 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
Rethinking Langevin Thompson Sampling from A Stochastic Approximation Perspective
Oct 06, 2025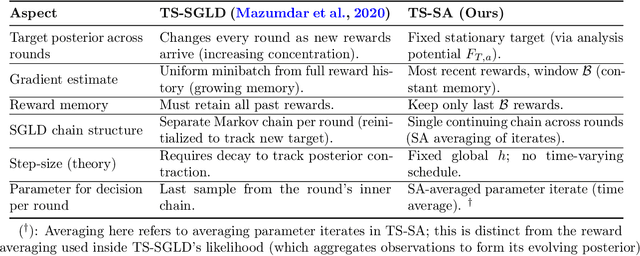


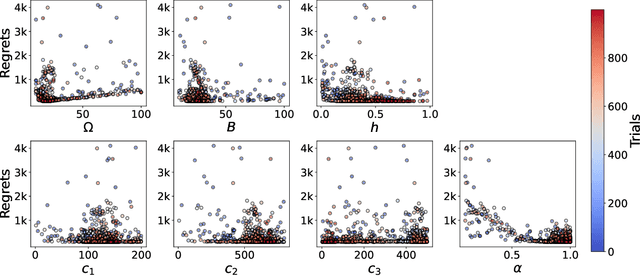
Most existing approximate Thompson Sampling (TS) algorithms for multi-armed bandits use Stochastic Gradient Langevin Dynamics (SGLD) or its variants in each round to sample from the posterior, relaxing the need for conjugacy assumptions between priors and reward distributions in vanilla TS. However, they often require approximating a different posterior distribution in different round of the bandit problem. This requires tricky, round-specific tuning of hyperparameters such as dynamic learning rates, causing challenges in both theoretical analysis and practical implementation. To alleviate this non-stationarity, we introduce TS-SA, which incorporates stochastic approximation (SA) within the TS framework. In each round, TS-SA constructs a posterior approximation only using the most recent reward(s), performs a Langevin Monte Carlo (LMC) update, and applies an SA step to average noisy proposals over time. This can be interpreted as approximating a stationary posterior target throughout the entire algorithm, which further yields a fixed step-size, a unified convergence analysis framework, and improved posterior estimates through temporal averaging. We establish near-optimal regret bounds for TS-SA, with a simplified and more intuitive theoretical analysis enabled by interpreting the entire algorithm as a simulation of a stationary SGLD process. Our empirical results demonstrate that even a single-step Langevin update with certain warm-up outperforms existing methods substantially on bandit tasks.
From Source to Target: Leveraging Transfer Learning for Predictive Process Monitoring in Organizations
Aug 11, 2025Event logs reflect the behavior of business processes that are mapped in organizational information systems. Predictive process monitoring (PPM) transforms these data into value by creating process-related predictions that provide the insights required for proactive interventions at process runtime. Existing PPM techniques require sufficient amounts of event data or other relevant resources that might not be readily available, preventing some organizations from utilizing PPM. The transfer learning-based PPM technique presented in this paper allows organizations without suitable event data or other relevant resources to implement PPM for effective decision support. The technique is instantiated in two real-life use cases, based on which numerical experiments are performed using event logs for IT service management processes in an intra- and inter-organizational setting. The results of the experiments suggest that knowledge of one business process can be transferred to a similar business process in the same or a different organization to enable effective PPM in the target context. With the proposed technique, organizations can benefit from transfer learning in an intra- and inter-organizational setting, where resources like pre-trained models are transferred within and across organizational boundaries.
Upper and Lower Bounds for Distributionally Robust Off-Dynamics Reinforcement Learning
Sep 30, 2024



We study off-dynamics Reinforcement Learning (RL), where the policy training and deployment environments are different. To deal with this environmental perturbation, we focus on learning policies robust to uncertainties in transition dynamics under the framework of distributionally robust Markov decision processes (DRMDPs), where the nominal and perturbed dynamics are linear Markov Decision Processes. We propose a novel algorithm We-DRIVE-U that enjoys an average suboptimality $\widetilde{\mathcal{O}}\big({d H \cdot \min \{1/{\rho}, H\}/\sqrt{K} }\big)$, where $K$ is the number of episodes, $H$ is the horizon length, $d$ is the feature dimension and $\rho$ is the uncertainty level. This result improves the state-of-the-art by $\mathcal{O}(dH/\min\{1/\rho,H\})$. We also construct a novel hard instance and derive the first information-theoretic lower bound in this setting, which indicates our algorithm is near-optimal up to $\mathcal{O}(\sqrt{H})$ for any uncertainty level $\rho\in(0,1]$. Our algorithm also enjoys a 'rare-switching' design, and thus only requires $\mathcal{O}(dH\log(1+H^2K))$ policy switches and $\mathcal{O}(d^2H\log(1+H^2K))$ calls for oracle to solve dual optimization problems, which significantly improves the computational efficiency of existing algorithms for DRMDPs, whose policy switch and oracle complexities are both $\mathcal{O}(K)$.
