 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransmission Line Outage Probability Prediction Under Extreme Events Using Peter-Clark Bayesian Structural Learning
Nov 18, 2024
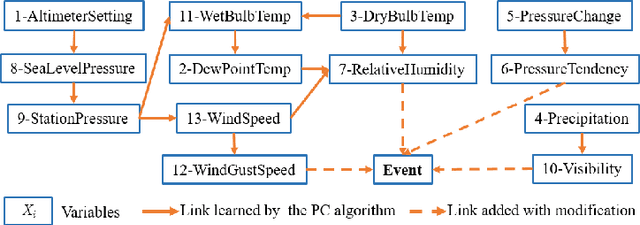
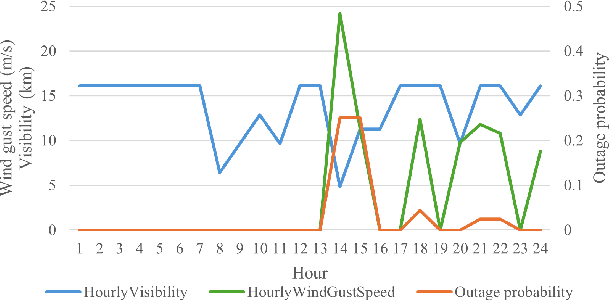
Recent years have seen a notable increase in the frequency and intensity of extreme weather events. With a rising number of power outages caused by these events, accurate prediction of power line outages is essential for safe and reliable operation of power grids. The Bayesian network is a probabilistic model that is very effective for predicting line outages under weather-related uncertainties. However, most existing studies in this area offer general risk assessments, but fall short of providing specific outage probabilities. In this work, we introduce a novel approach for predicting transmission line outage probabilities using a Bayesian network combined with Peter-Clark (PC) structural learning. Our approach not only enables precise outage probability calculations, but also demonstrates better scalability and robust performance, even with limited data. Case studies using data from BPA and NOAA show the effectiveness of this approach, while comparisons with several existing methods further highlight its advantages.
Quantifying and Predicting Residential Building Flexibility Using Machine Learning Methods
Mar 04, 2024Residential buildings account for a significant portion (35\%) of the total electricity consumption in the U.S. as of 2022. As more distributed energy resources are installed in buildings, their potential to provide flexibility to the grid increases. To tap into that flexibility provided by buildings, aggregators or system operators need to quantify and forecast flexibility. Previous works in this area primarily focused on commercial buildings, with little work on residential buildings. To address the gap, this paper first proposes two complementary flexibility metrics (i.e., power and energy flexibility) and then investigates several mainstream machine learning-based models for predicting the time-variant and sporadic flexibility of residential buildings at four-hour and 24-hour forecast horizons. The long-short-term-memory (LSTM) model achieves the best performance and can predict power flexibility for up to 24 hours ahead with the average error around 0.7 kW. However, for energy flexibility, the LSTM model is only successful for loads with consistent operational patterns throughout the year and faces challenges when predicting energy flexibility associated with HVAC systems.
Resilient Control of Networked Microgrids using Vertical Federated Reinforcement Learning: Designs and Real-Time Test-Bed Validations
Nov 21, 2023



Improving system-level resiliency of networked microgrids is an important aspect with increased population of inverter-based resources (IBRs). This paper (1) presents resilient control design in presence of adversarial cyber-events, and proposes a novel federated reinforcement learning (Fed-RL) approach to tackle (a) model complexities, unknown dynamical behaviors of IBR devices, (b) privacy issues regarding data sharing in multi-party-owned networked grids, and (2) transfers learned controls from simulation to hardware-in-the-loop test-bed, thereby bridging the gap between simulation and real world. With these multi-prong objectives, first, we formulate a reinforcement learning (RL) training setup generating episodic trajectories with adversaries (attack signal) injected at the primary controllers of the grid forming (GFM) inverters where RL agents (or controllers) are being trained to mitigate the injected attacks. For networked microgrids, the horizontal Fed-RL method involving distinct independent environments is not appropriate, leading us to develop vertical variant Federated Soft Actor-Critic (FedSAC) algorithm to grasp the interconnected dynamics of networked microgrid. Next, utilizing OpenAI Gym interface, we built a custom simulation set-up in GridLAB-D/HELICS co-simulation platform, named Resilient RL Co-simulation (ResRLCoSIM), to train the RL agents with IEEE 123-bus benchmark test systems comprising 3 interconnected microgrids. Finally, the learned policies in simulation world are transferred to the real-time hardware-in-the-loop test-bed set-up developed using high-fidelity Hypersim platform. Experiments show that the simulator-trained RL controllers produce convincing results with the real-time test-bed set-up, validating the minimization of sim-to-real gap.
