 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Datasets for Multi-Sensor, Multi-Agent, and Multi-Domain Learning in Autonomous Systems
Jun 03, 2026Existing datasets cannot support large-scale learning in multi-agent, multi-sensor, or multi-domain autonomy, where diversity and coordination are essential. We present a modular dataset generation pipeline that creates terabyte-scale, ground-truth-labeled data for ground, aerial, and infrastructure-based systems using the AVstack framework and CARLA simulator. Supporting single- and multi-agent configurations with flexible sensor suites, the pipeline enables controllable experimentation across challenging conditions. Representative perception and fusion studies show how generated data can support application-specific training and collaborative autonomy.
Adaptive Policy Selection and Fine-Tuning under Interaction Budgets for Offline-to-Online Reinforcement Learning
May 06, 2026In offline-to-online reinforcement learning (O2O-RL), policies are first safely trained offline using previously collected datasets and then further fine-tuned for tasks via limited online interactions. In a typical O2O-RL pipeline, candidate policies trained with offline RL are evaluated via either off-policy evaluation (OPE) or online evaluation (OE). The policy with the highest estimated value is then deployed and continually fine-tuned. However, this setup has two main issues. First, OPE can be unreliable, making it risky to deploy a policy based solely on those estimates, whereas OE may identify a viable policy with substantial online interaction, which could have been used for fine-tuning. Second--and more importantly--it is also often not possible to determine a priori whether a pretrained policy will improve with post-deployment fine-tuning, especially in non-stationary environments. As a result, procedures committing to a single deployed policy are impractical in many real-world settings. Moreover, a naive remedy that exhaustively fine-tunes all candidates would violate interaction budget constraints and is likewise infeasible. In this paper, we propose a novel adaptive approach for policy selection and fine-tuning under online interaction budgets in O2O-RL. Following the standard pipeline, we first train a set of candidate policies with different offline RL algorithms and hyperparameters; we then perform OPE to obtain initial performance estimates. We next adaptively select and fine-tune the policies based on their predicted performance via an upper-confidence-bound approach thereby making efficient use of online interactions. We demonstrate that our approach improves upon O2O-RL baselines with various benchmarks.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025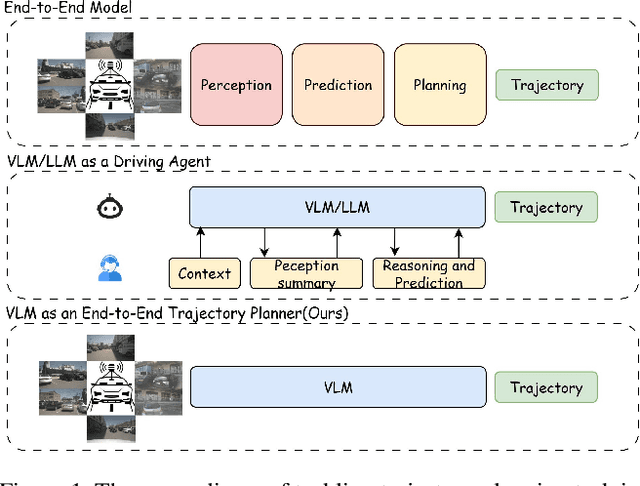