How to Inverting the Leverage Score Distribution?
Apr 21, 2024Leverage score is a fundamental problem in machine learning and theoretical computer science. It has extensive applications in regression analysis, randomized algorithms, and neural network inversion. Despite leverage scores are widely used as a tool, in this paper, we study a novel problem, namely the inverting leverage score problem. We analyze to invert the leverage score distributions back to recover model parameters. Specifically, given a leverage score $\sigma \in \mathbb{R}^n$, the matrix $A \in \mathbb{R}^{n \times d}$, and the vector $b \in \mathbb{R}^n$, we analyze the non-convex optimization problem of finding $x \in \mathbb{R}^d$ to minimize $\| \mathrm{diag}( \sigma ) - I_n \circ (A(x) (A(x)^\top A(x) )^{-1} A(x)^\top ) \|_F$, where $A(x):= S(x)^{-1} A \in \mathbb{R}^{n \times d} $, $S(x) := \mathrm{diag}(s(x)) \in \mathbb{R}^{n \times n}$ and $s(x) : = Ax - b \in \mathbb{R}^n$. Our theoretical studies include computing the gradient and Hessian, demonstrating that the Hessian matrix is positive definite and Lipschitz, and constructing first-order and second-order algorithms to solve this regression problem. Our work combines iterative shrinking and the induction hypothesis to ensure global convergence rates for the Newton method, as well as the properties of Lipschitz and strong convexity to guarantee the performance of gradient descent. This important study on inverting statistical leverage opens up numerous new applications in interpretation, data recovery, and security.
Randomized Exploration in Cooperative Multi-Agent Reinforcement Learning
Apr 16, 2024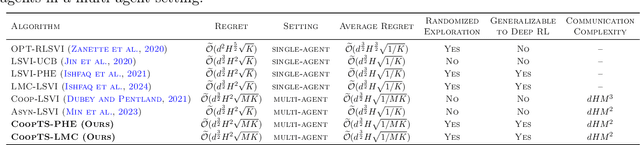
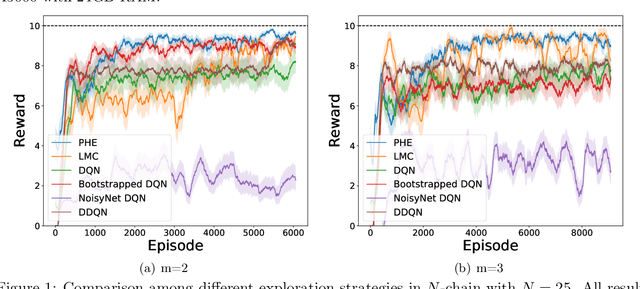
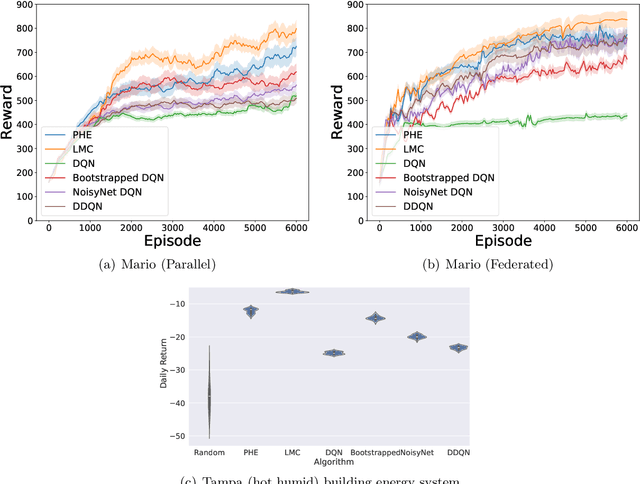
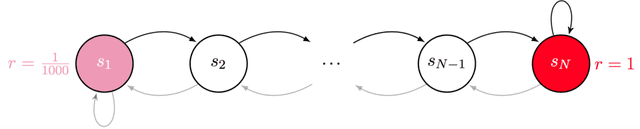
We present the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning (MARL). We propose a unified algorithm framework for randomized exploration in parallel Markov Decision Processes (MDPs), and two Thompson Sampling (TS)-type algorithms, CoopTS-PHE and CoopTS-LMC, incorporating the perturbed-history exploration (PHE) strategy and the Langevin Monte Carlo exploration (LMC) strategy respectively, which are flexible in design and easy to implement in practice. For a special class of parallel MDPs where the transition is (approximately) linear, we theoretically prove that both CoopTS-PHE and CoopTS-LMC achieve a $\widetilde{\mathcal{O}}(d^{3/2}H^2\sqrt{MK})$ regret bound with communication complexity $\widetilde{\mathcal{O}}(dHM^2)$, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the number of agents, and $K$ is the number of episodes. This is the first theoretical result for randomized exploration in cooperative MARL. We evaluate our proposed method on multiple parallel RL environments, including a deep exploration problem (\textit{i.e.,} $N$-chain), a video game, and a real-world problem in energy systems. Our experimental results support that our framework can achieve better performance, even under conditions of misspecified transition models. Additionally, we establish a connection between our unified framework and the practical application of federated learning.
