 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient-Based EMT-in-the-Loop Learning to Mitigate Sub-Synchronous Control Interactions
Nov 08, 2025


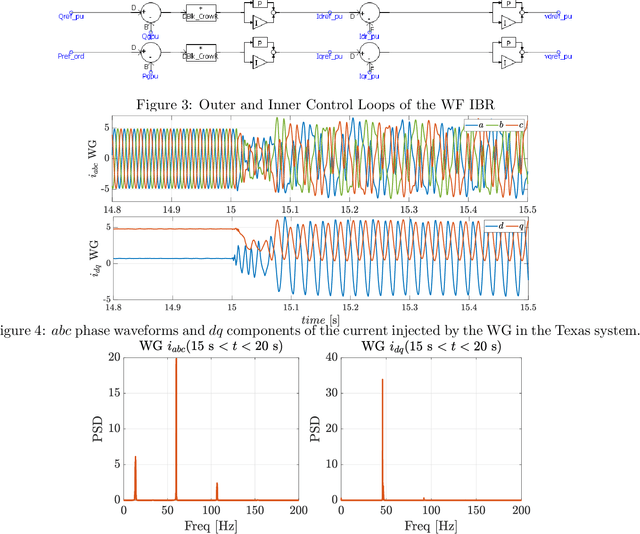
This paper explores the development of learning-based tunable control gains using EMT-in-the-loop simulation framework (e.g., PSCAD interfaced with Python-based learning modules) to address critical sub-synchronous oscillations. Since sub-synchronous control interactions (SSCI) arise from the mis-tuning of control gains under specific grid configurations, effective mitigation strategies require adaptive re-tuning of these gains. Such adaptiveness can be achieved by employing a closed-loop, learning-based framework that considers the grid conditions responsible for such sub-synchronous oscillations. This paper addresses this need by adopting methodologies inspired by Markov decision process (MDP) based reinforcement learning (RL), with a particular emphasis on simpler deep policy gradient methods with additional SSCI-specific signal processing modules such as down-sampling, bandpass filtering, and oscillation energy dependent reward computations. Our experimentation in a real-world event setting demonstrates that the deep policy gradient based trained policy can adaptively compute gain settings in response to varying grid conditions and optimally suppress control interaction-induced oscillations.
CoDe: Blockwise Control for Denoising Diffusion Models
Feb 03, 2025Aligning diffusion models to downstream tasks often requires finetuning new models or gradient-based guidance at inference time to enable sampling from the reward-tilted posterior. In this work, we explore a simple inference-time gradient-free guidance approach, called controlled denoising (CoDe), that circumvents the need for differentiable guidance functions and model finetuning. CoDe is a blockwise sampling method applied during intermediate denoising steps, allowing for alignment with downstream rewards. Our experiments demonstrate that, despite its simplicity, CoDe offers a favorable trade-off between reward alignment, prompt instruction following, and inference cost, achieving a competitive performance against the state-of-the-art baselines. Our code is available at: https://github.com/anujinho/code.
