 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyxis: An Open-Source Performance Dataset of Sparse Accelerators
Oct 08, 2021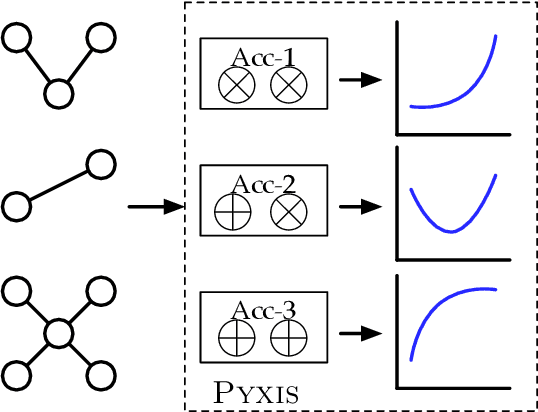

Specialized accelerators provide gains of performance and efficiency in specific domains of applications. Sparse data structures or/and representations exist in a wide range of applications. However, it is challenging to design accelerators for sparse applications because no analytic architecture or performance-level models are able to fully capture the spectrum of the sparse data. Accelerator researchers rely on real execution to get precise feedback for their designs. In this work, we present PYXIS, a performance dataset for specialized accelerators on sparse data. PYXIS collects accelerator designs and real execution performance statistics. Currently, there are 73.8 K instances in PYXIS. PYXIS is open-source, and we are constantly growing PYXIS with new accelerator designs and performance statistics. PYXIS can benefit researchers in the fields of accelerator, architecture, performance, algorithm, and many related topics.
SparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training
Jul 21, 2020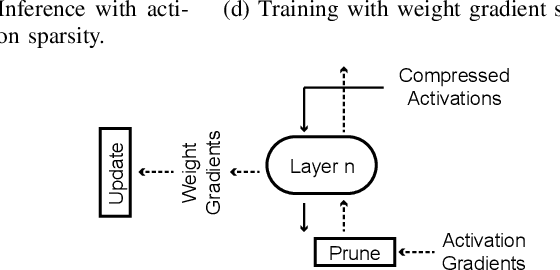
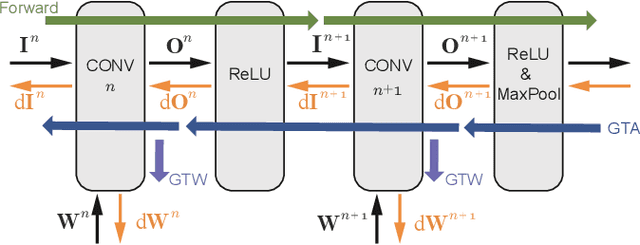
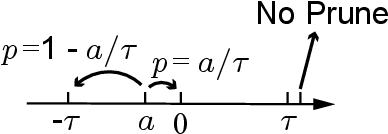
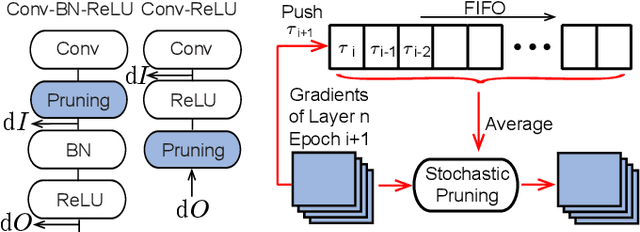
Training Convolutional Neural Networks (CNNs) usually requires a large number of computational resources. In this paper, \textit{SparseTrain} is proposed to accelerate CNN training by fully exploiting the sparsity. It mainly involves three levels of innovations: activation gradients pruning algorithm, sparse training dataflow, and accelerator architecture. By applying a stochastic pruning algorithm on each layer, the sparsity of back-propagation gradients can be increased dramatically without degrading training accuracy and convergence rate. Moreover, to utilize both \textit{natural sparsity} (resulted from ReLU or Pooling layers) and \textit{artificial sparsity} (brought by pruning algorithm), a sparse-aware architecture is proposed for training acceleration. This architecture supports forward and back-propagation of CNN by adopting 1-Dimensional convolution dataflow. We have built %a simple compiler to map CNNs topology onto \textit{SparseTrain}, and a cycle-accurate architecture simulator to evaluate the performance and efficiency based on the synthesized design with $14nm$ FinFET technologies. Evaluation results on AlexNet/ResNet show that \textit{SparseTrain} could achieve about $2.7 \times$ speedup and $2.2 \times$ energy efficiency improvement on average compared with the original training process.