Enhancing Cyber Resilience of Networked Microgrids using Vertical Federated Reinforcement Learning
Dec 17, 2022



This paper presents a novel federated reinforcement learning (Fed-RL) methodology to enhance the cyber resiliency of networked microgrids. We formulate a resilient reinforcement learning (RL) training setup which (a) generates episodic trajectories injecting adversarial actions at primary control reference signals of the grid forming (GFM) inverters and (b) trains the RL agents (or controllers) to alleviate the impact of the injected adversaries. To circumvent data-sharing issues and concerns for proprietary privacy in multi-party-owned networked grids, we bring in the aspects of federated machine learning and propose a novel Fed-RL algorithm to train the RL agents. To this end, the conventional horizontal Fed-RL approaches using decoupled independent environments fail to capture the coupled dynamics in a networked microgrid, which leads us to propose a multi-agent vertically federated variation of actor-critic algorithms, namely federated soft actor-critic (FedSAC) algorithm. We created a customized simulation setup encapsulating microgrid dynamics in the GridLAB-D/HELICS co-simulation platform compatible with the OpenAI Gym interface for training RL agents. Finally, the proposed methodology is validated with numerical examples of modified IEEE 123-bus benchmark test systems consisting of three coupled microgrids.
Efficient Learning of Voltage Control Strategies via Model-based Deep Reinforcement Learning
Dec 06, 2022This article proposes a model-based deep reinforcement learning (DRL) method to design emergency control strategies for short-term voltage stability problems in power systems. Recent advances show promising results in model-free DRL-based methods for power systems, but model-free methods suffer from poor sample efficiency and training time, both critical for making state-of-the-art DRL algorithms practically applicable. DRL-agent learns an optimal policy via a trial-and-error method while interacting with the real-world environment. And it is desirable to minimize the direct interaction of the DRL agent with the real-world power grid due to its safety-critical nature. Additionally, state-of-the-art DRL-based policies are mostly trained using a physics-based grid simulator where dynamic simulation is computationally intensive, lowering the training efficiency. We propose a novel model-based-DRL framework where a deep neural network (DNN)-based dynamic surrogate model, instead of a real-world power-grid or physics-based simulation, is utilized with the policy learning framework, making the process faster and sample efficient. However, stabilizing model-based DRL is challenging because of the complex system dynamics of large-scale power systems. We solved these issues by incorporating imitation learning to have a warm start in policy learning, reward-shaping, and multi-step surrogate loss. Finally, we achieved 97.5% sample efficiency and 87.7% training efficiency for an application to the IEEE 300-bus test system.