MAPL: Model Agnostic Peer-to-peer Learning
Mar 28, 2024



Effective collaboration among heterogeneous clients in a decentralized setting is a rather unexplored avenue in the literature. To structurally address this, we introduce Model Agnostic Peer-to-peer Learning (coined as MAPL) a novel approach to simultaneously learn heterogeneous personalized models as well as a collaboration graph through peer-to-peer communication among neighboring clients. MAPL is comprised of two main modules: (i) local-level Personalized Model Learning (PML), leveraging a combination of intra- and inter-client contrastive losses; (ii) network-wide decentralized Collaborative Graph Learning (CGL) dynamically refining collaboration weights in a privacy-preserving manner based on local task similarities. Our extensive experimentation demonstrates the efficacy of MAPL and its competitive (or, in most cases, superior) performance compared to its centralized model-agnostic counterparts, without relying on any central server. Our code is available and can be accessed here: https://github.com/SayakMukherjee/MAPL
Resilient Control of Networked Microgrids using Vertical Federated Reinforcement Learning: Designs and Real-Time Test-Bed Validations
Nov 21, 2023



Improving system-level resiliency of networked microgrids is an important aspect with increased population of inverter-based resources (IBRs). This paper (1) presents resilient control design in presence of adversarial cyber-events, and proposes a novel federated reinforcement learning (Fed-RL) approach to tackle (a) model complexities, unknown dynamical behaviors of IBR devices, (b) privacy issues regarding data sharing in multi-party-owned networked grids, and (2) transfers learned controls from simulation to hardware-in-the-loop test-bed, thereby bridging the gap between simulation and real world. With these multi-prong objectives, first, we formulate a reinforcement learning (RL) training setup generating episodic trajectories with adversaries (attack signal) injected at the primary controllers of the grid forming (GFM) inverters where RL agents (or controllers) are being trained to mitigate the injected attacks. For networked microgrids, the horizontal Fed-RL method involving distinct independent environments is not appropriate, leading us to develop vertical variant