 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Exploration in Cooperative Multi-Agent Reinforcement Learning
Apr 16, 2024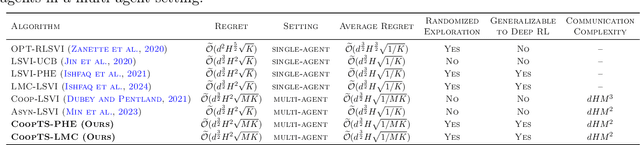
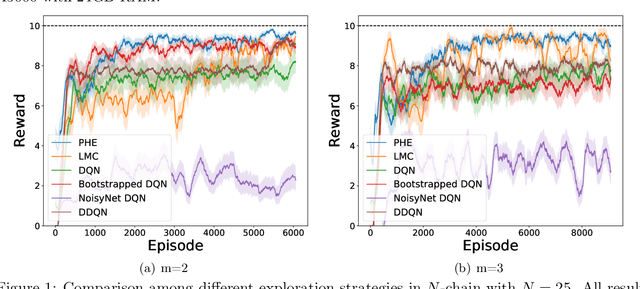
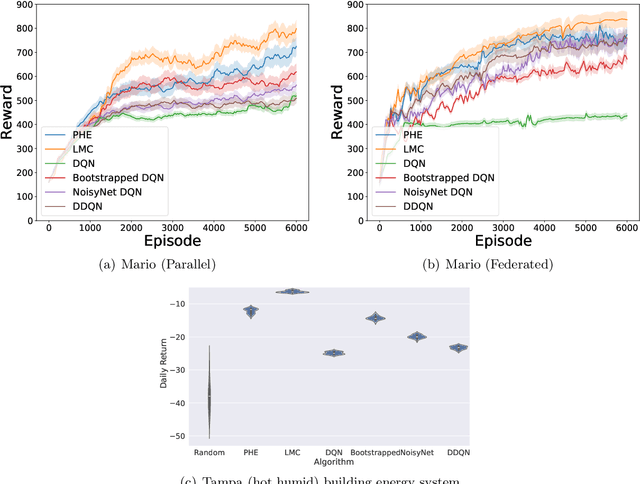
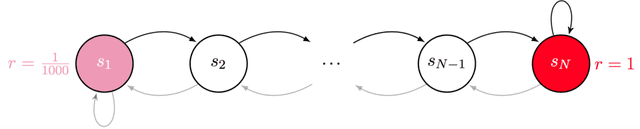
We present the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning (MARL). We propose a unified algorithm framework for randomized exploration in parallel Markov Decision Processes (MDPs), and two Thompson Sampling (TS)-type algorithms, CoopTS-PHE and CoopTS-LMC, incorporating the perturbed-history exploration (PHE) strategy and the Langevin Monte Carlo exploration (LMC) strategy respectively, which are flexible in design and easy to implement in practice. For a special class of parallel MDPs where the transition is (approximately) linear, we theoretically prove that both CoopTS-PHE and CoopTS-LMC achieve a $\widetilde{\mathcal{O}}(d^{3/2}H^2\sqrt{MK})$ regret bound with communication complexity $\widetilde{\mathcal{O}}(dHM^2)$, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the number of agents, and $K$ is the number of episodes. This is the first theoretical result for randomized exploration in cooperative MARL. We evaluate our proposed method on multiple parallel RL environments, including a deep exploration problem (\textit{i.e.,} $N$-chain), a video game, and a real-world problem in energy systems. Our experimental results support that our framework can achieve better performance, even under conditions of misspecified transition models. Additionally, we establish a connection between our unified framework and the practical application of federated learning.
ε-Neural Thompson Sampling of Deep Brain Stimulation for Parkinson Disease Treatment
Mar 11, 2024



Deep Brain Stimulation (DBS) stands as an effective intervention for alleviating the motor symptoms of Parkinson's disease (PD). Traditional commercial DBS devices are only able to deliver fixed-frequency periodic pulses to the basal ganglia (BG) regions of the brain, i.e., continuous DBS (cDBS). However, they in general suffer from energy inefficiency and side effects, such as speech impairment. Recent research has focused on adaptive DBS (aDBS) to resolve the limitations of cDBS. Specifically, reinforcement learning (RL) based approaches have been developed to adapt the frequencies of the stimuli in order to achieve both energy efficiency and treatment efficacy. However, RL approaches in general require significant amount of training data and computational resources, making it intractable to integrate RL policies into real-time embedded systems as needed in aDBS. In contrast, contextual multi-armed bandits (CMAB) in general lead to better sample efficiency compared to RL. In this study, we propose a CMAB solution for aDBS. Specifically, we define the context as the signals capturing irregular neuronal firing activities in the BG regions (i.e., beta-band power spectral density), while each arm signifies the (discretized) pulse frequency of the stimulation. Moreover, an {\epsilon}-exploring strategy is introduced on top of the classic Thompson sampling method, leading to an algorithm called {\epsilon}-Neural Thompson sampling ({\epsilon}-NeuralTS), such that the learned CMAB policy can better balance exploration and exploitation of the BG environment. The {\epsilon}-NeuralTS algorithm is evaluated using a computation BG model that captures the neuronal activities in PD patients' brains. The results show that our method outperforms both existing cDBS methods and CMAB baselines.