Deep Learning for Vertex Reconstruction of Neutrino-Nucleus Interaction Events with Combined Energy and Time Data
Feb 02, 2019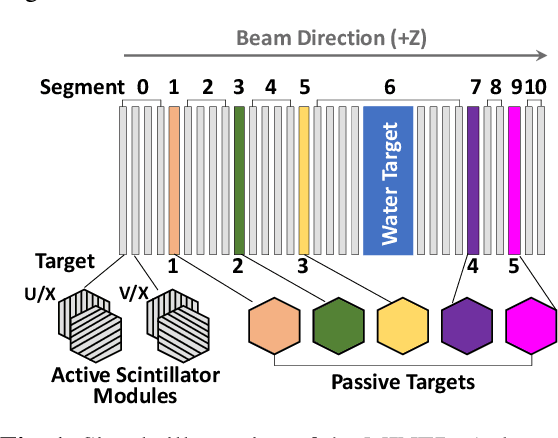
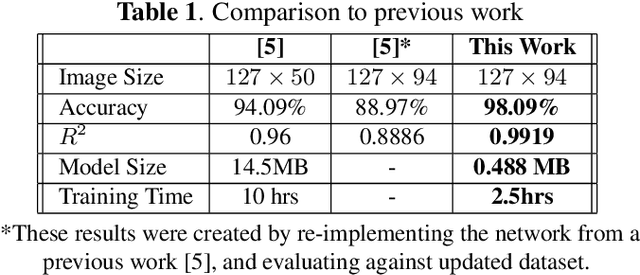
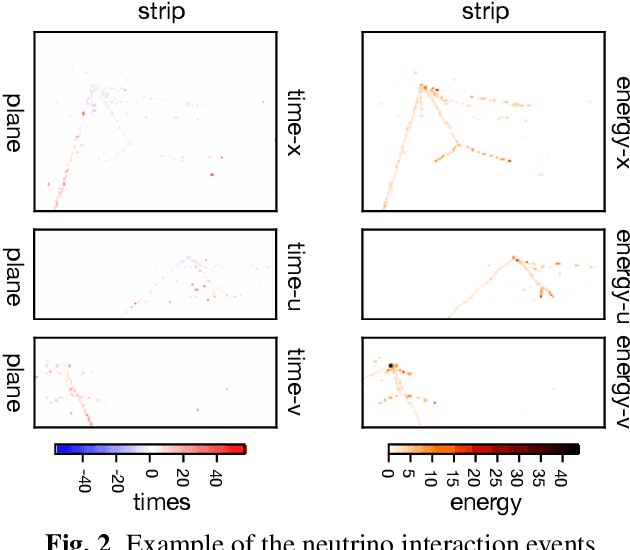
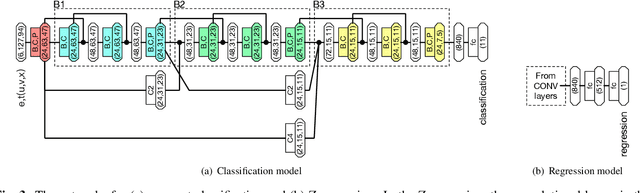
We present a deep learning approach for vertex reconstruction of neutrino-nucleus interaction events, a problem in the domain of high energy physics. In this approach, we combine both energy and timing data that are collected in the MINERvA detector to perform classification and regression tasks. We show that the resulting network achieves higher accuracy than previous results while requiring a smaller model size and less training time. In particular, the proposed model outperforms the state-of-the-art by 4.00% on classification accuracy. For the regression task, our model achieves 0.9919 on the coefficient of determination, higher than the previous work (0.96).