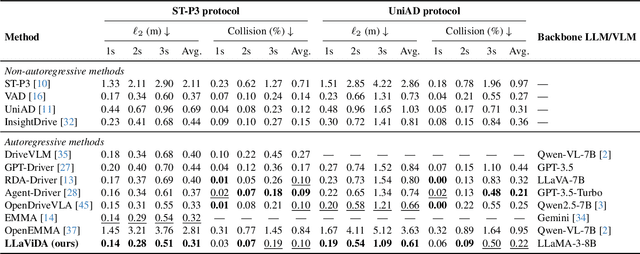
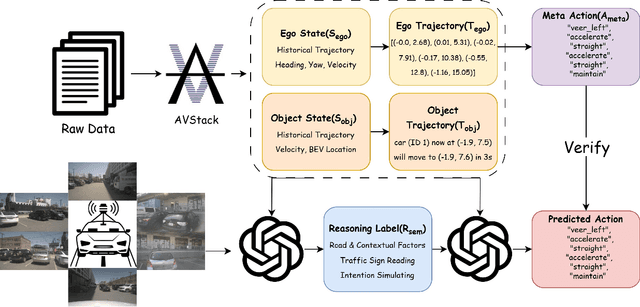
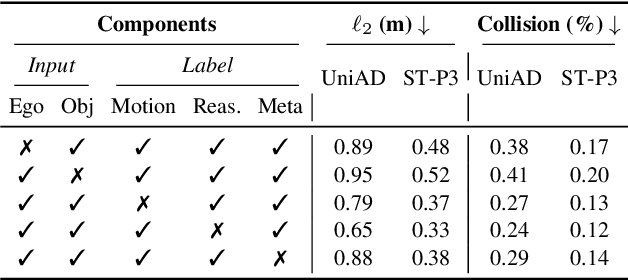
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
RaGNNarok: A Light-Weight Graph Neural Network for Enhancing Radar Point Clouds on Unmanned Ground Vehicles
Jul 01, 2025Low-cost indoor mobile robots have gained popularity with the increasing adoption of automation in homes and commercial spaces. However, existing lidar and camera-based solutions have limitations such as poor performance in visually obscured environments, high computational overhead for data processing, and high costs for lidars. In contrast, mmWave radar sensors offer a cost-effective and lightweight alternative, providing accurate ranging regardless of visibility. However, existing radar-based localization suffers from sparse point cloud generation, noise, and false detections. Thus, in this work, we introduce RaGNNarok, a real-time, lightweight, and generalizable graph neural network (GNN)-based framework to enhance radar point clouds, even in complex and dynamic environments. With an inference time of just 7.3 ms on the low-cost Raspberry Pi 5, RaGNNarok runs efficiently even on such resource-constrained devices, requiring no additional computational resources. We evaluate its performance across key tasks, including localization, SLAM, and autonomous navigation, in three different environments. Our results demonstrate strong reliability and generalizability, making RaGNNarok a robust solution for low-cost indoor mobile robots.
Assured Autonomy with Neuro-Symbolic Perception
May 27, 2025Many state-of-the-art AI models deployed in cyber-physical systems (CPS), while highly accurate, are simply pattern-matchers.~With limited security guarantees, there are concerns for their reliability in safety-critical and contested domains. To advance assured AI, we advocate for a paradigm shift that imbues data-driven perception models with symbolic structure, inspired by a human's ability to reason over low-level features and high-level context. We propose a neuro-symbolic paradigm for perception (NeuSPaPer) and illustrate how joint object detection and scene graph generation (SGG) yields deep scene understanding.~Powered by foundation models for offline knowledge extraction and specialized SGG algorithms for real-time deployment, we design a framework leveraging structured relational graphs that ensures the integrity of situational awareness in autonomy. Using physics-based simulators and real-world datasets, we demonstrate how SGG bridges the gap between low-level sensor perception and high-level reasoning, establishing a foundation for resilient, context-aware AI and advancing trusted autonomy in CPS.