Safe Reinforcement Learning for Grid Voltage Control
Dec 02, 2021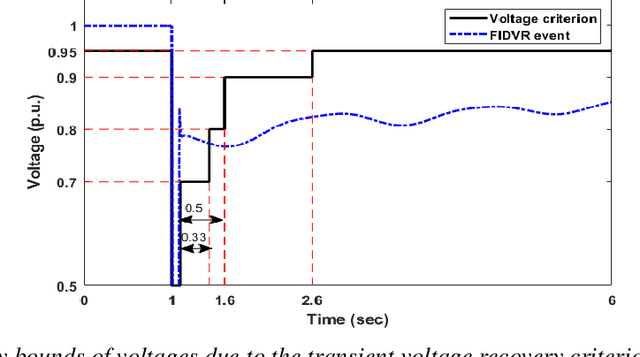
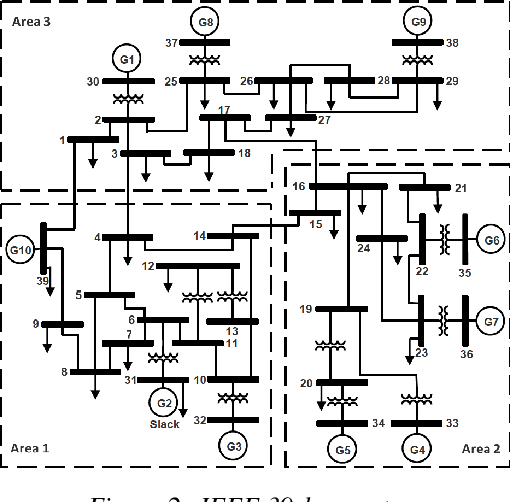
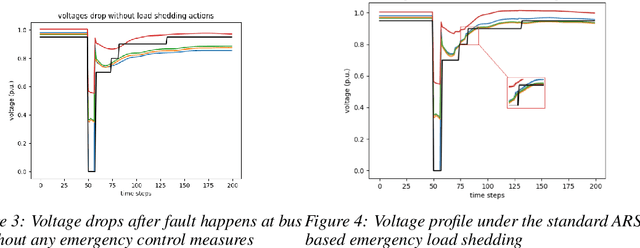
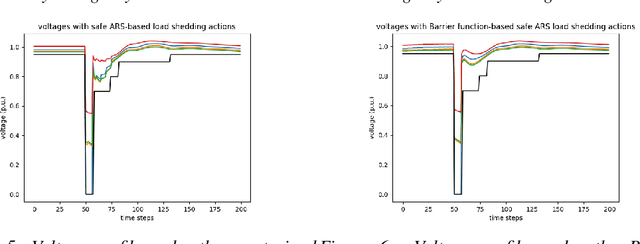
Under voltage load shedding has been considered as a standard approach to recover the voltage stability of the electric power grid under emergency conditions, yet this scheme usually trips a massive amount of load inefficiently. Reinforcement learning (RL) has been adopted as a promising approach to circumvent the issues; however, RL approach usually cannot guarantee the safety of the systems under control. In this paper, we discuss a couple of novel safe RL approaches, namely constrained optimization approach and Barrier function-based approach, that can safely recover voltage under emergency events. This method is general and can be applied to other safety-critical control problems. Numerical simulations on the 39-bus IEEE benchmark are performed to demonstrate the effectiveness of the proposed safe RL emergency control.
Physics-informed Evolutionary Strategy based Control for Mitigating Delayed Voltage Recovery
Nov 29, 2021



In this work we propose a novel data-driven, real-time power system voltage control method based on the physics-informed guided meta evolutionary strategy (ES). The main objective is to quickly provide an adaptive control strategy to mitigate the fault-induced delayed voltage recovery (FIDVR) problem. Reinforcement learning methods have been developed for the same or similar challenging control problems, but they suffer from training inefficiency and lack of robustness for "corner or unseen" scenarios. On the other hand, extensive physical knowledge has been developed in power systems but little has been leveraged in learning-based approaches. To address these challenges, we introduce the trainable action mask technique for flexibly embedding physical knowledge into RL models to rule out unnecessary or unfavorable actions, and achieve notable improvements in sample efficiency, control performance and robustness. Furthermore, our method leverages past learning experience to derive surrogate gradient to guide and accelerate the exploration process in training. Case studies on the IEEE 300-bus system and comparisons with other state-of-the-art benchmark methods demonstrate effectiveness and advantages of our method.
