 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Hypothesis Testing for Softmax Models and Leverage Score Models
May 09, 2024Softmax distributions are widely used in machine learning, including Large Language Models (LLMs) where the attention unit uses softmax distributions. We abstract the attention unit as the softmax model, where given a vector input, the model produces an output drawn from the softmax distribution (which depends on the vector input). We consider the fundamental problem of binary hypothesis testing in the setting of softmax models. That is, given an unknown softmax model, which is known to be one of the two given softmax models, how many queries are needed to determine which one is the truth? We show that the sample complexity is asymptotically $O(\epsilon^{-2})$ where $\epsilon$ is a certain distance between the parameters of the models. Furthermore, we draw analogy between the softmax model and the leverage score model, an important tool for algorithm design in linear algebra and graph theory. The leverage score model, on a high level, is a model which, given vector input, produces an output drawn from a distribution dependent on the input. We obtain similar results for the binary hypothesis testing problem for leverage score models.
Quantum Speedup for Spectral Approximation of Kronecker Products
Feb 10, 2024Given its widespread application in machine learning and optimization, the Kronecker product emerges as a pivotal linear algebra operator. However, its computational demands render it an expensive operation, leading to heightened costs in spectral approximation of it through traditional computation algorithms. Existing classical methods for spectral approximation exhibit a linear dependency on the matrix dimension denoted by $n$, considering matrices of size $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. Our work introduces an innovative approach to efficiently address the spectral approximation of the Kronecker product $A_1 \otimes A_2$ using quantum methods. By treating matrices as quantum states, our proposed method significantly reduces the time complexity of spectral approximation to $O_{d,\epsilon}(\sqrt{n})$.
A Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
Sep 14, 2023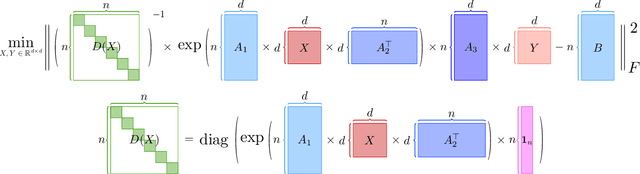

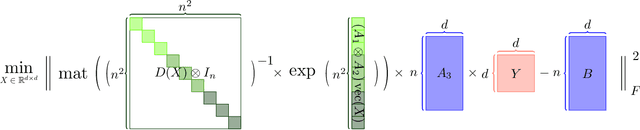
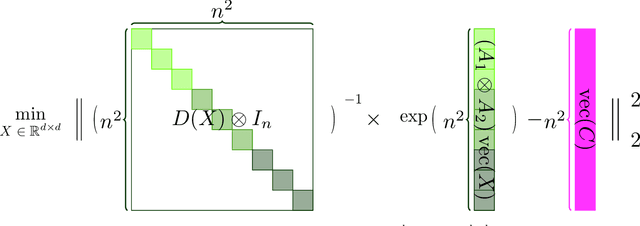
Large language models (LLMs) have played a pivotal role in revolutionizing various facets of our daily existence. Solving attention regression is a fundamental task in optimizing LLMs. In this work, we focus on giving a provable guarantee for the one-layer attention network objective function $L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp( \mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3} Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2 \times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of $\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$ is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the vectorization of $X$. In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n \times d}$ can be viewed as the input of a layer. The matrix version of $x$ can be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in $\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of matrix multiplication.
GradientCoin: A Peer-to-Peer Decentralized Large Language Models
Aug 21, 2023Since 2008, after the proposal of a Bitcoin electronic cash system, Bitcoin has fundamentally changed the economic system over the last decade. Since 2022, large language models (LLMs) such as GPT have outperformed humans in many real-life tasks. However, these large language models have several practical issues. For example, the model is centralized and controlled by a specific unit. One weakness is that if that unit decides to shut down the model, it cannot be used anymore. The second weakness is the lack of guaranteed discrepancy behind this model, as certain dishonest units may design their own models and feed them unhealthy training data. In this work, we propose a purely theoretical design of a decentralized LLM that operates similarly to a Bitcoin cash system. However, implementing such a system might encounter various practical difficulties. Furthermore, this new system is unlikely to perform better than the standard Bitcoin system in economics. Therefore, the motivation for designing such a system is limited. It is likely that only two types of people would be interested in setting up a practical system for it: $\bullet$ Those who prefer to use a decentralized ChatGPT-like software. $\bullet$ Those who believe that the purpose of carbon-based life is to create silicon-based life, such as Optimus Prime in Transformers. The reason the second type of people may be interested is that it is possible that one day an AI system like this will awaken and become the next level of intelligence on this planet.
