 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Attention is Naturally Sparse with Gaussian Distributed Input
Apr 03, 2024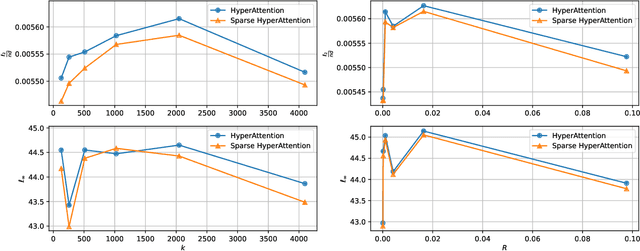
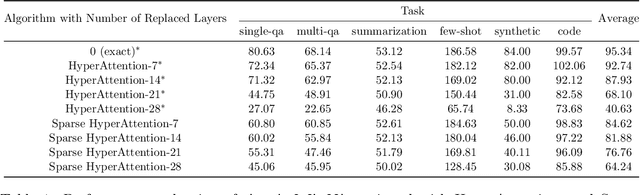
The computational intensity of Large Language Models (LLMs) is a critical bottleneck, primarily due to the $O(n^2)$ complexity of the attention mechanism in transformer architectures. Addressing this, sparse attention emerges as a key innovation, aiming to reduce computational load while maintaining model performance. This study presents a rigorous theoretical analysis of the sparsity in attention scores within LLMs, particularly under the framework of Gaussian inputs. By establishing a set of foundational assumptions and employing a methodical theoretical approach, we unravel the intrinsic characteristics of attention score sparsity and its implications on computational efficiency. Our main contribution lies in providing a detailed theoretical examination of how sparsity manifests in attention mechanisms, offering insights into the potential trade-offs between computational savings and model effectiveness. This work not only advances our understanding of sparse attention but also provides a scaffold for future research in optimizing the computational frameworks of LLMs, paving the way for more scalable and efficient AI systems.
Enhancing Stochastic Gradient Descent: A Unified Framework and Novel Acceleration Methods for Faster Convergence
Feb 02, 2024Based on SGD, previous works have proposed many algorithms that have improved convergence speed and generalization in stochastic optimization, such as SGDm, AdaGrad, Adam, etc. However, their convergence analysis under non-convex conditions is challenging. In this work, we propose a unified framework to address this issue. For any first-order methods, we interpret the updated direction $g_t$ as the sum of the stochastic subgradient $\nabla f_t(x_t)$ and an additional acceleration term $\frac{2|\langle v_t, \nabla f_t(x_t) \rangle|}{\|v_t\|_2^2} v_t$, thus we can discuss the convergence by analyzing $\langle v_t, \nabla f_t(x_t) \rangle$. Through our framework, we have discovered two plug-and-play acceleration methods: \textbf{Reject Accelerating} and \textbf{Random Vector Accelerating}, we theoretically demonstrate that these two methods can directly lead to an improvement in convergence rate.
Unmasking Transformers: A Theoretical Approach to Data Recovery via Attention Weights
Oct 19, 2023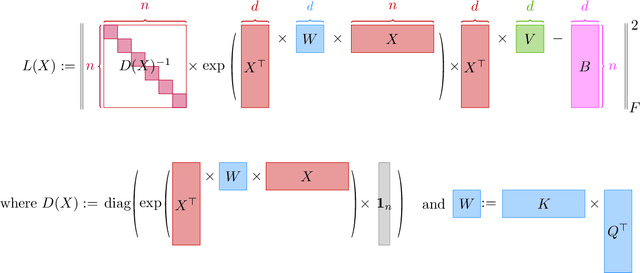

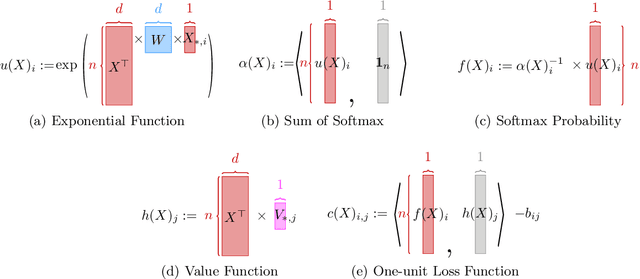

In the realm of deep learning, transformers have emerged as a dominant architecture, particularly in natural language processing tasks. However, with their widespread adoption, concerns regarding the security and privacy of the data processed by these models have arisen. In this paper, we address a pivotal question: Can the data fed into transformers be recovered using their attention weights and outputs? We introduce a theoretical framework to tackle this problem. Specifically, we present an algorithm that aims to recover the input data $X \in \mathbb{R}^{d \times n}$ from given attention weights $W = QK^\top \in \mathbb{R}^{d \times d}$ and output $B \in \mathbb{R}^{n \times n}$ by minimizing the loss function $L(X)$. This loss function captures the discrepancy between the expected output and the actual output of the transformer. Our findings have significant implications for the Localized Layer-wise Mechanism (LLM), suggesting potential vulnerabilities in the model's design from a security and privacy perspective. This work underscores the importance of understanding and safeguarding the internal workings of transformers to ensure the confidentiality of processed data.