Finite-Time Frequentist Regret Bounds of Multi-Agent Thompson Sampling on Sparse Hypergraphs
Dec 24, 2023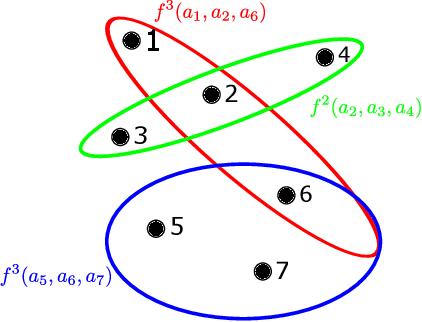



We study the multi-agent multi-armed bandit (MAMAB) problem, where $m$ agents are factored into $\rho$ overlapping groups. Each group represents a hyperedge, forming a hypergraph over the agents. At each round of interaction, the learner pulls a joint arm (composed of individual arms for each agent) and receives a reward according to the hypergraph structure. Specifically, we assume there is a local reward for each hyperedge, and the reward of the joint arm is the sum of these local rewards. Previous work introduced the multi-agent Thompson sampling (MATS) algorithm \citep{verstraeten2020multiagent} and derived a Bayesian regret bound. However, it remains an open problem how to derive a frequentist regret bound for Thompson sampling in this multi-agent setting. To address these issues, we propose an efficient variant of MATS, the $\epsilon$-exploring Multi-Agent Thompson Sampling ($\epsilon$-MATS) algorithm, which performs MATS exploration with probability $\epsilon$ while adopts a greedy policy otherwise. We prove that $\epsilon$-MATS achieves a worst-case frequentist regret bound that is sublinear in both the time horizon and the local arm size. We also derive a lower bound for this setting, which implies our frequentist regret upper bound is optimal up to constant and logarithm terms, when the hypergraph is sufficiently sparse. Thorough experiments on standard MAMAB problems demonstrate the superior performance and the improved computational efficiency of $\epsilon$-MATS compared with existing algorithms in the same setting.
Robust Reinforcement Learning through Efficient Adversarial Herding
Jun 12, 2023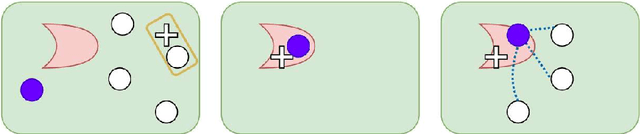
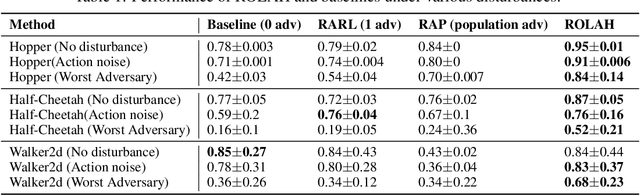
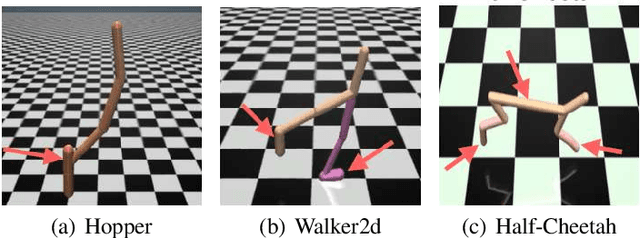
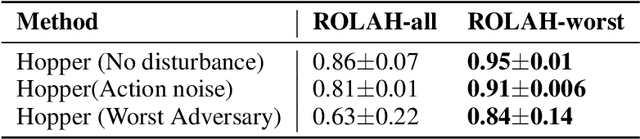
Although reinforcement learning (RL) is considered the gold standard for policy design, it may not always provide a robust solution in various scenarios. This can result in severe performance degradation when the environment is exposed to potential disturbances. Adversarial training using a two-player max-min game has been proven effective in enhancing the robustness of RL agents. In this work, we extend the two-player game by introducing an adversarial herd, which involves a group of adversaries, in order to address ($\textit{i}$) the difficulty of the inner optimization problem, and ($\textit{ii}$) the potential over pessimism caused by the selection of a candidate adversary set that may include unlikely scenarios. We first prove that adversarial herds can efficiently approximate the inner optimization problem. Then we address the second issue by replacing the worst-case performance in the inner optimization with the average performance over the worst-$k$ adversaries. We evaluate the proposed method on multiple MuJoCo environments. Experimental results demonstrate that our approach consistently generates more robust policies.