MARS: Defending Unmanned Aerial Vehicles From Attacks on Inertial Sensors with Model-based Anomaly Detection and Recovery
May 02, 2025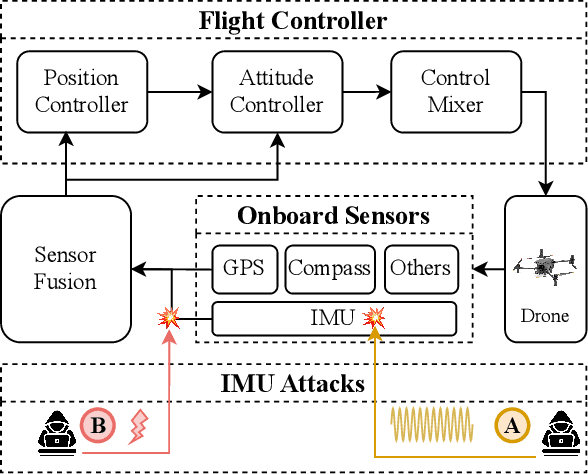
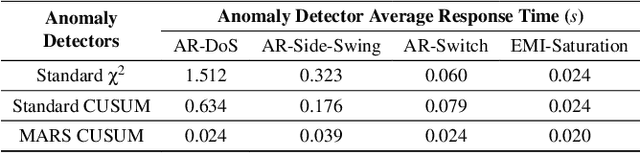
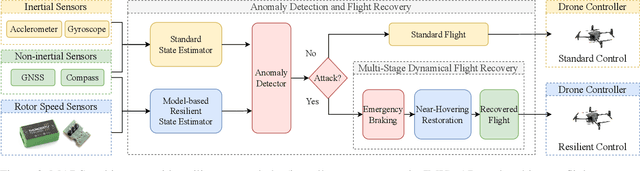

Unmanned Aerial Vehicles (UAVs) rely on measurements from Inertial Measurement Units (IMUs) to maintain stable flight. However, IMUs are susceptible to physical attacks, including acoustic resonant and electromagnetic interference attacks, resulting in immediate UAV crashes. Consequently, we introduce a Model-based Anomaly detection and Recovery System (MARS) that enables UAVs to quickly detect adversarial attacks on inertial sensors and achieve dynamic flight recovery. MARS features an attack-resilient state estimator based on the Extended Kalman Filter, which incorporates position, velocity, heading, and rotor speed measurements to reconstruct accurate attitude and angular velocity information for UAV control. Moreover, a statistical anomaly detection system monitors IMU sensor data, raising a system-level alert if an attack is detected. Upon receiving the alert, a multi-stage dynamic flight recovery strategy suspends the ongoing mission, stabilizes the drone in a hovering condition, and then resumes tasks under the resilient control. Experimental results in PX4 software-in-the-loop environments as well as real-world MARS-PX4 autopilot-equipped drones demonstrate the superiority of our approach over existing IMU-defense frameworks, showcasing the ability of the UAVs to survive attacks and complete the missions.
Probabilistic Segmentation for Robust Field of View Estimation
Mar 10, 2025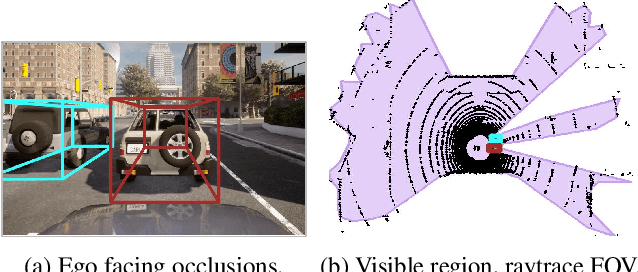
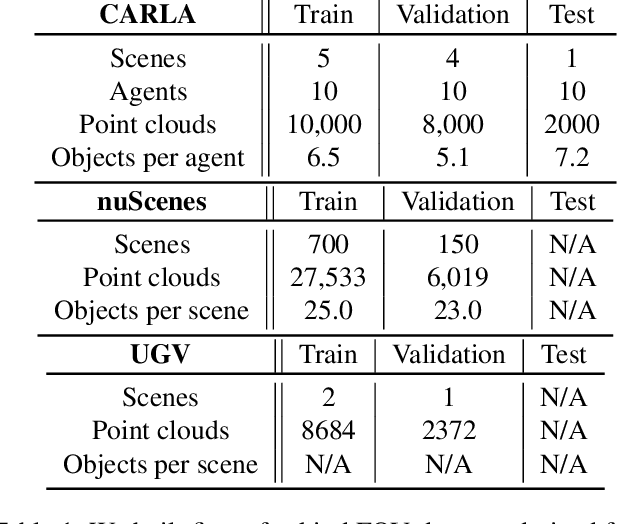
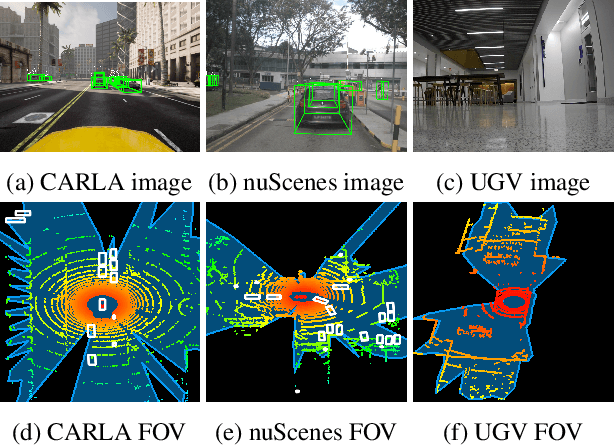
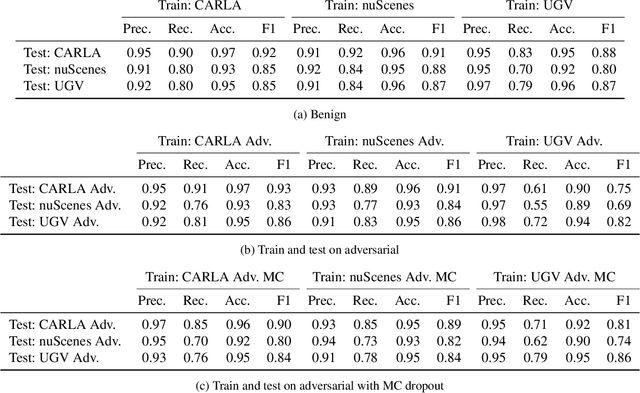
Attacks on sensing and perception threaten the safe deployment of autonomous vehicles (AVs). Security-aware sensor fusion helps mitigate threats but requires accurate field of view (FOV) estimation which has not been evaluated autonomy. To address this gap, we adapt classical computer graphics algorithms to develop the first autonomy-relevant FOV estimators and create the first datasets with ground truth FOV labels. Unfortunately, we find that these approaches are themselves highly vulnerable to attacks on sensing. To improve robustness of FOV estimation against attacks, we propose a learning-based segmentation model that captures FOV features, integrates Monte Carlo dropout (MCD) for uncertainty quantification, and performs anomaly detection on confidence maps. We illustrate through comprehensive evaluations attack resistance and strong generalization across environments. Architecture trade studies demonstrate the model is feasible for real-time deployment in multiple applications.