Federated Soft Actor-Critic (FedSAC) algorithm to grasp the interconnected dynamics of networked microgrid. Next, utilizing OpenAI Gym interface, we built a custom simulation set-up in GridLAB-D/HELICS co-simulation platform, named Resilient RL Co-simulation (ResRLCoSIM), to train the RL agents with IEEE 123-bus benchmark test systems comprising 3 interconnected microgrids. Finally, the learned policies in simulation world are transferred to the real-time hardware-in-the-loop test-bed set-up developed using high-fidelity Hypersim platform. Experiments show that the simulator-trained RL controllers produce convincing results with the real-time test-bed set-up, validating the minimization of sim-to-real gap.
AdverSAR: Adversarial Search and Rescue via Multi-Agent Reinforcement Learning
Dec 20, 2022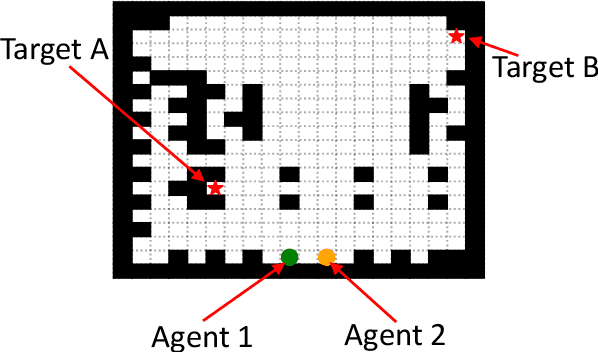
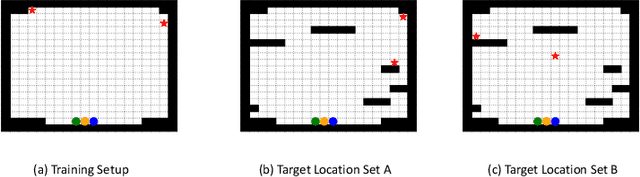
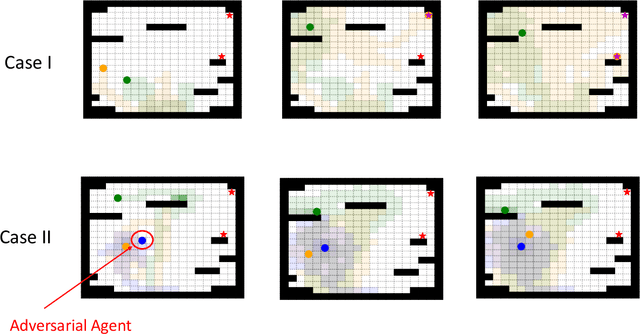
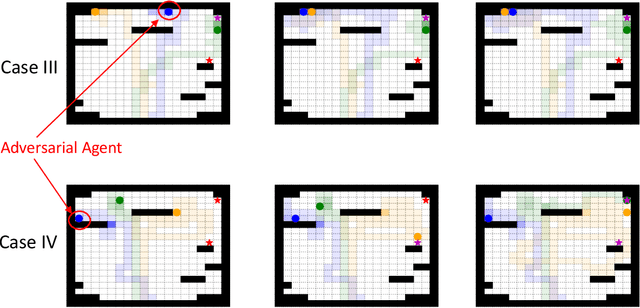
Search and Rescue (SAR) missions in remote environments often employ autonomous multi-robot systems that learn, plan, and execute a combination of local single-robot control actions, group primitives, and global mission-oriented coordination and collaboration. Often, SAR coordination strategies are manually designed by human experts who can remotely control the multi-robot system and enable semi-autonomous operations. However, in remote environments where connectivity is limited and human intervention is often not possible, decentralized collaboration strategies are needed for fully-autonomous operations. Nevertheless, decentralized coordination may be ineffective in adversarial environments due to sensor noise, actuation faults, or manipulation of inter-agent communication data. In this paper, we propose an algorithmic approach based on adversarial multi-agent reinforcement learning (MARL) that allows robots to efficiently coordinate their strategies in the presence of adversarial inter-agent communications. In our setup, the objective of the multi-robot team is to discover targets strategically in an obstacle-strewn geographical area by minimizing the average time needed to find the targets. It is assumed that the robots have no prior knowledge of the target locations, and they can interact with only a subset of neighboring robots at any time. Based on