 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Dimensional Robust Mean Estimation with Untrusted Batches
Feb 24, 2026We study high-dimensional mean estimation in a collaborative setting where data is contributed by $N$ users in batches of size $n$. In this environment, a learner seeks to recover the mean $μ$ of a true distribution $P$ from a collection of sources that are both statistically heterogeneous and potentially malicious. We formalize this challenge through a double corruption landscape: an $\varepsilon$-fraction of users are entirely adversarial, while the remaining ``good'' users provide data from distributions that are related to $P$, but deviate by a proximity parameter $α$. Unlike existing work on the untrusted batch model, which typically measures this deviation via total variation distance in discrete settings, we address the continuous, high-dimensional regime under two natural variants for deviation: (1) good batches are drawn from distributions with a mean-shift of $\sqrtα$, or (2) an $α$-fraction of samples within each good batch are adversarially corrupted. In particular, the second model presents significant new challenges: in high dimensions, unlike discrete settings, even a small fraction of sample-level corruption can shift empirical means and covariances arbitrarily. We provide two Sum-of-Squares (SoS) based algorithms to navigate this tiered corruption. Our algorithms achieve the minimax-optimal error rate $O(\sqrt{\varepsilon/n} + \sqrt{d/nN} + \sqrtα)$, demonstrating that while heterogeneity $α$ represents an inherent statistical difficulty, the influence of adversarial users is suppressed by a factor of $1/\sqrt{n}$ due to the internal averaging afforded by the batch structure.
Support Basis: Fast Attention Beyond Bounded Entries
Oct 02, 2025



The quadratic complexity of softmax attention remains a central bottleneck in scaling large language models (LLMs). [Alman and Song, NeurIPS 2023] proposed a sub-quadratic attention approximation algorithm, but it works only under the restrictive bounded-entry assumption. Since this assumption rarely holds in practice, its applicability to modern LLMs is limited. In this paper, we introduce support-basis decomposition, a new framework for efficient attention approximation beyond bounded entries. We empirically demonstrate that the entries of the query and key matrices exhibit sub-Gaussian behavior. Our approach uses this property to split large and small entries, enabling exact computation on sparse components and polynomial approximation on dense components. We establish rigorous theoretical guarantees, proving a sub-quadratic runtime, and extend the method to a multi-threshold setting that eliminates all distributional assumptions. Furthermore, we provide the first theoretical justification for the empirical success of polynomial attention [Kacham, Mirrokni, and Zhong, ICML 2024], showing that softmax attention can be closely approximated by a combination of multiple polynomial attentions with sketching.
I3S: Importance Sampling Subspace Selection for Low-Rank Optimization in LLM Pretraining
Feb 09, 2025



Low-rank optimization has emerged as a promising approach to enabling memory-efficient training of large language models (LLMs). Existing low-rank optimization methods typically project gradients onto a low-rank subspace, reducing the memory cost of storing optimizer states. A key challenge in these methods is identifying suitable subspaces to ensure an effective optimization trajectory. Most existing approaches select the dominant subspace to preserve gradient information, as this intuitively provides the best approximation. However, we find that in practice, the dominant subspace stops changing during pretraining, thereby constraining weight updates to similar subspaces. In this paper, we propose importance sampling subspace selection (I3S) for low-rank optimization, which theoretically offers a comparable convergence rate to the dominant subspace approach. Empirically, we demonstrate that I3S significantly outperforms previous methods in LLM pretraining tasks.
