 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Control of Networked Microgrids using Vertical Federated Reinforcement Learning: Designs and Real-Time Test-Bed Validations
Nov 21, 2023



Improving system-level resiliency of networked microgrids is an important aspect with increased population of inverter-based resources (IBRs). This paper (1) presents resilient control design in presence of adversarial cyber-events, and proposes a novel federated reinforcement learning (Fed-RL) approach to tackle (a) model complexities, unknown dynamical behaviors of IBR devices, (b) privacy issues regarding data sharing in multi-party-owned networked grids, and (2) transfers learned controls from simulation to hardware-in-the-loop test-bed, thereby bridging the gap between simulation and real world. With these multi-prong objectives, first, we formulate a reinforcement learning (RL) training setup generating episodic trajectories with adversaries (attack signal) injected at the primary controllers of the grid forming (GFM) inverters where RL agents (or controllers) are being trained to mitigate the injected attacks. For networked microgrids, the horizontal Fed-RL method involving distinct independent environments is not appropriate, leading us to develop vertical variant Federated Soft Actor-Critic (FedSAC) algorithm to grasp the interconnected dynamics of networked microgrid. Next, utilizing OpenAI Gym interface, we built a custom simulation set-up in GridLAB-D/HELICS co-simulation platform, named Resilient RL Co-simulation (ResRLCoSIM), to train the RL agents with IEEE 123-bus benchmark test systems comprising 3 interconnected microgrids. Finally, the learned policies in simulation world are transferred to the real-time hardware-in-the-loop test-bed set-up developed using high-fidelity Hypersim platform. Experiments show that the simulator-trained RL controllers produce convincing results with the real-time test-bed set-up, validating the minimization of sim-to-real gap.
Enhancing Cyber Resilience of Networked Microgrids using Vertical Federated Reinforcement Learning
Dec 17, 2022This paper presents a novel federated reinforcement learning (Fed-RL) methodology to enhance the cyber resiliency of networked microgrids. We formulate a resilient reinforcement learning (RL) training setup which (a) generates episodic trajectories injecting adversarial actions at primary control reference signals of the grid forming (GFM) inverters and (b) trains the RL agents (or controllers) to alleviate the impact of the injected adversaries. To circumvent data-sharing issues and concerns for proprietary privacy in multi-party-owned networked grids, we bring in the aspects of federated machine learning and propose a novel Fed-RL algorithm to train the RL agents. To this end, the conventional horizontal Fed-RL approaches using decoupled independent environments fail to capture the coupled dynamics in a networked microgrid, which leads us to propose a multi-agent vertically federated variation of actor-critic algorithms, namely federated soft actor-critic (FedSAC) algorithm. We created a customized simulation setup encapsulating microgrid dynamics in the GridLAB-D/HELICS co-simulation platform compatible with the OpenAI Gym interface for training RL agents. Finally, the proposed methodology is validated with numerical examples of modified IEEE 123-bus benchmark test systems consisting of three coupled microgrids.
Developing and Validating Semi-Markov Occupancy Generative Models: A Technical Report
Dec 21, 2021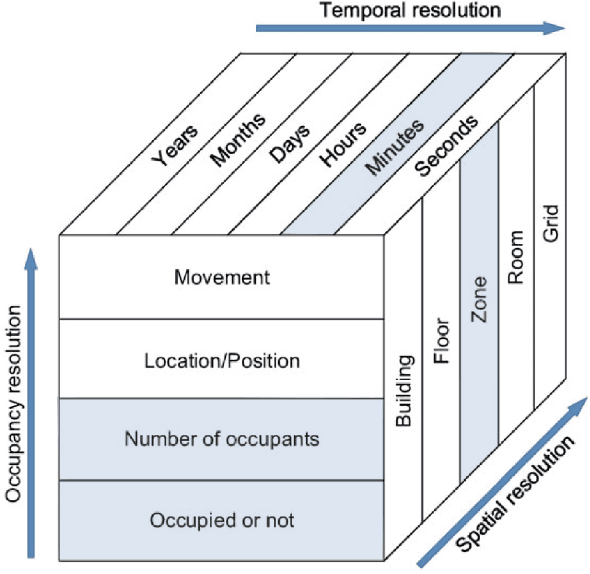

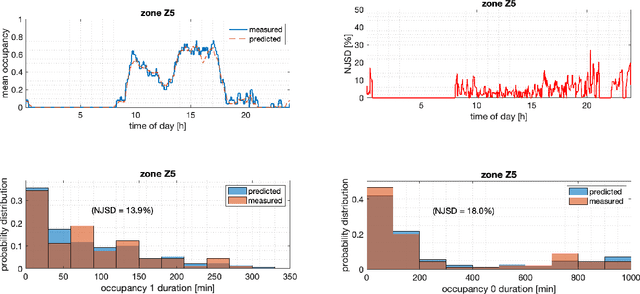

This report documents recent technical work on developing and validating stochastic occupancy models in commercial buildings, performed by the Pacific Northwest National Laboratory (PNNL) as part of the Sensor Impact Evaluation and Verification project under the U.S. Department of Energy (DOE) Building Technologies Office (BTO). In this report, we present our work on developing and validating inhomogeneous semi-Markov chain models for generating sequences of zone-level occupancy presence and occupancy counts in a commercial building. Real datasets are used to learn and validate the generative occupancy models. Relevant metrics such as normalized Jensen-Shannon distance (NJSD) are used to demonstrate the ability of the models to express realistic occupancy behavioral patterns.
A Secure Learning Control Strategy via Dynamic Camouflaging for Unknown Dynamical Systems under Attacks
Feb 01, 2021



This paper presents a secure reinforcement learning (RL) based control method for unknown linear time-invariant cyber-physical systems (CPSs) that are subjected to compositional attacks such as eavesdropping and covert attack. We consider the attack scenario where the attacker learns about the dynamic model during the exploration phase of the learning conducted by the designer to learn a linear quadratic regulator (LQR), and thereafter, use such information to conduct a covert attack on the dynamic system, which we refer to as doubly learning-based control and attack (DLCA) framework. We propose a dynamic camouflaging based attack-resilient reinforcement learning (ARRL) algorithm which can learn the desired optimal controller for the dynamic system, and at the same time, can inject sufficient misinformation in the estimation of system dynamics by the attacker. The algorithm is accompanied by theoretical guarantees and extensive numerical experiments on a consensus multi-agent system and on a benchmark power grid model.