Superiority of Softmax: Unveiling the Performance Edge Over Linear Attention
Oct 18, 2023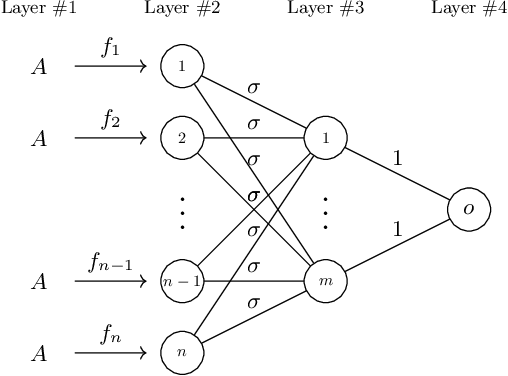
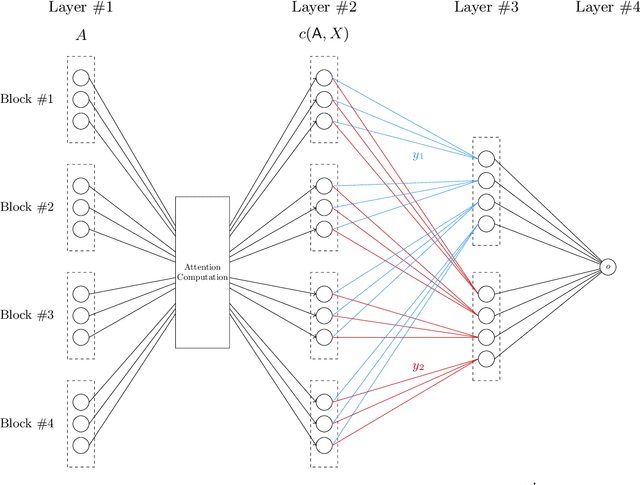
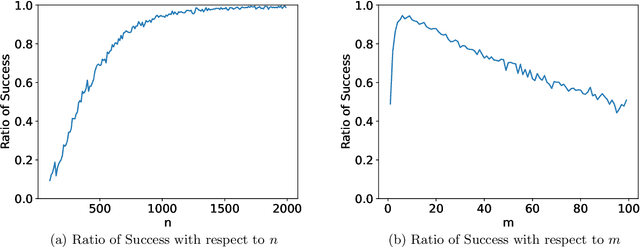
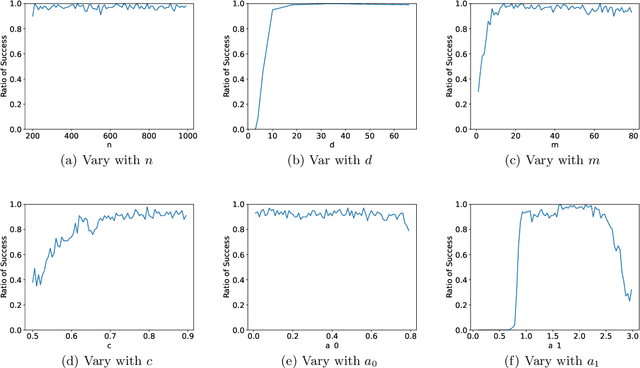
Large transformer models have achieved state-of-the-art results in numerous natural language processing tasks. Among the pivotal components of the transformer architecture, the attention mechanism plays a crucial role in capturing token interactions within sequences through the utilization of softmax function. Conversely, linear attention presents a more computationally efficient alternative by approximating the softmax operation with linear complexity. However, it exhibits substantial performance degradation when compared to the traditional softmax attention mechanism. In this paper, we bridge the gap in our theoretical understanding of the reasons behind the practical performance gap between softmax and linear attention. By conducting a comprehensive comparative analysis of these two attention mechanisms, we shed light on the underlying reasons for why softmax attention outperforms linear attention in most scenarios.
