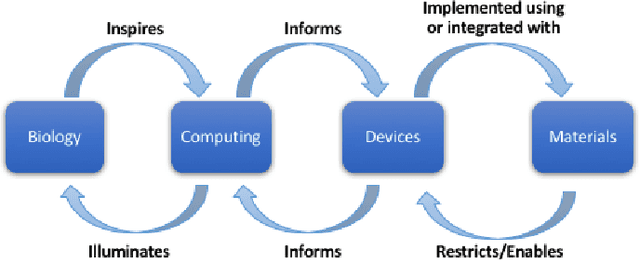
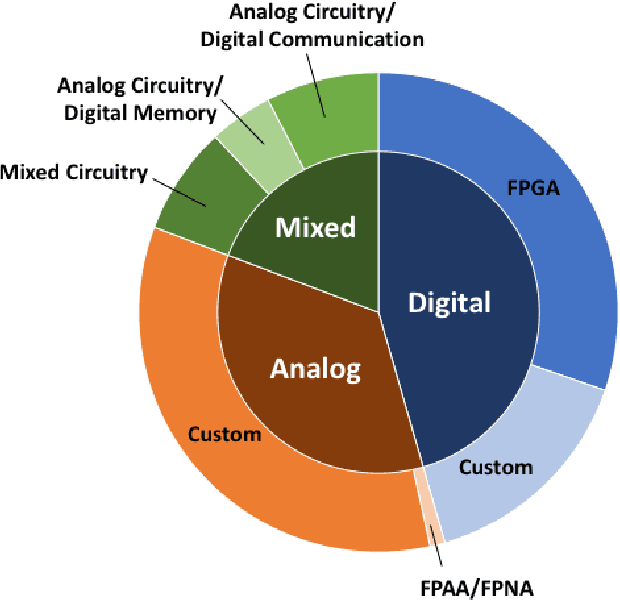
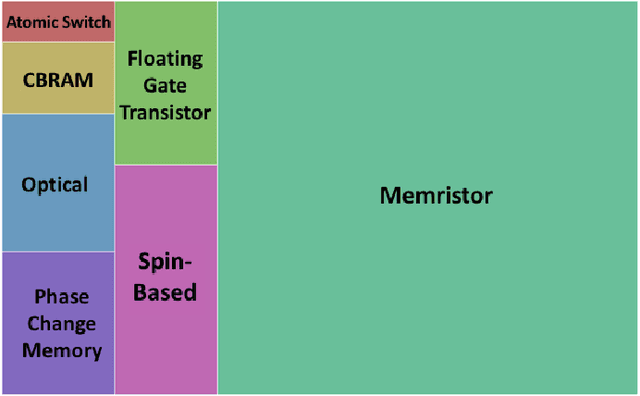
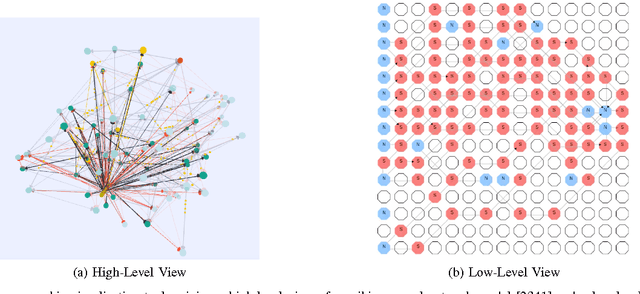
Neuromorphic computing has come to refer to a variety of brain-inspired computers, devices, and models that contrast the pervasive von Neumann computer architecture. This biologically inspired approach has created highly connected synthetic neurons and synapses that can be used to model neuroscience theories as well as solve challenging machine learning problems. The promise of the technology is to create a brain-like ability to learn and adapt, but the technical challenges are significant, starting with an accurate neuroscience model of how the brain works, to finding materials and engineering breakthroughs to build devices to support these models, to creating a programming framework so the systems can learn, to creating applications with brain-like capabilities. In this work, we provide a comprehensive survey of the research and motivations for neuromorphic computing over its history. We begin with a 35-year review of the motivations and drivers of neuromorphic computing, then look at the major research areas of the field, which we define as neuro-inspired models, algorithms and learning approaches, hardware and devices, supporting systems, and finally applications. We conclude with a broad discussion on the major research topics that need to be addressed in the coming years to see the promise of neuromorphic computing fulfilled. The goals of this work are to provide an exhaustive review of the research conducted in neuromorphic computing since the inception of the term, and to motivate further work by illuminating gaps in the field where new research is needed.