A Theoretical Insight into Attack and Defense of Gradient Leakage in Transformer
Nov 22, 2023The Deep Leakage from Gradient (DLG) attack has emerged as a prevalent and highly effective method for extracting sensitive training data by inspecting exchanged gradients. This approach poses a substantial threat to the privacy of individuals and organizations alike. This research presents a comprehensive analysis of the gradient leakage method when applied specifically to transformer-based models. Through meticulous examination, we showcase the capability to accurately recover data solely from gradients and rigorously investigate the conditions under which gradient attacks can be executed, providing compelling evidence. Furthermore, we reevaluate the approach of introducing additional noise on gradients as a protective measure against gradient attacks. To address this, we outline a theoretical proof that analyzes the associated privacy costs within the framework of differential privacy. Additionally, we affirm the convergence of the Stochastic Gradient Descent (SGD) algorithm under perturbed gradients. The primary objective of this study is to augment the understanding of gradient leakage attack and defense strategies while actively contributing to the development of privacy-preserving techniques specifically tailored for transformer-based models. By shedding light on the vulnerabilities and countermeasures associated with gradient leakage, this research aims to foster advancements in safeguarding sensitive data and upholding privacy in the context of transformer-based models.
A Unified Scheme of ResNet and Softmax
Sep 23, 2023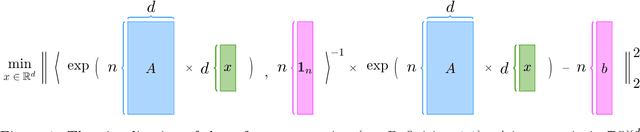
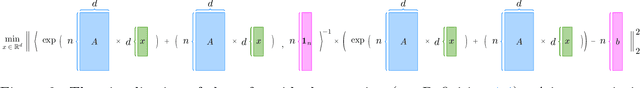
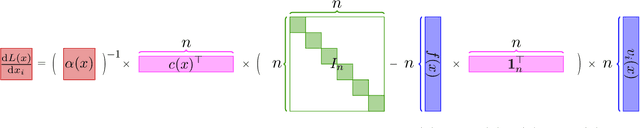

Large language models (LLMs) have brought significant changes to human society. Softmax regression and residual neural networks (ResNet) are two important techniques in deep learning: they not only serve as significant theoretical components supporting the functionality of LLMs but also are related to many other machine learning and theoretical computer science fields, including but not limited to image classification, object detection, semantic segmentation, and tensors. Previous research works studied these two concepts separately. In this paper, we provide a theoretical analysis of the regression problem: $\| \langle \exp(Ax) + A x , {\bf 1}_n \rangle^{-1} ( \exp(Ax) + Ax ) - b \|_2^2$, where $A$ is a matrix in $\mathbb{R}^{n \times d}$, $b$ is a vector in $\mathbb{R}^n$, and ${\bf 1}_n$ is the $n$-dimensional vector whose entries are all $1$. This regression problem is a unified scheme that combines softmax regression and ResNet, which has never been done before. We derive the gradient, Hessian, and Lipschitz properties of the loss function. The Hessian is shown to be positive semidefinite, and its structure is characterized as the sum of a low-rank matrix and a diagonal matrix. This enables an efficient approximate Newton method. As a result, this unified scheme helps to connect two previously thought unrelated fields and provides novel insight into loss landscape and optimization for emerging over-parameterized neural networks, which is meaningful for future research in deep learning models.
A Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
Sep 14, 2023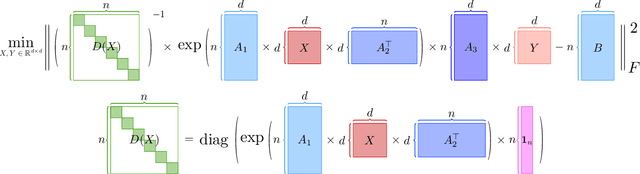

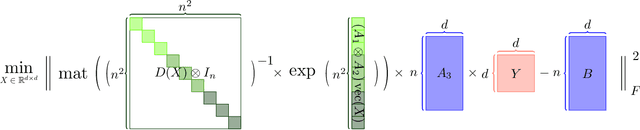
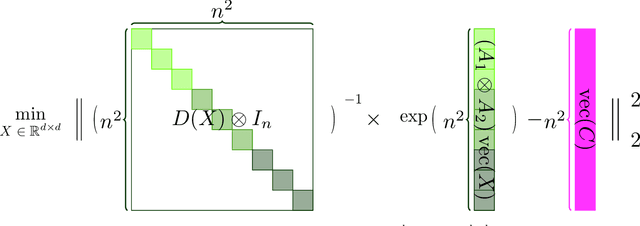
Large language models (LLMs) have played a pivotal role in revolutionizing various facets of our daily existence. Solving attention regression is a fundamental task in optimizing LLMs. In this work, we focus on giving a provable guarantee for the one-layer attention network objective function $L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp( \mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3} Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2 \times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and $A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of $\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$ is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the vectorization of $X$. In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n \times d}$ can be viewed as the input of a layer. The matrix version of $x$ can be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in $\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of matrix multiplication.
Fast and Efficient Matching Algorithm with Deadline Instances
May 15, 2023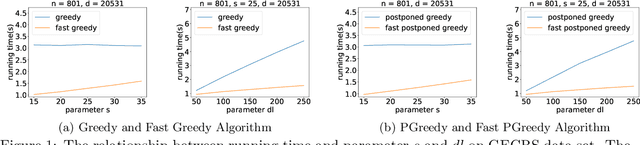

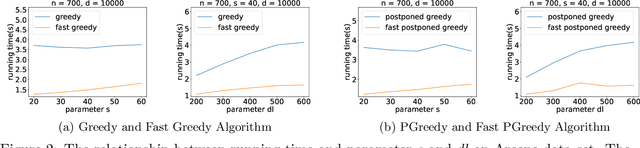

Online weighted matching problem is a fundamental problem in machine learning due to its numerous applications. Despite many efforts in this area, existing algorithms are either too slow or don't take $\mathrm{deadline}$ (the longest time a node can be matched) into account. In this paper, we introduce a market model with $\mathrm{deadline}$ first. Next, we present our two optimized algorithms (\textsc{FastGreedy} and \textsc{FastPostponedGreedy}) and offer theoretical proof of the time complexity and correctness of our algorithms. In \textsc{FastGreedy} algorithm, we have already known if a node is a buyer or a seller. But in \textsc{FastPostponedGreedy} algorithm, the status of each node is unknown at first. Then, we generalize a sketching matrix to run the original and our algorithms on both real data sets and synthetic data sets. Let $\epsilon \in (0,0.1)$ denote the relative error of the real weight of each edge. The competitive ratio of original \textsc{Greedy} and \textsc{PostponedGreedy} is $\frac{1}{2}$ and $\frac{1}{4}$ respectively. Based on these two original algorithms, we proposed \textsc{FastGreedy} and \textsc{FastPostponedGreedy} algorithms and the competitive ratio of them is $\frac{1 - \epsilon}{2}$ and $\frac{1 - \epsilon}{4}$ respectively. At the same time, our algorithms run faster than the original two algorithms. Given $n$ nodes in $\mathbb{R} ^ d$, we decrease the time complexity from $O(nd)$ to $\widetilde{O}(\epsilon^{-2} \cdot (n + d))$.