NeuroStrata: Harnessing Neurosymbolic Paradigms for Improved Design, Testability, and Verifiability of Autonomous CPS
Feb 17, 2025


Autonomous cyber-physical systems (CPSs) leverage AI for perception, planning, and control but face trust and safety certification challenges due to inherent uncertainties. The neurosymbolic paradigm replaces stochastic layers with interpretable symbolic AI, enabling determinism. While promising, challenges like multisensor fusion, adaptability, and verification remain. This paper introduces NeuroStrata, a neurosymbolic framework to enhance the testing and verification of autonomous CPS. We outline its key components, present early results, and detail future plans.
Off-Policy Selection for Initiating Human-Centric Experimental Design
Oct 26, 2024



In human-centric tasks such as healthcare and education, the heterogeneity among patients and students necessitates personalized treatments and instructional interventions. While reinforcement learning (RL) has been utilized in those tasks, off-policy selection (OPS) is pivotal to close the loop by offline evaluating and selecting policies without online interactions, yet current OPS methods often overlook the heterogeneity among participants. Our work is centered on resolving a pivotal challenge in human-centric systems (HCSs): how to select a policy to deploy when a new participant joining the cohort, without having access to any prior offline data collected over the participant? We introduce First-Glance Off-Policy Selection (FPS), a novel approach that systematically addresses participant heterogeneity through sub-group segmentation and tailored OPS criteria to each sub-group. By grouping individuals with similar traits, FPS facilitates personalized policy selection aligned with unique characteristics of each participant or group of participants. FPS is evaluated via two important but challenging applications, intelligent tutoring systems and a healthcare application for sepsis treatment and intervention. FPS presents significant advancement in enhancing learning outcomes of students and in-hospital care outcomes.