Learning to run a power network with trust
Oct 21, 2021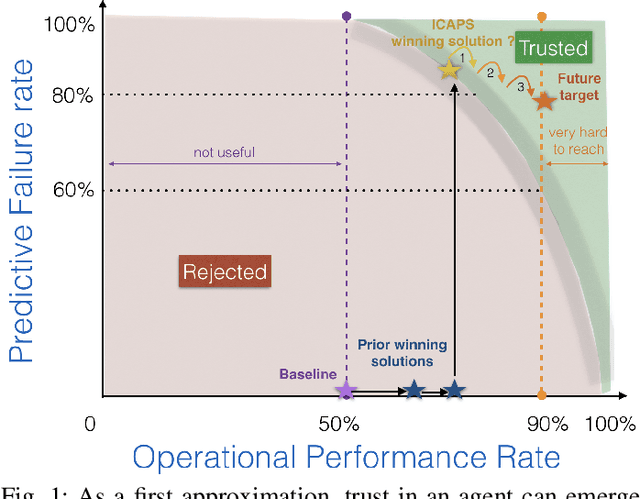
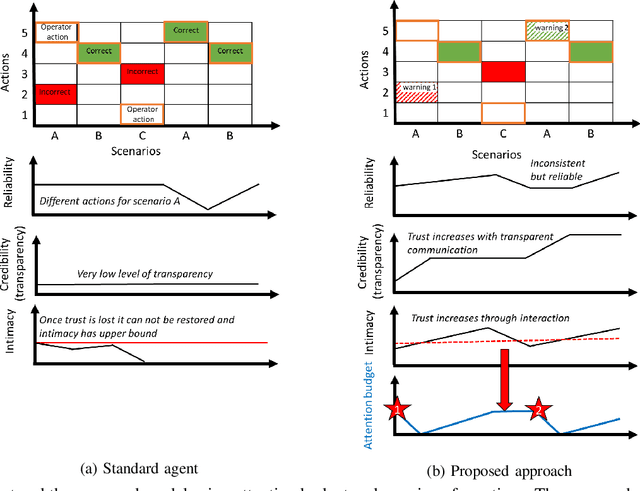
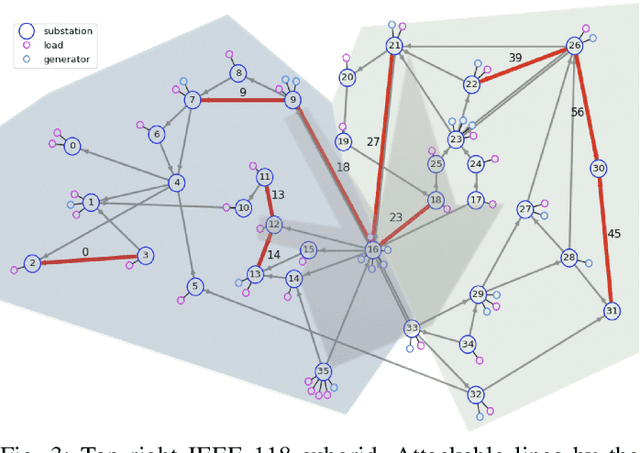
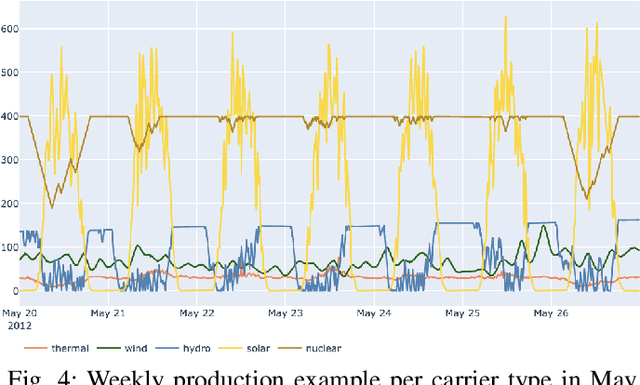
Artificial agents are promising for realtime power system operations, particularly, to compute remedial actions for congestion management. Currently, these agents are limited to only autonomously run by themselves. However, autonomous agents will not be deployed any time soon. Operators will still be in charge of taking action in the future. Aiming at designing an assistant for operators, we here consider humans in the loop and propose an original formulation for this problem. We first advance an agent with the ability to send to the operator alarms ahead of time when the proposed actions are of low confidence. We further model the operator's available attention as a budget that decreases when alarms are sent. We present the design and results of our competition "Learning to run a power network with trust" in which we benchmark the ability of submitted agents to send relevant alarms while operating the network to their best.