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array
Jan 07, 2019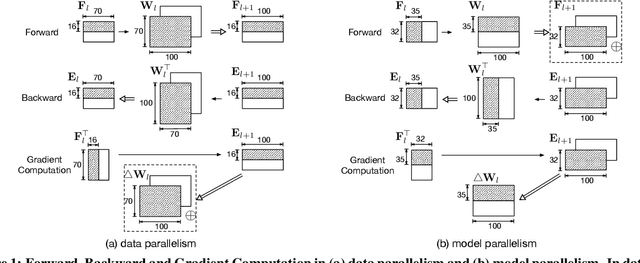
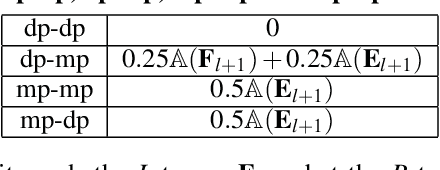
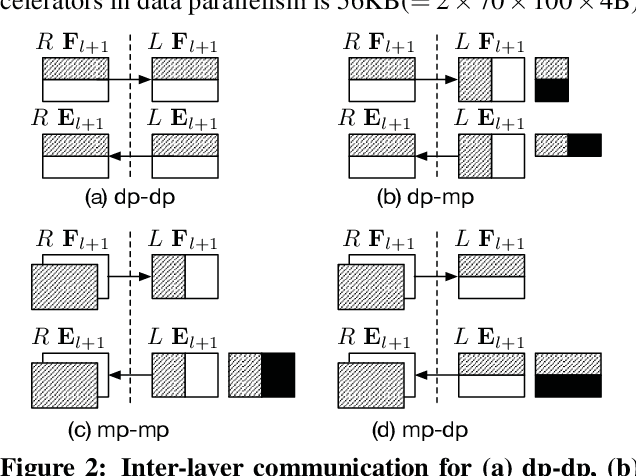
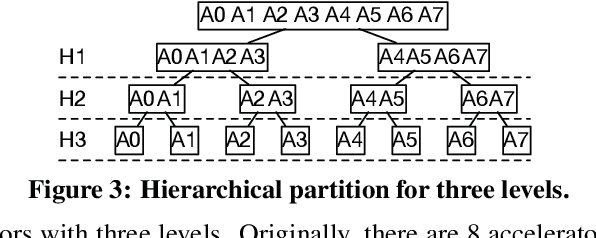
With the rise of artificial intelligence in recent years, Deep Neural Networks (DNNs) have been widely used in many domains. To achieve high performance and energy efficiency, hardware acceleration (especially inference) of DNNs is intensively studied both in academia and industry. However, we still face two challenges: large DNN models and datasets, which incur frequent off-chip memory accesses; and the training of DNNs, which is not well-explored in recent accelerator designs. To truly provide high throughput and energy efficient acceleration for the training of deep and large models, we inevitably need to use multiple accelerators to explore the coarse-grain parallelism, compared to the fine-grain parallelism inside a layer considered in most of the existing architectures. It poses the key research question to seek the best organization of computation and dataflow among accelerators. In this paper, we propose a solution HyPar to determine layer-wise parallelism for deep neural network training with an array of DNN accelerators. HyPar partitions the feature map tensors (input and output), the kernel tensors, the gradient tensors, and the error tensors for the DNN accelerators. A partition constitutes the choice of parallelism for weighted layers. The optimization target is to search a partition that minimizes the total communication during training a complete DNN. To solve this problem, we propose a communication model to explain the source and amount of communications. Then, we use a hierarchical layer-wise dynamic programming method to search for the partition for each layer.
DPatch: An Adversarial Patch Attack on Object Detectors
Sep 15, 2018
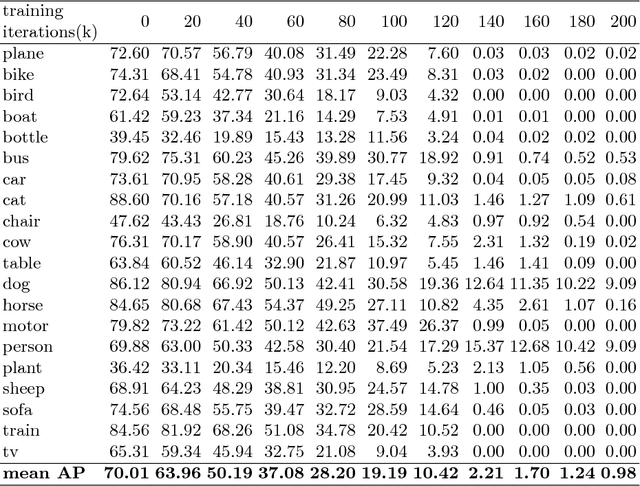
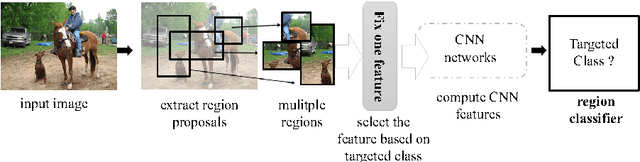
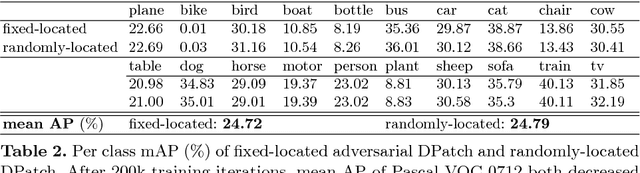
Object detectors have emerged as an indispensable module in modern computer vision systems. Their vulnerability to adversarial attacks thus become a vital issue to consider. In this work, we propose DPatch, a adversarial-patch-based attack towards mainstream object detectors (i.e., Faster R-CNN and YOLO). Unlike the original adversarial patch that only manipulates image-level classifier, our DPatch simultaneously optimizes the bounding box location and category targets so as to disable their predictions. Compared to prior works, DPatch has several appealing properties: (1) DPatch can perform both untargeted and targeted effective attacks, degrading the mAP of Faster R-CNN and YOLO from 70.0% and 65.7% down to below 1% respectively; (2) DPatch is small in size and its attacking effect is location-independent, making it very practical to implement real-world attacks; (3) DPatch demonstrates great transferability between different detector architectures. For example, DPatch that is trained on Faster R-CNN can effectively attack YOLO, and vice versa. Extensive evaluations imply that DPatch can perform effective attacks under black-box setup, i.e., even without the knowledge of the attacked network's architectures and parameters. The successful realization of DPatch also illustrates the intrinsic vulnerability of the modern detector architectures to such patch-based adversarial attacks.