the centralized training with decentralized execution (CTDE) paradigm in MARL, we utilize a hierarchical meta-learning framework to learn dynamic team-coordination modalities and discover emergent team behavior under complex cooperative-competitive scenarios. The effectiveness of our approach is demonstrated on a collection of prototype grid-world environments with different specifications of benign and adversarial agents, target locations, and agent rewards.
Enhancing Cyber Resilience of Networked Microgrids using Vertical Federated Reinforcement Learning
Dec 17, 2022



This paper presents a novel federated reinforcement learning (Fed-RL) methodology to enhance the cyber resiliency of networked microgrids. We formulate a resilient reinforcement learning (RL) training setup which (a) generates episodic trajectories injecting adversarial actions at primary control reference signals of the grid forming (GFM) inverters and (b) trains the RL agents (or controllers) to alleviate the impact of the injected adversaries. To circumvent data-sharing issues and concerns for proprietary privacy in multi-party-owned networked grids, we bring in the aspects of federated machine learning and propose a novel Fed-RL algorithm to train the RL agents. To this end, the conventional horizontal Fed-RL approaches using decoupled independent environments fail to capture the coupled dynamics in a networked microgrid, which leads us to propose a multi-agent vertically federated variation of actor-critic algorithms, namely federated soft actor-critic (FedSAC) algorithm. We created a customized simulation setup encapsulating microgrid dynamics in the GridLAB-D/HELICS co-simulation platform compatible with the OpenAI Gym interface for training RL agents. Finally, the proposed methodology is validated with numerical examples of modified IEEE 123-bus benchmark test systems consisting of three coupled microgrids.
Neural Lyapunov Differentiable Predictive Control
May 22, 2022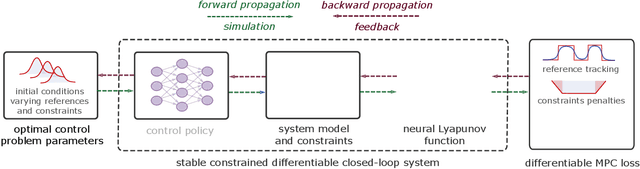
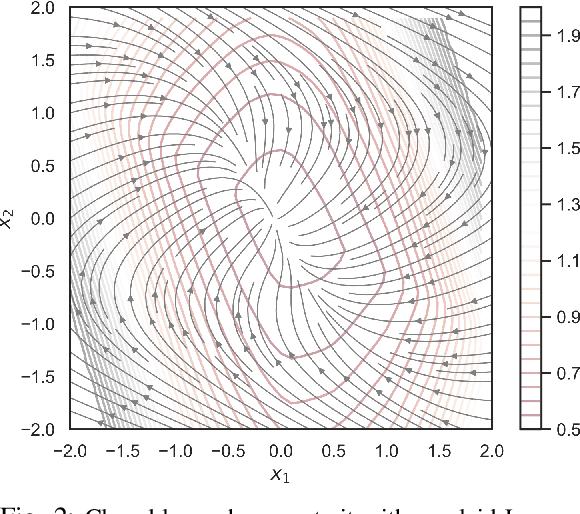
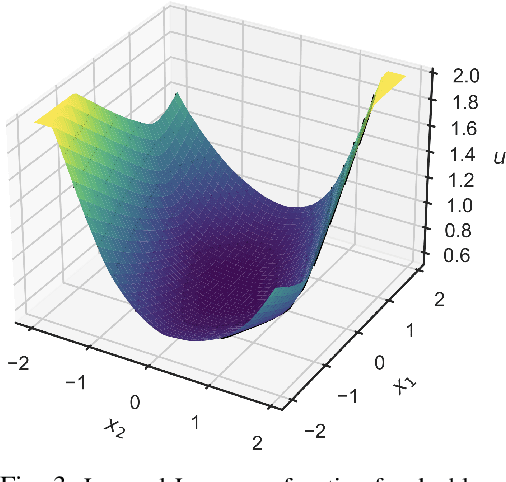
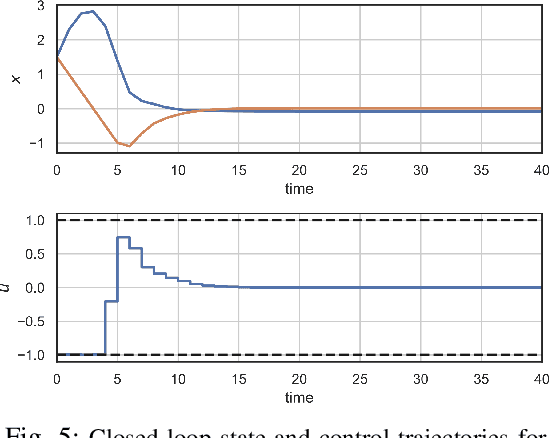