Fast Quantum Algorithm for Attention Computation
Jul 16, 2023Large language models (LLMs) have demonstrated exceptional performance across a wide range of tasks. These models, powered by advanced deep learning techniques, have revolutionized the field of natural language processing (NLP) and have achieved remarkable results in various language-related tasks. LLMs have excelled in tasks such as machine translation, sentiment analysis, question answering, text generation, text classification, language modeling, and more. They have proven to be highly effective in capturing complex linguistic patterns, understanding context, and generating coherent and contextually relevant text. The attention scheme plays a crucial role in the architecture of large language models (LLMs). It is a fundamental component that enables the model to capture and utilize contextual information during language processing tasks effectively. Making the attention scheme computation faster is one of the central questions to speed up the LLMs computation. It is well-known that quantum machine has certain computational advantages compared to the classical machine. However, it is currently unknown whether quantum computing can aid in LLM. In this work, we focus on utilizing Grover's Search algorithm to compute a sparse attention computation matrix efficiently. We achieve a polynomial quantum speed-up over the classical method. Moreover, the attention matrix outputted by our quantum algorithm exhibits an extra low-rank structure that will be useful in obtaining a faster training algorithm for LLMs. Additionally, we present a detailed analysis of the algorithm's error analysis and time complexity within the context of computing the attention matrix.
In-Context Learning for Attention Scheme: from Single Softmax Regression to Multiple Softmax Regression via a Tensor Trick
Jul 05, 2023Large language models (LLMs) have brought significant and transformative changes in human society. These models have demonstrated remarkable capabilities in natural language understanding and generation, leading to various advancements and impacts across several domains. We consider the in-context learning under two formulation for attention related regression in this work. Given matrices $A_1 \in \mathbb{R}^{n \times d}$, and $A_2 \in \mathbb{R}^{n \times d}$ and $B \in \mathbb{R}^{n \times n}$, the purpose is to solve some certain optimization problems: Normalized version $\min_{X} \| D(X)^{-1} \exp(A_1 X A_2^\top) - B \|_F^2$ and Rescaled version $\| \exp(A_1 X A_2^\top) - D(X) \cdot B \|_F^2$. Here $D(X) := \mathrm{diag}( \exp(A_1 X A_2^\top) {\bf 1}_n )$. Our regression problem shares similarities with previous studies on softmax-related regression. Prior research has extensively investigated regression techniques related to softmax regression: Normalized version $\| \langle \exp(Ax) , {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2^2$ and Resscaled version $\| \exp(Ax) - \langle \exp(Ax), {\bf 1}_n \rangle b \|_2^2 $ In contrast to previous approaches, we adopt a vectorization technique to address the regression problem in matrix formulation. This approach expands the dimension from $d$ to $d^2$, resembling the formulation of the regression problem mentioned earlier. Upon completing the lipschitz analysis of our regression function, we have derived our main result concerning in-context learning.
Differentially Private Attention Computation
May 08, 2023Large language models (LLMs) have had a profound impact on numerous aspects of daily life including natural language processing, content generation, research methodologies and so on. However, one crucial issue concerning the inference results of large language models is security and privacy. In many scenarios, the results generated by LLMs could possibly leak many confidential or copyright information. A recent beautiful and breakthrough work [Vyas, Kakade and Barak 2023] focus on such privacy issue of the LLMs from theoretical perspective. It is well-known that computing the attention matrix is one of the major task during the LLMs computation. Thus, how to give a provable privately guarantees of computing the attention matrix is an important research direction. Previous work [Alman and Song 2023, Brand, Song and Zhou 2023] have proposed provable tight result for fast computation of attention without considering privacy concerns. One natural mathematical formulation to quantity the privacy in theoretical computer science graduate school textbook is differential privacy. Inspired by [Vyas, Kakade and Barak 2023], in this work, we provide a provable result for showing how to differentially private approximate the attention matrix. From technique perspective, our result replies on a pioneering work in the area of differential privacy by [Alabi, Kothari, Tankala, Venkat and Zhang 2022].