Classification Accuracy Improvement for Neuromorphic Computing Systems with One-level Precision Synapses
Jan 07, 2017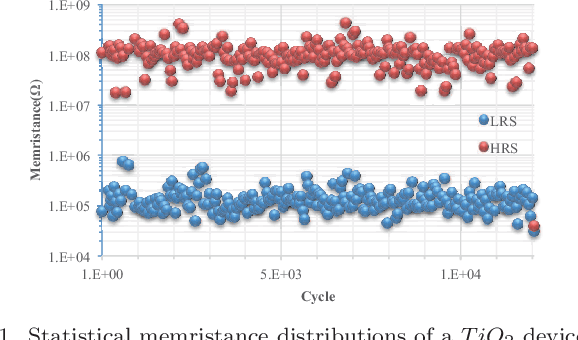
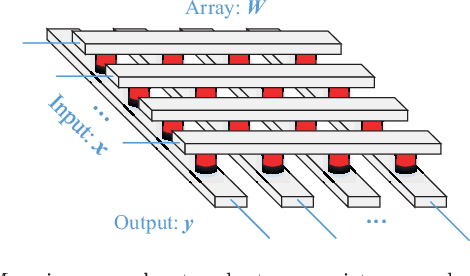
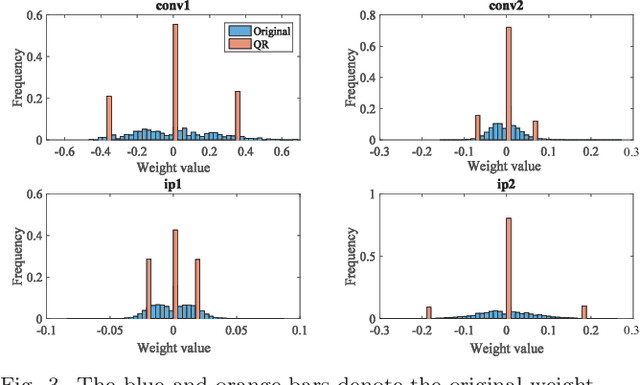
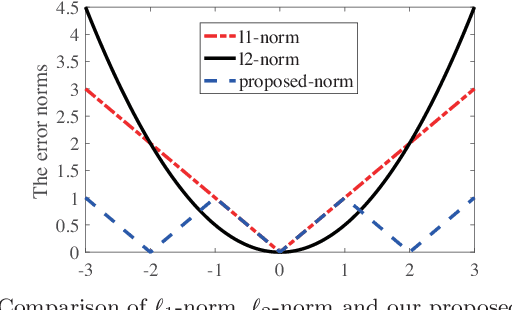
Brain inspired neuromorphic computing has demonstrated remarkable advantages over traditional von Neumann architecture for its high energy efficiency and parallel data processing. However, the limited resolution of synaptic weights degrades system accuracy and thus impedes the use of neuromorphic systems. In this work, we propose three orthogonal methods to learn synapses with one-level precision, namely, distribution-aware quantization, quantization regularization and bias tuning, to make image classification accuracy comparable to the state-of-the-art. Experiments on both multi-layer perception and convolutional neural networks show that the accuracy drop can be well controlled within 0.19% (5.53%) for MNIST (CIFAR-10) database, compared to an ideal system without quantization.