 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperiority of Softmax: Unveiling the Performance Edge Over Linear Attention
Paper and Code
Oct 18, 2023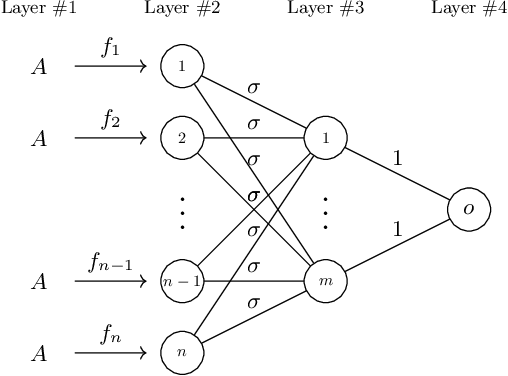
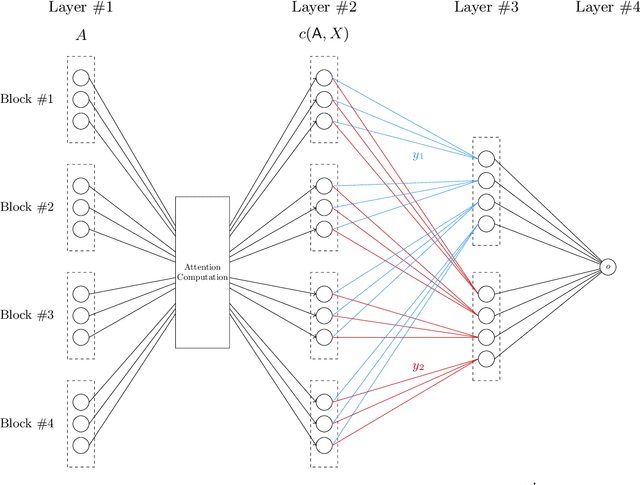
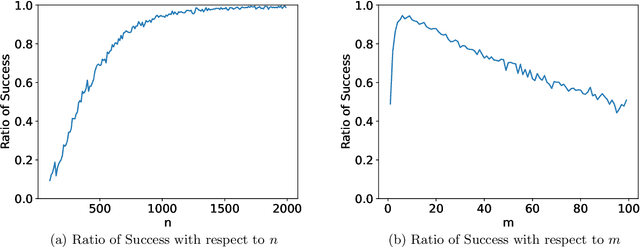
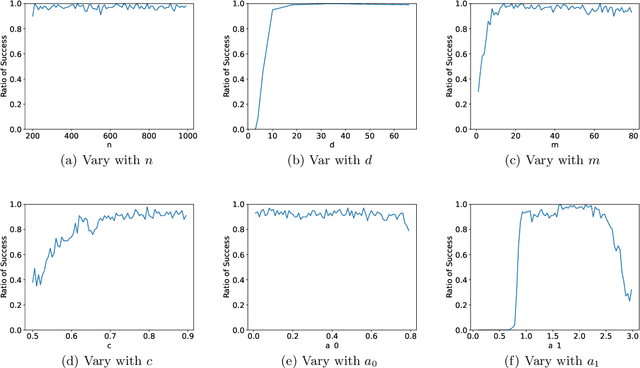
Large transformer models have achieved state-of-the-art results in numerous natural language processing tasks. Among the pivotal components of the transformer architecture, the attention mechanism plays a crucial role in capturing token interactions within sequences through the utilization of softmax function. Conversely, linear attention presents a more computationally efficient alternative by approximating the softmax operation with linear complexity. However, it exhibits substantial performance degradation when compared to the traditional softmax attention mechanism. In this paper, we bridge the gap in our theoretical understanding of the reasons behind the practical performance gap between softmax and linear attention. By conducting a comprehensive comparative analysis of these two attention mechanisms, we shed light on the underlying reasons for why softmax attention outperforms linear attention in most scenarios.