Improving Safety in Deep Reinforcement Learning using Unsupervised Action Planning
Sep 29, 2021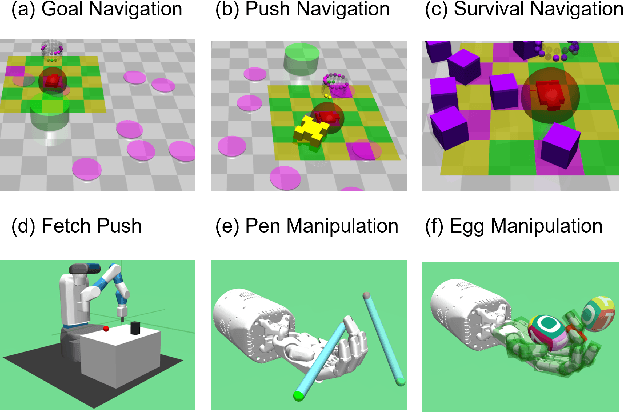
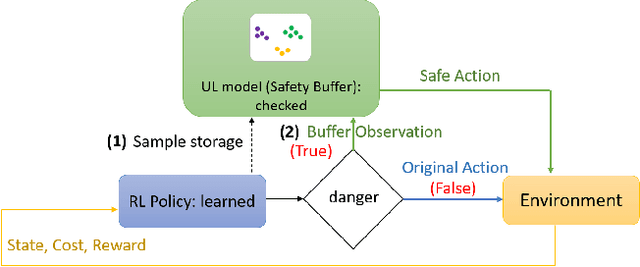
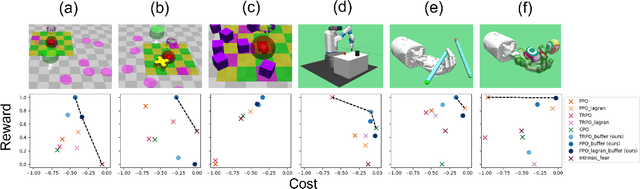
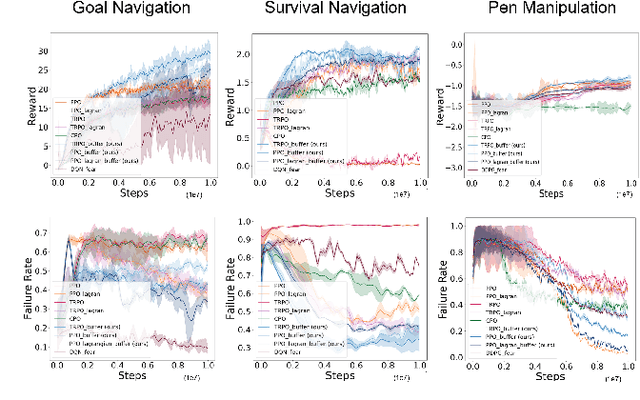
One of the key challenges to deep reinforcement learning (deep RL) is to ensure safety at both training and testing phases. In this work, we propose a novel technique of unsupervised action planning to improve the safety of on-policy reinforcement learning algorithms, such as trust region policy optimization (TRPO) or proximal policy optimization (PPO). We design our safety-aware reinforcement learning by storing all the history of "recovery" actions that rescue the agent from dangerous situations into a separate "safety" buffer and finding the best recovery action when the agent encounters similar states. Because this functionality requires the algorithm to query similar states, we implement the proposed safety mechanism using an unsupervised learning algorithm, k-means clustering. We evaluate the proposed algorithm on six robotic control tasks that cover navigation and manipulation. Our results show that the proposed safety RL algorithm can achieve higher rewards compared with multiple baselines in both discrete and continuous control problems. The supplemental video can be found at: https://youtu.be/AFTeWSohILo.