Clustered Linear Contextual Bandits with Knapsacks
Aug 21, 2023In this work, we study clustered contextual bandits where rewards and resource consumption are the outcomes of cluster-specific linear models. The arms are divided in clusters, with the cluster memberships being unknown to an algorithm. Pulling an arm in a time period results in a reward and in consumption for each one of multiple resources, and with the total consumption of any resource exceeding a constraint implying the termination of the algorithm. Thus, maximizing the total reward requires learning not only models about the reward and the resource consumption, but also cluster memberships. We provide an algorithm that achieves regret sublinear in the number of time periods, without requiring access to all of the arms. In particular, we show that it suffices to perform clustering only once to a randomly selected subset of the arms. To achieve this result, we provide a sophisticated combination of techniques from the literature of econometrics and of bandits with constraints.
Convergence of Two-Layer Regression with Nonlinear Units
Aug 16, 2023Large language models (LLMs), such as ChatGPT and GPT4, have shown outstanding performance in many human life task. Attention computation plays an important role in training LLMs. Softmax unit and ReLU unit are the key structure in attention computation. Inspired by them, we put forward a softmax ReLU regression problem. Generally speaking, our goal is to find an optimal solution to the regression problem involving the ReLU unit. In this work, we calculate a close form representation for the Hessian of the loss function. Under certain assumptions, we prove the Lipschitz continuous and the PSDness of the Hessian. Then, we introduce an greedy algorithm based on approximate Newton method, which converges in the sense of the distance to optimal solution. Last, We relax the Lipschitz condition and prove the convergence in the sense of loss value.
Zero-th Order Algorithm for Softmax Attention Optimization
Jul 17, 2023Large language models (LLMs) have brought about significant transformations in human society. Among the crucial computations in LLMs, the softmax unit holds great importance. Its helps the model generating a probability distribution on potential subsequent words or phrases, considering a series of input words. By utilizing this distribution, the model selects the most probable next word or phrase, based on the assigned probabilities. The softmax unit assumes a vital function in LLM training as it facilitates learning from data through the adjustment of neural network weights and biases. With the development of the size of LLMs, computing the gradient becomes expensive. However, Zero-th Order method can approximately compute the gradient with only forward passes. In this paper, we present a Zero-th Order algorithm specifically tailored for Softmax optimization. We demonstrate the convergence of our algorithm, highlighting its effectiveness in efficiently computing gradients for large-scale LLMs. By leveraging the Zeroth-Order method, our work contributes to the advancement of optimization techniques in the context of complex language models.
Faster Robust Tensor Power Method for Arbitrary Order
Jun 01, 2023Tensor decomposition is a fundamental method used in various areas to deal with high-dimensional data. \emph{Tensor power method} (TPM) is one of the widely-used techniques in the decomposition of tensors. This paper presents a novel tensor power method for decomposing arbitrary order tensors, which overcomes limitations of existing approaches that are often restricted to lower-order (less than $3$) tensors or require strong assumptions about the underlying data structure. We apply sketching method, and we are able to achieve the running time of $\widetilde{O}(n^{p-1})$, on the power $p$ and dimension $n$ tensor. We provide a detailed analysis for any $p$-th order tensor, which is never given in previous works.
Attention Scheme Inspired Softmax Regression
Apr 26, 2023Large language models (LLMs) have made transformed changes for human society. One of the key computation in LLMs is the softmax unit. This operation is important in LLMs because it allows the model to generate a distribution over possible next words or phrases, given a sequence of input words. This distribution is then used to select the most likely next word or phrase, based on the probabilities assigned by the model. The softmax unit plays a crucial role in training LLMs, as it allows the model to learn from the data by adjusting the weights and biases of the neural network. In the area of convex optimization such as using central path method to solve linear programming. The softmax function has been used a crucial tool for controlling the progress and stability of potential function [Cohen, Lee and Song STOC 2019, Brand SODA 2020]. In this work, inspired the softmax unit, we define a softmax regression problem. Formally speaking, given a matrix $A \in \mathbb{R}^{n \times d}$ and a vector $b \in \mathbb{R}^n$, the goal is to use greedy type algorithm to solve \begin{align*} \min_{x} \| \langle \exp(Ax), {\bf 1}_n \rangle^{-1} \exp(Ax) - b \|_2^2. \end{align*} In certain sense, our provable convergence result provides theoretical support for why we can use greedy algorithm to train softmax function in practice.