Inverting the Leverage Score Gradient: An Efficient Approximate Newton Method
Aug 21, 2024Leverage scores have become essential in statistics and machine learning, aiding regression analysis, randomized matrix computations, and various other tasks. This paper delves into the inverse problem, aiming to recover the intrinsic model parameters given the leverage scores gradient. This endeavor not only enriches the theoretical understanding of models trained with leverage score techniques but also has substantial implications for data privacy and adversarial security. We specifically scrutinize the inversion of the leverage score gradient, denoted as $g(x)$. An innovative iterative algorithm is introduced for the approximate resolution of the regularized least squares problem stated as $\min_{x \in \mathbb{R}^d} 0.5 \|g(x) - c\|_2^2 + 0.5\|\mathrm{diag}(w)Ax\|_2^2$. Our algorithm employs subsampled leverage score distributions to compute an approximate Hessian in each iteration, under standard assumptions, considerably mitigating the time complexity. Given that a total of $T = \log(\| x_0 - x^* \|_2/ \epsilon)$ iterations are required, the cost per iteration is optimized to the order of $O( (\mathrm{nnz}(A) + d^{\omega} ) \cdot \mathrm{poly}(\log(n/\delta))$, where $\mathrm{nnz}(A)$ denotes the number of non-zero entries of $A$.
Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers
May 08, 2024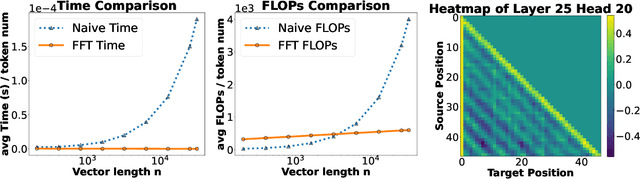
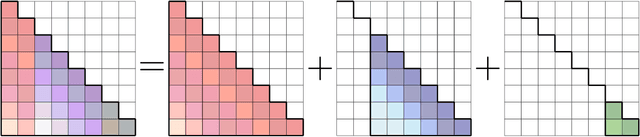
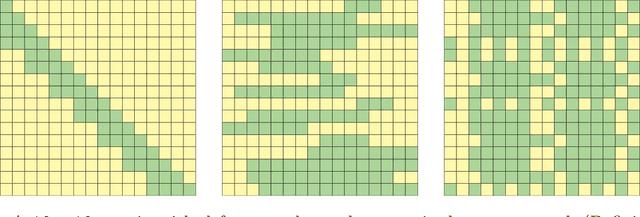
Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to the length $n$ input sequence is the notorious obstacle for further improvement and scalability in the longer context. In this work, we leverage the convolution-like structure of attention matrices to develop an efficient approximation method for attention computation using convolution matrices. We propose a $\mathsf{conv}$ basis system, "similar" to the rank basis, and show that any lower triangular (attention) matrix can always be decomposed as a sum of $k$ structured convolution matrices in this basis system. We then design an algorithm to quickly decompose the attention matrix into $k$ convolution matrices. Thanks to Fast Fourier Transforms (FFT), the attention {\it inference} can be computed in $O(knd \log n)$ time, where $d$ is the hidden dimension. In practice, we have $ d \ll n$, i.e., $d=3,072$ and $n=1,000,000$ for Gemma. Thus, when $kd = n^{o(1)}$, our algorithm achieve almost linear time, i.e., $n^{1+o(1)}$. Furthermore, the attention {\it training forward} and {\it backward gradient} can be computed in $n^{1+o(1)}$ as well. Our approach can avoid explicitly computing the $n \times n$ attention matrix, which may largely alleviate the quadratic computational complexity. Furthermore, our algorithm works on any input matrices. This work provides a new paradigm for accelerating attention computation in transformers to enable their application to longer contexts.
How to Inverting the Leverage Score Distribution?
