 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2Engine: A Novel Systolic Architecture for Sparse Convolutional Neural Networks
Jun 15, 2021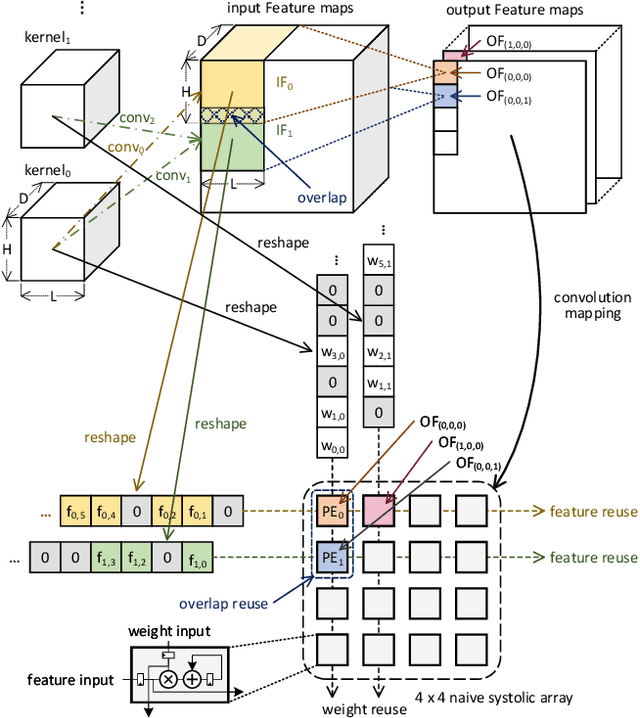
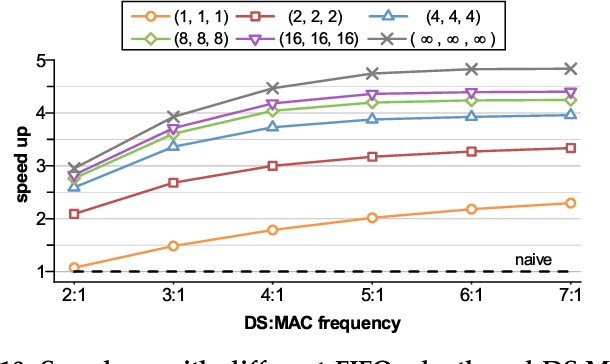
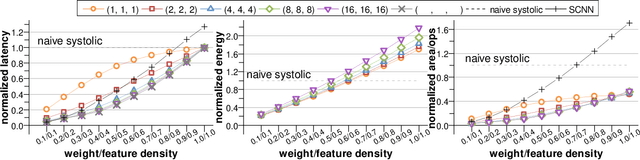
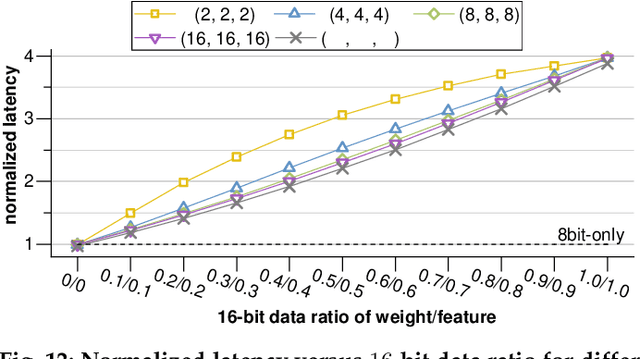
Convolutional neural networks (CNNs) have achieved great success in performing cognitive tasks. However, execution of CNNs requires a large amount of computing resources and generates heavy memory traffic, which imposes a severe challenge on computing system design. Through optimizing parallel executions and data reuse in convolution, systolic architecture demonstrates great advantages in accelerating CNN computations. However, regular internal data transmission path in traditional systolic architecture prevents the systolic architecture from completely leveraging the benefits introduced by neural network sparsity. Deployment of fine-grained sparsity on the existing systolic architectures is greatly hindered by the incurred computational overheads. In this work, we propose S2Engine $-$ a novel systolic architecture that can fully exploit the sparsity in CNNs with maximized data reuse. S2Engine transmits compressed data internally and allows each processing element to dynamically select an aligned data from the compressed dataflow in convolution. Compared to the naive systolic array, S2Engine achieves about $3.2\times$ and about $3.0\times$ improvements on speed and energy efficiency, respectively.