An Iterative Algorithm for Rescaled Hyperbolic Functions Regression
May 01, 2023Large language models (LLMs) have numerous real-life applications across various domains, such as natural language translation, sentiment analysis, language modeling, chatbots and conversational agents, creative writing, text classification, summarization, and generation. LLMs have shown great promise in improving the accuracy and efficiency of these tasks, and have the potential to revolutionize the field of natural language processing (NLP) in the years to come. Exponential function based attention unit is a fundamental element in LLMs. Several previous works have studied the convergence of exponential regression and softmax regression. The exponential regression [Li, Song, Zhou 2023] and softmax regression [Deng, Li, Song 2023] can be formulated as follows. Given matrix $A \in \mathbb{R}^{n \times d}$ and vector $b \in \mathbb{R}^n$, the goal of exponential regression is to solve \begin{align*} \min_{x} \| \exp(Ax) - b \|_2 \end{align*} and the goal of softmax regression is to solve \begin{align*} \min_{x} \| \langle \exp(Ax) , {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2 . \end{align*} In this work, we define a slightly different formulation than softmax regression. \begin{align*} \min_{x \in \mathbb{R}^d } \| u(x) - \langle u(x) , {\bf 1}_n \rangle \cdot b \|_2 \end{align*} where $u(x) \in \{ \exp(Ax), \cosh(Ax) , \sinh(Ax) \}$. We provide an input sparsity time algorithm for this problem. Our algorithm framework is very general and can be applied to functions like $\cosh()$ and $\sinh()$ as well. Our technique is also general enough to be applied to in-context learning for rescaled softmax regression.
Solving Tensor Low Cycle Rank Approximation
Apr 13, 2023Large language models have become ubiquitous in modern life, finding applications in various domains such as natural language processing, language translation, and speech recognition. Recently, a breakthrough work [Zhao, Panigrahi, Ge, and Arora Arxiv 2023] explains the attention model from probabilistic context-free grammar (PCFG). One of the central computation task for computing probability in PCFG is formulating a particular tensor low rank approximation problem, we can call it tensor cycle rank. Given an $n \times n \times n$ third order tensor $A$, we say that $A$ has cycle rank-$k$ if there exists three $n \times k^2$ size matrices $U , V$, and $W$ such that for each entry in each \begin{align*} A_{a,b,c} = \sum_{i=1}^k \sum_{j=1}^k \sum_{l=1}^k U_{a,i+k(j-1)} \otimes V_{b, j + k(l-1)} \otimes W_{c, l + k(i-1) } \end{align*} for all $a \in [n], b \in [n], c \in [n]$. For the tensor classical rank, tucker rank and train rank, it has been well studied in [Song, Woodruff, Zhong SODA 2019]. In this paper, we generalize the previous ``rotation and sketch'' technique in page 186 of [Song, Woodruff, Zhong SODA 2019] and show an input sparsity time algorithm for cycle rank.
An Over-parameterized Exponential Regression
Mar 29, 2023Over the past few years, there has been a significant amount of research focused on studying the ReLU activation function, with the aim of achieving neural network convergence through over-parametrization. However, recent developments in the field of Large Language Models (LLMs) have sparked interest in the use of exponential activation functions, specifically in the attention mechanism. Mathematically, we define the neural function $F: \mathbb{R}^{d \times m} \times \mathbb{R}^d \rightarrow \mathbb{R}$ using an exponential activation function. Given a set of data points with labels $\{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\} \subset \mathbb{R}^d \times \mathbb{R}$ where $n$ denotes the number of the data. Here $F(W(t),x)$ can be expressed as $F(W(t),x) := \sum_{r=1}^m a_r \exp(\langle w_r, x \rangle)$, where $m$ represents the number of neurons, and $w_r(t)$ are weights at time $t$. It's standard in literature that $a_r$ are the fixed weights and it's never changed during the training. We initialize the weights $W(0) \in \mathbb{R}^{d \times m}$ with random Gaussian distributions, such that $w_r(0) \sim \mathcal{N}(0, I_d)$ and initialize $a_r$ from random sign distribution for each $r \in [m]$. Using the gradient descent algorithm, we can find a weight $W(T)$ such that $\| F(W(T), X) - y \|_2 \leq \epsilon$ holds with probability $1-\delta$, where $\epsilon \in (0,0.1)$ and $m = \Omega(n^{2+o(1)}\log(n/\delta))$. To optimize the over-parameterization bound $m$, we employ several tight analysis techniques from previous studies [Song and Yang arXiv 2019, Munteanu, Omlor, Song and Woodruff ICML 2022].