 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdverSAR: Adversarial Search and Rescue via Multi-Agent Reinforcement Learning
Dec 20, 2022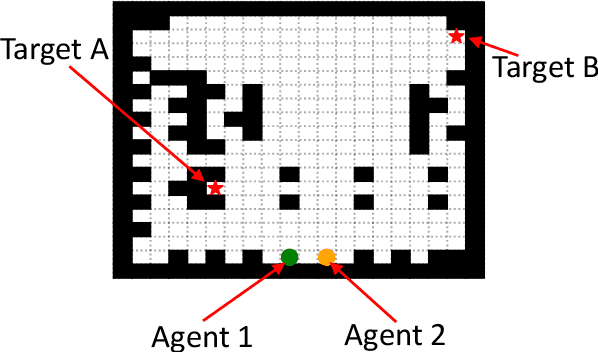
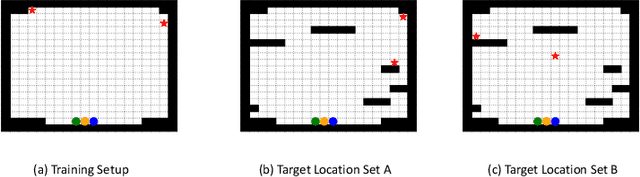
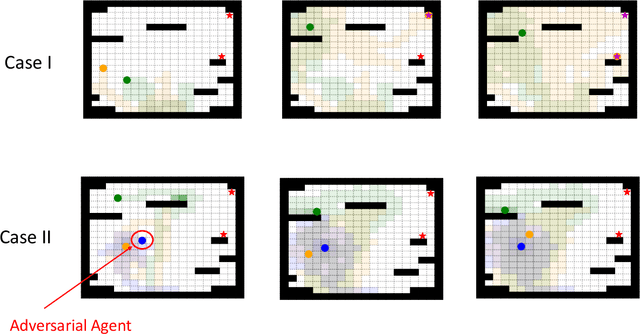
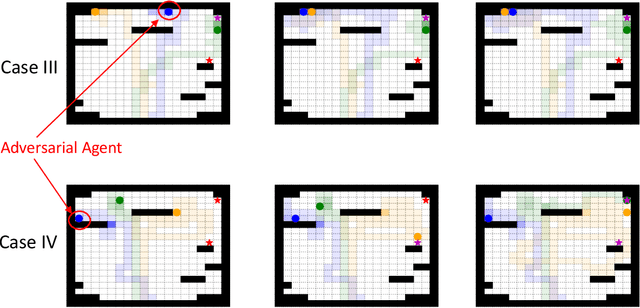
Search and Rescue (SAR) missions in remote environments often employ autonomous multi-robot systems that learn, plan, and execute a combination of local single-robot control actions, group primitives, and global mission-oriented coordination and collaboration. Often, SAR coordination strategies are manually designed by human experts who can remotely control the multi-robot system and enable semi-autonomous operations. However, in remote environments where connectivity is limited and human intervention is often not possible, decentralized collaboration strategies are needed for fully-autonomous operations. Nevertheless, decentralized coordination may be ineffective in adversarial environments due to sensor noise, actuation faults, or manipulation of inter-agent communication data. In this paper, we propose an algorithmic approach based on adversarial multi-agent reinforcement learning (MARL) that allows robots to efficiently coordinate their strategies in the presence of adversarial inter-agent communications. In our setup, the objective of the multi-robot team is to discover targets strategically in an obstacle-strewn geographical area by minimizing the average time needed to find the targets. It is assumed that the robots have no prior knowledge of the target locations, and they can interact with only a subset of neighboring robots at any time. Based on the centralized training with decentralized execution (CTDE) paradigm in MARL, we utilize a hierarchical meta-learning framework to learn dynamic team-coordination modalities and discover emergent team behavior under complex cooperative-competitive scenarios. The effectiveness of our approach is demonstrated on a collection of prototype grid-world environments with different specifications of benign and adversarial agents, target locations, and agent rewards.
Automated Adversary Emulation for Cyber-Physical Systems via Reinforcement Learning
Nov 09, 2020
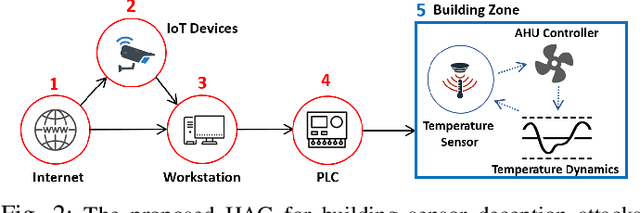
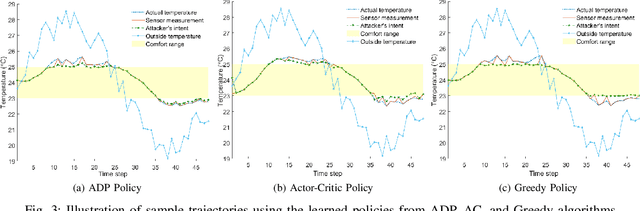

Adversary emulation is an offensive exercise that provides a comprehensive assessment of a system's resilience against cyber attacks. However, adversary emulation is typically a manual process, making it costly and hard to deploy in cyber-physical systems (CPS) with complex dynamics, vulnerabilities, and operational uncertainties. In this paper, we develop an automated, domain-aware approach to adversary emulation for CPS. We formulate a Markov Decision Process (MDP) model to determine an optimal attack sequence over a hybrid attack graph with cyber (discrete) and physical (continuous) components and related physical dynamics. We apply model-based and model-free reinforcement learning (RL) methods to solve the discrete-continuous MDP in a tractable fashion. As a baseline, we also develop a greedy attack algorithm and compare it with the RL procedures. We summarize our findings through a numerical study on sensor deception attacks in buildings to compare the performance and solution quality of the proposed algorithms.