* 13 pages, 17 figures
Optimizing Memory Efficiency of Graph Neural Networks on Edge Computing Platforms
Apr 12, 2021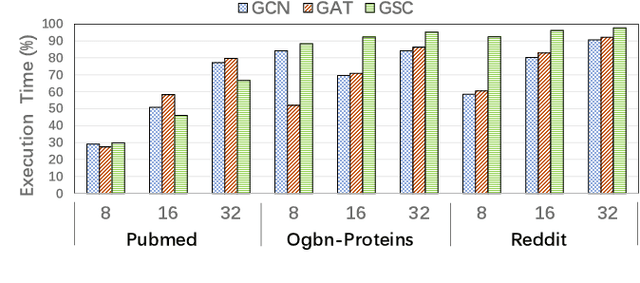
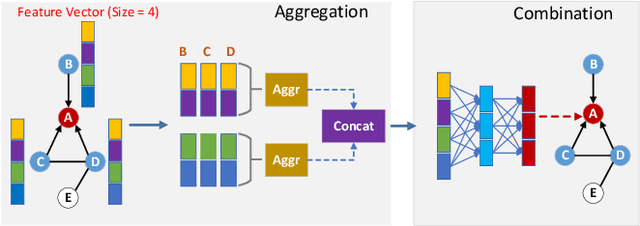
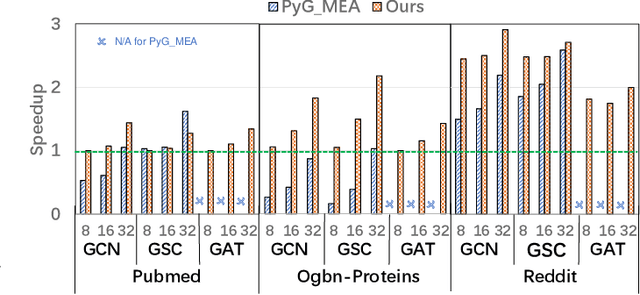
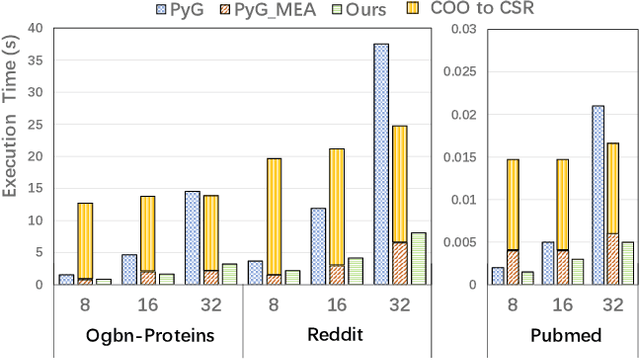
Graph neural networks (GNN) have achieved state-of-the-art performance on various industrial tasks. However, the poor efficiency of GNN inference and frequent Out-Of-Memory (OOM) problem limit the successful application of GNN on edge computing platforms. To tackle these problems, a feature decomposition approach is proposed for memory efficiency optimization of GNN inference. The proposed approach could achieve outstanding optimization on various GNN models, covering a wide range of datasets, which speeds up the inference by up to 3x. Furthermore, the proposed feature decomposition could significantly reduce the peak memory usage (up to 5x in memory efficiency improvement) and mitigate OOM problems during GNN inference.
SparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training
Jul 21, 2020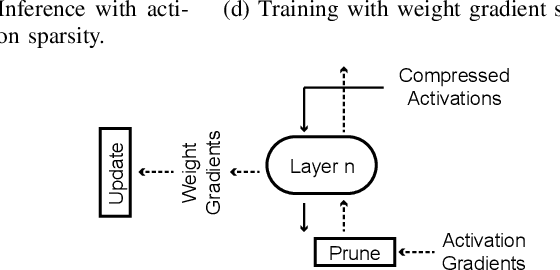
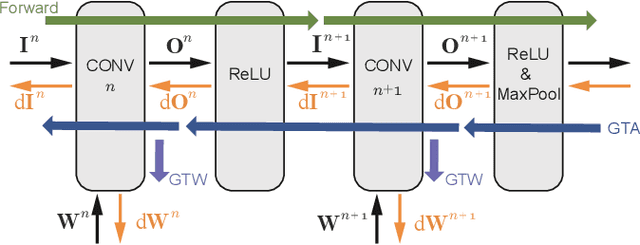
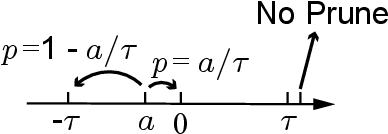
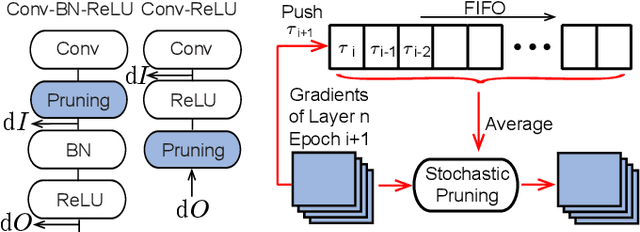
Training Convolutional Neural Networks (CNNs) usually requires a large number of computational resources. In this paper, \textit{SparseTrain} is proposed to accelerate CNN training by fully exploiting the sparsity. It mainly involves three levels of innovations: activation gradients pruning algorithm, sparse training dataflow, and accelerator architecture. By applying a stochastic pruning algorithm on each layer, the sparsity of back-propagation gradients can be increased dramatically without degrading training accuracy and convergence rate. Moreover, to utilize both \textit{natural sparsity} (resulted from ReLU or Pooling layers) and \textit{artificial sparsity} (brought by pruning algorithm), a sparse-aware