Apr 21, 2024Leverage score is a fundamental problem in machine learning and theoretical computer science. It has extensive applications in regression analysis, randomized algorithms, and neural network inversion. Despite leverage scores are widely used as a tool, in this paper, we study a novel problem, namely the inverting leverage score problem. We analyze to invert the leverage score distributions back to recover model parameters. Specifically, given a leverage score $\sigma \in \mathbb{R}^n$, the matrix $A \in \mathbb{R}^{n \times d}$, and the vector $b \in \mathbb{R}^n$, we analyze the non-convex optimization problem of finding $x \in \mathbb{R}^d$ to minimize $\| \mathrm{diag}( \sigma ) - I_n \circ (A(x) (A(x)^\top A(x) )^{-1} A(x)^\top ) \|_F$, where $A(x):= S(x)^{-1} A \in \mathbb{R}^{n \times d} $, $S(x) := \mathrm{diag}(s(x)) \in \mathbb{R}^{n \times n}$ and $s(x) : = Ax - b \in \mathbb{R}^n$. Our theoretical studies include computing the gradient and Hessian, demonstrating that the Hessian matrix is positive definite and Lipschitz, and constructing first-order and second-order algorithms to solve this regression problem. Our work combines iterative shrinking and the induction hypothesis to ensure global convergence rates for the Newton method, as well as the properties of Lipschitz and strong convexity to guarantee the performance of gradient descent. This important study on inverting statistical leverage opens up numerous new applications in interpretation, data recovery, and security.
Local Convergence of Approximate Newton Method for Two Layer Nonlinear Regression
Nov 26, 2023There have been significant advancements made by large language models (LLMs) in various aspects of our daily lives. LLMs serve as a transformative force in natural language processing, finding applications in text generation, translation, sentiment analysis, and question-answering. The accomplishments of LLMs have led to a substantial increase in research efforts in this domain. One specific two-layer regression problem has been well-studied in prior works, where the first layer is activated by a ReLU unit, and the second layer is activated by a softmax unit. While previous works provide a solid analysis of building a two-layer regression, there is still a gap in the analysis of constructing regression problems with more than two layers. In this paper, we take a crucial step toward addressing this problem: we provide an analysis of a two-layer regression problem. In contrast to previous works, our first layer is activated by a softmax unit. This sets the stage for future analyses of creating more activation functions based on the softmax function. Rearranging the softmax function leads to significantly different analyses. Our main results involve analyzing the convergence properties of an approximate Newton method used to minimize the regularized training loss. We prove that the loss function for the Hessian matrix is positive definite and Lipschitz continuous under certain assumptions. This enables us to establish local convergence guarantees for the proposed training algorithm. Specifically, with an appropriate initialization and after $O(\log(1/\epsilon))$ iterations, our algorithm can find an $\epsilon$-approximate minimizer of the training loss with high probability. Each iteration requires approximately $O(\mathrm{nnz}(C) + d^\omega)$ time, where $d$ is the model size, $C$ is the input matrix, and $\omega < 2.374$ is the matrix multiplication exponent.
Revisiting Quantum Algorithms for Linear Regressions: Quadratic Speedups without Data-Dependent Parameters
Nov 24, 2023Linear regression is one of the most fundamental linear algebra problems. Given a dense matrix $A \in \mathbb{R}^{n \times d}$ and a vector $b$, the goal is to find $x'$ such that $ \| Ax' - b \|_2^2 \leq (1+\epsilon) \min_{x} \| A x - b \|_2^2 $. The best classical algorithm takes $O(nd) + \mathrm{poly}(d/\epsilon)$ time [Clarkson and Woodruff STOC 2013, Nelson and Nguyen FOCS 2013]. On the other hand, quantum linear regression algorithms can achieve exponential quantum speedups, as shown in [Wang Phys. Rev. A 96, 012335, Kerenidis and Prakash ITCS 2017, Chakraborty, Gily{\'e}n and Jeffery ICALP 2019]. However, the running times of these algorithms depend on some quantum linear algebra-related parameters, such as $\kappa(A)$, the condition number of $A$. In this work, we develop a quantum algorithm that runs in $\widetilde{O}(\epsilon^{-1}\sqrt{n}d^{1.5}) + \mathrm{poly}(d/\epsilon)$ time. It provides a quadratic quantum speedup in $n$ over the classical lower bound without any dependence on data-dependent parameters. In addition, we also show our result can be generalized to multiple regression and ridge linear regression.