Improving Safety in Deep Reinforcement Learning using Unsupervised Action Planning
Sep 29, 2021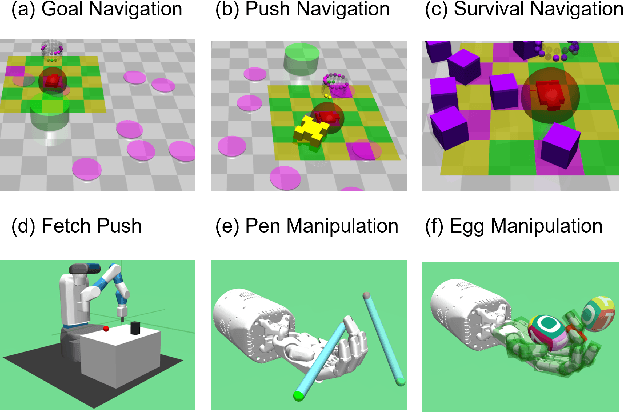
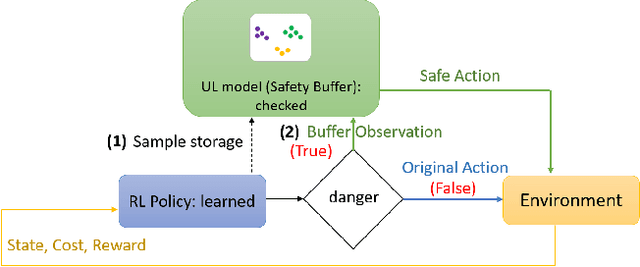
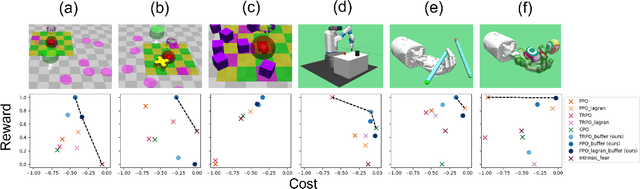
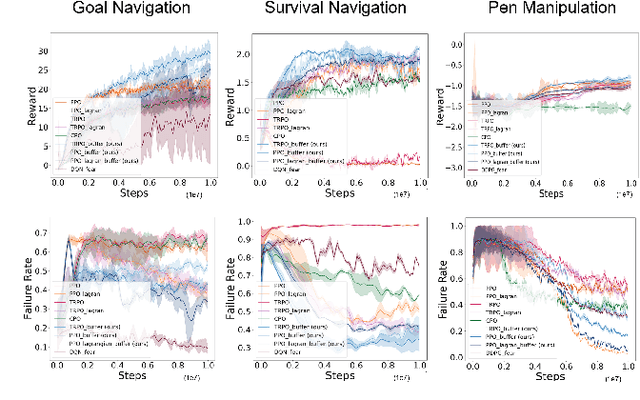
One of the key challenges to deep reinforcement learning (deep RL) is to ensure safety at both training and testing phases. In this work, we propose a novel technique of unsupervised action planning to improve the safety of on-policy reinforcement learning algorithms, such as trust region policy optimization (TRPO) or proximal policy optimization (PPO). We design our safety-aware reinforcement learning by storing all the history of "recovery" actions that rescue the agent from dangerous situations into a separate "safety" buffer and finding the best recovery action when the agent encounters similar states. Because this functionality requires the algorithm to query similar states, we implement the proposed safety mechanism using an unsupervised learning algorithm, k-means clustering. We evaluate the proposed algorithm on six robotic control tasks that cover navigation and manipulation. Our results show that the proposed safety RL algorithm can achieve higher rewards compared with multiple baselines in both discrete and continuous control problems. The supplemental video can be found at: https://youtu.be/AFTeWSohILo.
