 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training
Paper and Code
Jul 21, 2020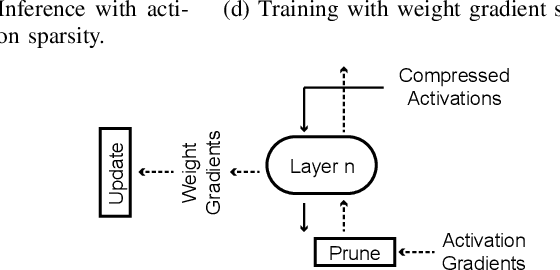
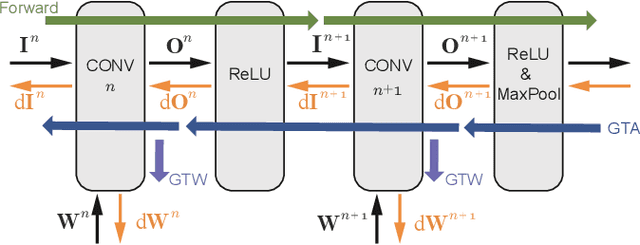
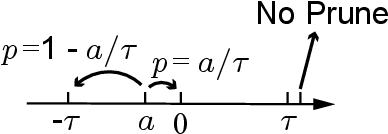
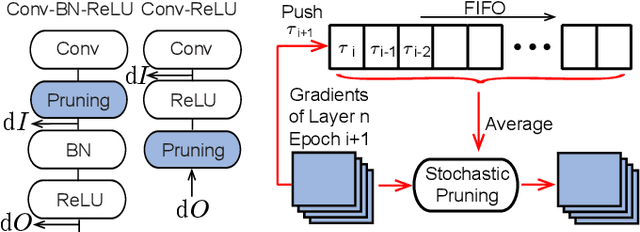
Training Convolutional Neural Networks (CNNs) usually requires a large number of computational resources. In this paper, \textit{SparseTrain} is proposed to accelerate CNN training by fully exploiting the sparsity. It mainly involves three levels of innovations: activation gradients pruning algorithm, sparse training dataflow, and accelerator architecture. By applying a stochastic pruning algorithm on each layer, the sparsity of back-propagation gradients can be increased dramatically without degrading training accuracy and convergence rate. Moreover, to utilize both \textit{natural sparsity} (resulted from ReLU or Pooling layers) and \textit{artificial sparsity} (brought by pruning algorithm), a sparse-aware architecture is proposed for training acceleration. This architecture supports forward and back-propagation of CNN by adopting 1-Dimensional convolution dataflow. We have built %a simple compiler to map CNNs topology onto \textit{SparseTrain}, and a cycle-accurate architecture simulator to evaluate the performance and efficiency based on the synthesized design with $14nm$ FinFET technologies. Evaluation results on AlexNet/ResNet show that \textit{SparseTrain} could achieve about $2.7 \times$ speedup and $2.2 \times$ energy efficiency improvement on average compared with the original training process.