Randomized Exploration in Cooperative Multi-Agent Reinforcement Learning
Apr 16, 2024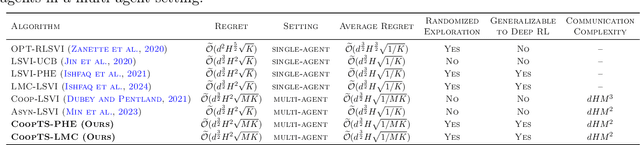
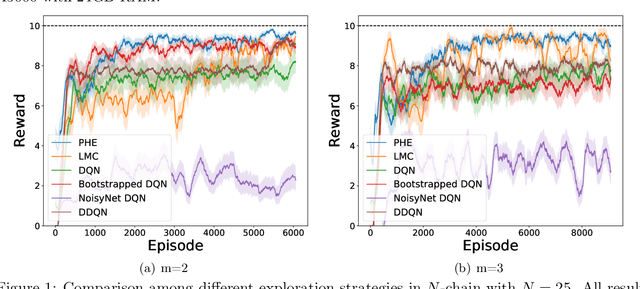
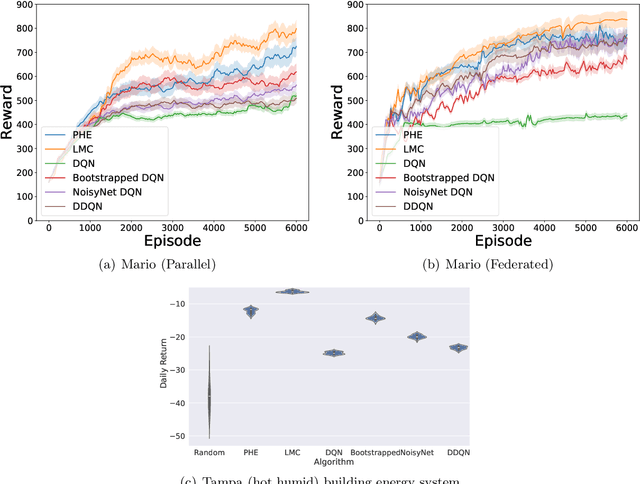
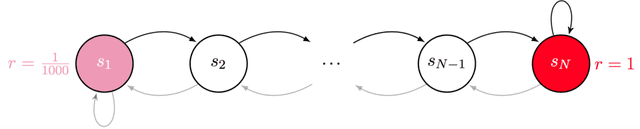
We present the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning (MARL). We propose a unified algorithm framework for randomized exploration in parallel Markov Decision Processes (MDPs), and two Thompson Sampling (TS)-type algorithms, CoopTS-PHE and CoopTS-LMC, incorporating the perturbed-history exploration (PHE) strategy and the Langevin Monte Carlo exploration (LMC) strategy respectively, which are flexible in design and easy to implement in practice. For a special class of parallel MDPs where the transition is (approximately) linear, we theoretically prove that both CoopTS-PHE and CoopTS-LMC achieve a $\widetilde{\mathcal{O}}(d^{3/2}H^2\sqrt{MK})$ regret bound with communication complexity $\widetilde{\mathcal{O}}(dHM^2)$, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the number of agents, and $K$ is the number of episodes. This is the first theoretical result for randomized exploration in cooperative MARL. We evaluate our proposed method on multiple parallel RL environments, including a deep exploration problem (\textit{i.e.,} $N$-chain), a video game, and a real-world problem in energy systems. Our experimental results support that our framework can achieve better performance, even under conditions of misspecified transition models. Additionally, we establish a connection between our unified framework and the practical application of federated learning.