 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Scheme of ResNet and Softmax
Paper and Code
Sep 23, 2023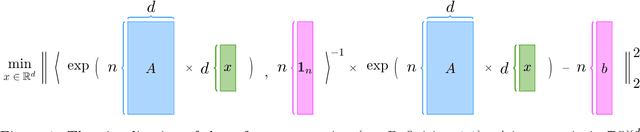
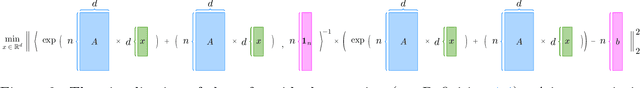
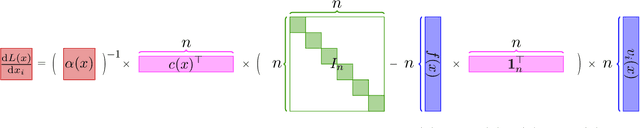

Large language models (LLMs) have brought significant changes to human society. Softmax regression and residual neural networks (ResNet) are two important techniques in deep learning: they not only serve as significant theoretical components supporting the functionality of LLMs but also are related to many other machine learning and theoretical computer science fields, including but not limited to image classification, object detection, semantic segmentation, and tensors. Previous research works studied these two concepts separately. In this paper, we provide a theoretical analysis of the regression problem: $\| \langle \exp(Ax) + A x , {\bf 1}_n \rangle^{-1} ( \exp(Ax) + Ax ) - b \|_2^2$, where $A$ is a matrix in $\mathbb{R}^{n \times d}$, $b$ is a vector in $\mathbb{R}^n$, and ${\bf 1}_n$ is the $n$-dimensional vector whose entries are all $1$. This regression problem is a unified scheme that combines softmax regression and ResNet, which has never been done before. We derive the gradient, Hessian, and Lipschitz properties of the loss function. The Hessian is shown to be positive semidefinite, and its structure is characterized as the sum of a low-rank matrix and a diagonal matrix. This enables an efficient approximate Newton method. As a result, this unified scheme helps to connect two previously thought unrelated fields and provides novel insight into loss landscape and optimization for emerging over-parameterized neural networks, which is meaningful for future research in deep learning models.