The Expressibility of Polynomial based Attention Scheme
Oct 30, 2023Large language models (LLMs) have significantly improved various aspects of our daily lives. These models have impacted numerous domains, from healthcare to education, enhancing productivity, decision-making processes, and accessibility. As a result, they have influenced and, to some extent, reshaped people's lifestyles. However, the quadratic complexity of attention in transformer architectures poses a challenge when scaling up these models for processing long textual contexts. This issue makes it impractical to train very large models on lengthy texts or use them efficiently during inference. While a recent study by [KMZ23] introduced a technique that replaces the softmax with a polynomial function and polynomial sketching to speed up attention mechanisms, the theoretical understandings of this new approach are not yet well understood. In this paper, we offer a theoretical analysis of the expressive capabilities of polynomial attention. Our study reveals a disparity in the ability of high-degree and low-degree polynomial attention. Specifically, we construct two carefully designed datasets, namely $\mathcal{D}_0$ and $\mathcal{D}_1$, where $\mathcal{D}_1$ includes a feature with a significantly larger value compared to $\mathcal{D}_0$. We demonstrate that with a sufficiently high degree $\beta$, a single-layer polynomial attention network can distinguish between $\mathcal{D}_0$ and $\mathcal{D}_1$. However, with a low degree $\beta$, the network cannot effectively separate the two datasets. This analysis underscores the greater effectiveness of high-degree polynomials in amplifying large values and distinguishing between datasets. Our analysis offers insight into the representational capacity of polynomial attention and provides a rationale for incorporating higher-degree polynomials in attention mechanisms to capture intricate linguistic correlations.
A Unified Scheme of ResNet and Softmax
Sep 23, 2023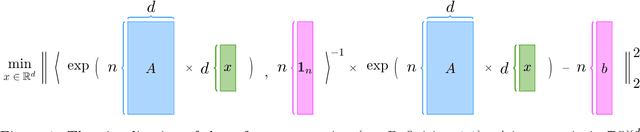
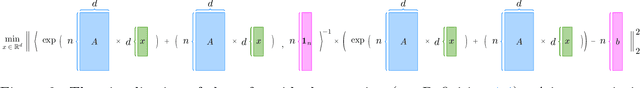
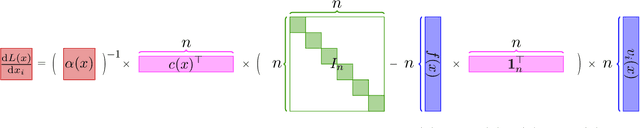

Large language models (LLMs) have brought significant changes to human society. Softmax regression and residual neural networks (ResNet) are two important techniques in deep learning: they not only serve as significant theoretical components supporting the functionality of LLMs but also are related to many other machine learning and theoretical computer science fields, including but not limited to image classification, object detection, semantic segmentation, and tensors. Previous research works studied these two concepts separately. In this paper, we provide a theoretical analysis of the regression problem: $\| \langle \exp(Ax) + A x , {\bf 1}_n \rangle^{-1} ( \exp(Ax) + Ax ) - b \|_2^2$, where $A$ is a matrix in $\mathbb{R}^{n \times d}$, $b$ is a vector in $\mathbb{R}^n$, and ${\bf 1}_n$ is the $n$-dimensional vector whose entries are all $1$. This regression problem is a unified scheme that combines softmax regression and ResNet, which has never been done before. We derive the gradient, Hessian, and Lipschitz properties of the loss function. The Hessian is shown to be positive semidefinite, and its structure is characterized as the sum of a low-rank matrix and a diagonal matrix. This enables an efficient approximate Newton method. As a result, this unified scheme helps to connect two previously thought unrelated fields and provides novel insight into loss landscape and optimization for emerging over-parameterized neural networks, which is meaningful for future research in deep learning models.