We present a learning-based predictive control methodology using the differentiable programming framework with probabilistic Lyapunov-based stability guarantees. The neural Lyapunov differentiable predictive control (NLDPC) learns the policy by constructing a computational graph encompassing the system dynamics, state and input constraints, and the necessary Lyapunov certification constraints, and thereafter using the automatic differentiation to update the neural policy parameters. In conjunction, our approach jointly learns a Lyapunov function that certifies the regions of state-space with stable dynamics. We also provide a sampling-based statistical guarantee for the training of NLDPC from the distribution of initial conditions. Our offline training approach provides a computationally efficient and scalable alternative to classical explicit model predictive control solutions. We substantiate the advantages of the proposed approach with simulations to stabilize the double integrator model and on an example of controlling an aircraft model.
Learning Stochastic Parametric Differentiable Predictive Control Policies
Mar 02, 2022
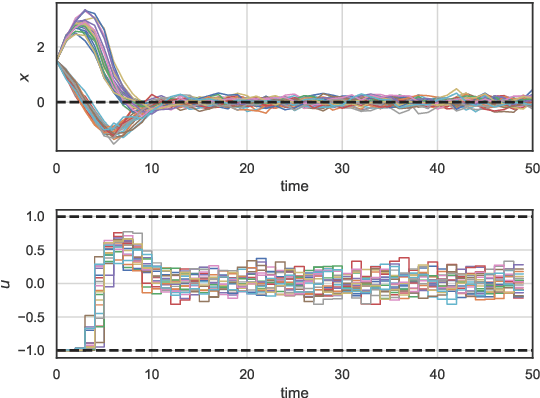
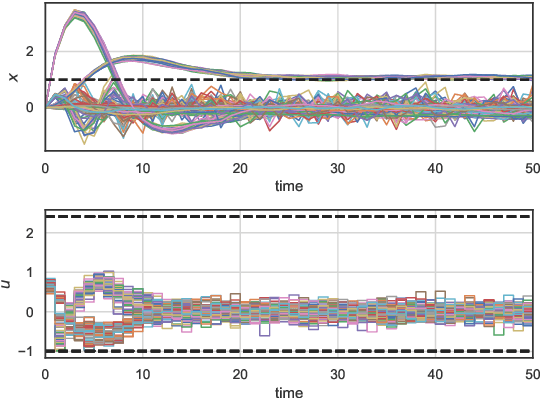
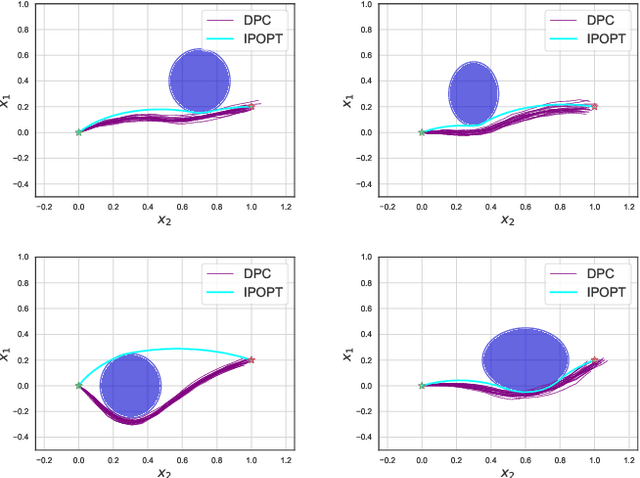
The problem of synthesizing stochastic explicit model predictive control policies is known to be quickly intractable even for systems of modest complexity when using classical control-theoretic methods. To address this challenge, we present a scalable alternative called stochastic parametric differentiable predictive control (SP-DPC) for unsupervised learning of neural control policies governing stochastic linear systems subject to nonlinear chance constraints. SP-DPC is formulated as a deterministic approximation to the stochastic parametric constrained optimal control problem. This formulation allows us to directly compute the policy gradients via automatic differentiation of the problem's value function, evaluated over sampled parameters and uncertainties. In particular, the computed expectation of the SP-DPC problem's value function is backpropagated through the closed-loop system rollouts parametrized by a known nominal system dynamics model and neural control policy which allows for direct model-based policy optimization. We provide theoretical probabilistic guarantees for policies learned via the SP-DPC method on closed-loop stability and chance constraints satisfaction. Furthermore, we demonstrate the computational efficiency and scalability of the proposed policy optimization algorithm in three numerical examples, including systems with a large number of states or subject to nonlinear constraints.