architecture is proposed for training acceleration. This architecture supports forward and back-propagation of CNN by adopting 1-Dimensional convolution dataflow. We have built %a simple compiler to map CNNs topology onto \textit{SparseTrain}, and a cycle-accurate architecture simulator to evaluate the performance and efficiency based on the synthesized design with $14nm$ FinFET technologies. Evaluation results on AlexNet/ResNet show that \textit{SparseTrain} could achieve about $2.7 \times$ speedup and $2.2 \times$ energy efficiency improvement on average compared with the original training process.
Accelerating CNN Training by Sparsifying Activation Gradients
Aug 01, 2019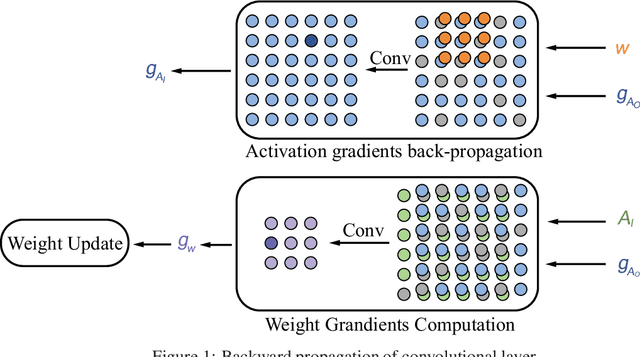
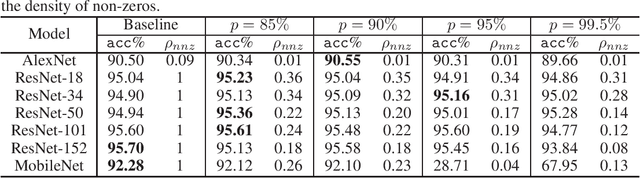
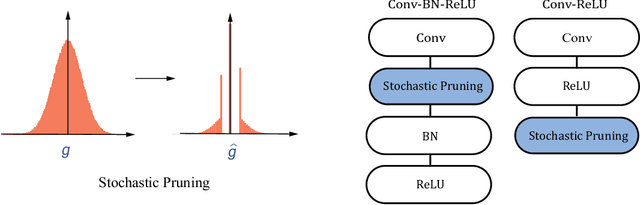
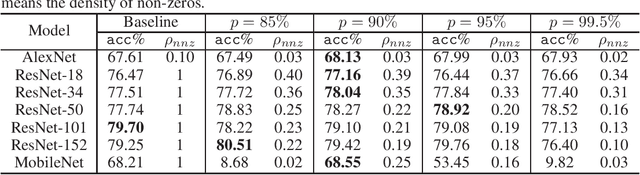
Gradients to activations get involved in most of the calculations during back propagation procedure of Convolution Neural Networks (CNNs) training. However, an important known observation is that the majority of these gradients are close to zero, imposing little impact on weights update. These gradients can be then pruned to achieve high gradient sparsity during CNNs training and reduce the computational cost. In particular, we randomly change a gradient to zero or a threshold value if the gradient is below the threshold which is determined by the statistical distribution of activation gradients. We also theoretically proved that the training convergence of the CNN model can be guaranteed when the above activation gradient sparsification method is applied. We evaluated our method on AlexNet, MobileNet, ResNet-{18, 34, 50, 101, 152} with CIFAR-{10, 100} and ImageNet datasets. Experimental results show that our method can substantially reduce the computational cost with negligible accuracy loss or even accuracy improvement. Finally, we analyzed the benefits that the sparsity of activation gradients introduced in detail.