Scalable Voltage Control using Structure-Driven Hierarchical Deep Reinforcement Learning
Jan 29, 2021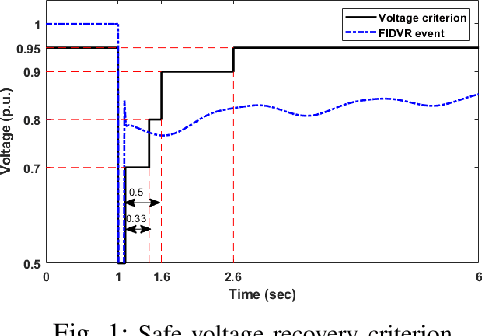
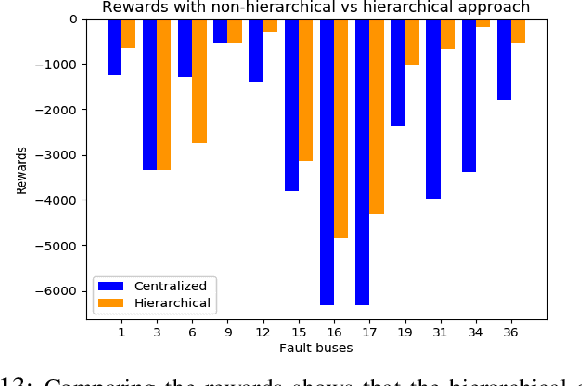
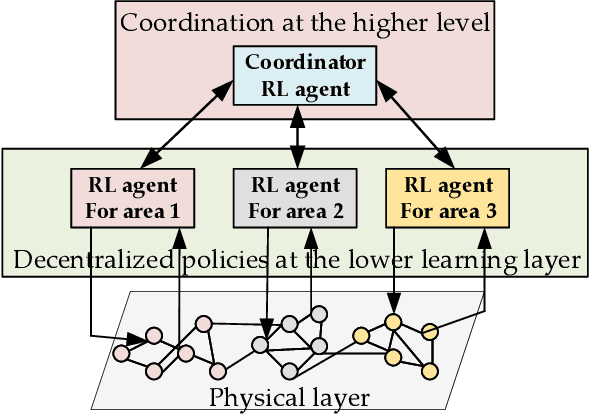
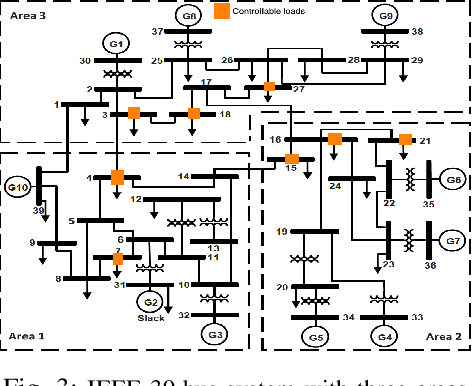
This paper presents a novel hierarchical deep reinforcement learning (DRL) based design for the voltage control of power grids. DRL agents are trained for fast, and adaptive selection of control actions such that the voltage recovery criterion can be met following disturbances. Existing voltage control techniques suffer from the issues of speed of operation, optimal coordination between different locations, and scalability. We exploit the area-wise division structure of the power system to propose a hierarchical DRL design that can be scaled to the larger grid models. We employ an enhanced augmented random search algorithm that is tailored for the voltage control problem in a two-level architecture. We train area-wise decentralized RL agents to compute lower-level policies for the individual areas, and concurrently train a higher-level DRL agent that uses the updates of the lower-level policies to efficiently coordinate the control actions taken by the lower-level agents. Numerical experiments on the IEEE benchmark 39-bus model with 3 areas demonstrate the advantages and various intricacies of the proposed hierarchical approach.