Safe Reinforcement Learning for Grid Voltage Control
Dec 02, 2021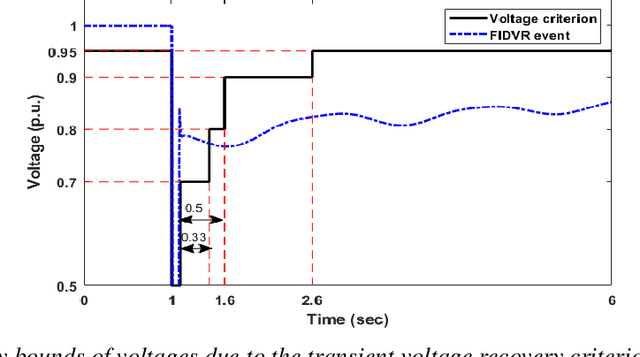
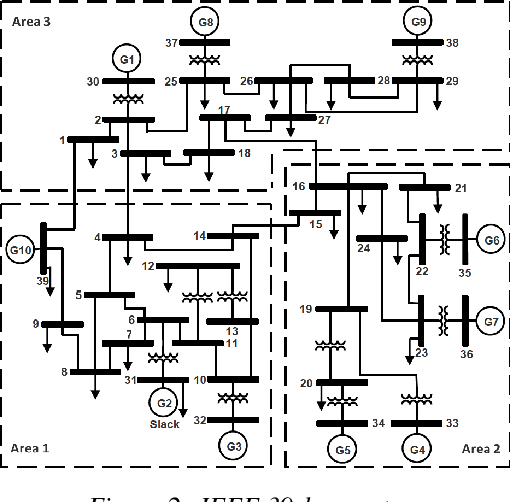
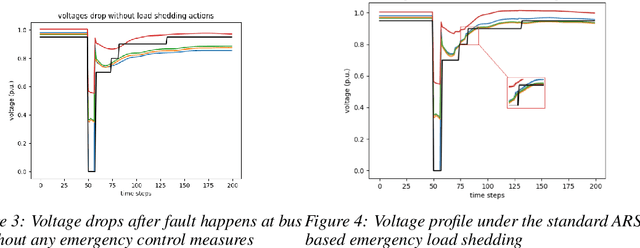
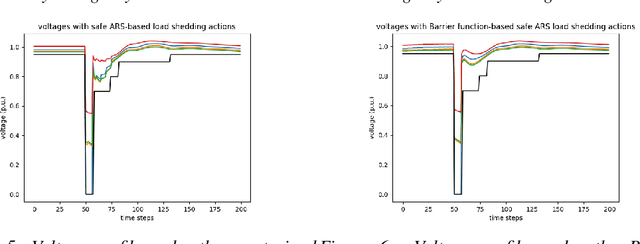
Under voltage load shedding has been considered as a standard approach to recover the voltage stability of the electric power grid under emergency conditions, yet this scheme usually trips a massive amount of load inefficiently. Reinforcement learning (RL) has been adopted as a promising approach to circumvent the issues; however, RL approach usually cannot guarantee the safety of the systems under control. In this paper, we discuss a couple of novel safe RL approaches, namely constrained optimization approach and Barrier function-based approach, that can safely recover voltage under emergency events. This method is general and can be applied to other safety-critical control problems. Numerical simulations on the 39-bus IEEE benchmark are performed to demonstrate the effectiveness of the proposed safe RL emergency control.
On the Stochastic Stability of Deep Markov Models
Nov 08, 2021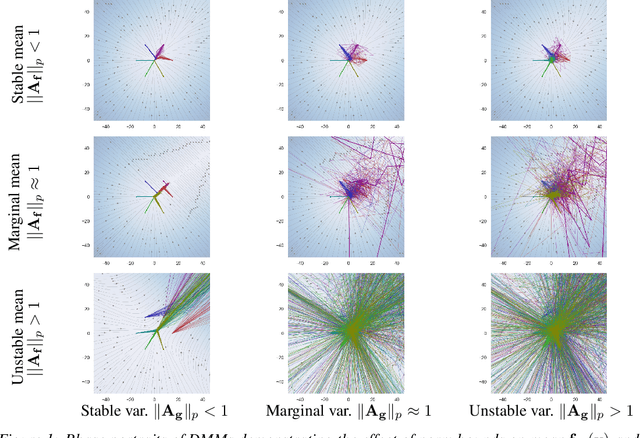


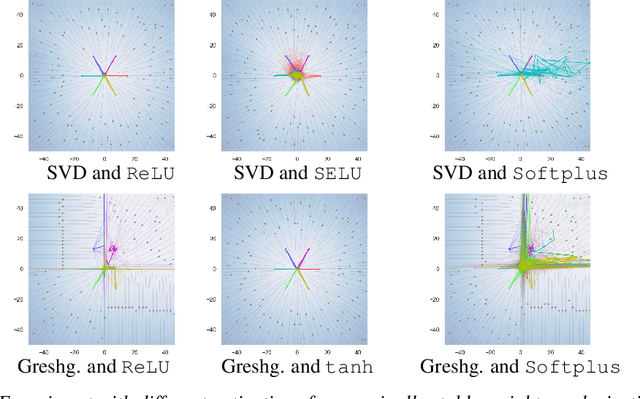
Deep Markov models (DMM) are generative models that are scalable and expressive generalization of Markov models for representation, learning, and inference problems. However, the fundamental stochastic stability guarantees of such models have not been thoroughly investigated. In this paper, we provide sufficient conditions of DMM's stochastic stability as defined in the context of dynamical systems and propose a stability analysis method based on the contraction of probabilistic maps modeled by deep neural networks. We make connections between the spectral properties of neural network's weights and different types of used activation functions on the stability and overall dynamic behavior of DMMs with Gaussian distributions. Based on the theory, we propose a few practical methods for designing constrained DMMs with guaranteed stability. We empirically substantiate our theoretical results via intuitive numerical experiments using the proposed stability constraints.