 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Algorithms for Median Consensus Clustering in Complex Networks
Aug 21, 2024We develop an algorithm that finds the consensus of many different clustering solutions of a graph. We formulate the problem as a median set partitioning problem and propose a greedy optimization technique. Unlike other approaches that find median set partitions, our algorithm takes graph structure into account and finds a comparable quality solution much faster than the other approaches. For graphs with known communities, our consensus partition captures the actual community structure more accurately than alternative approaches. To make it applicable to large graphs, we remove sequential dependencies from our algorithm and design a parallel algorithm. Our parallel algorithm achieves 35x speedup when utilizing 64 processing cores for large real-world graphs from single-cell experiments.
HistoSPACE: Histology-Inspired Spatial Transcriptome Prediction And Characterization Engine
Aug 07, 2024



Spatial transcriptomics (ST) enables the visualization of gene expression within the context of tissue morphology. This emerging discipline has the potential to serve as a foundation for developing tools to design precision medicines. However, due to the higher costs and expertise required for such experiments, its translation into a regular clinical practice might be challenging. Despite the implementation of modern deep learning to enhance information obtained from histological images using AI, efforts have been constrained by limitations in the diversity of information. In this paper, we developed a model, HistoSPACE that explore the diversity of histological images available with ST data to extract molecular insights from tissue image. Our proposed study built an image encoder derived from universal image autoencoder. This image encoder was connected to convolution blocks to built the final model. It was further fine tuned with the help of ST-Data. This model is notably lightweight in compared to traditional histological models. Our developed model demonstrates significant efficiency compared to contemporary algorithms, revealing a correlation of 0.56 in leave-one-out cross-validation. Finally, its robustness was validated through an independent dataset, showing a well matched preditction with predefined disease pathology.
Unmasking unlearnable models: a classification challenge for biomedical images without visible cues
Jul 29, 2024
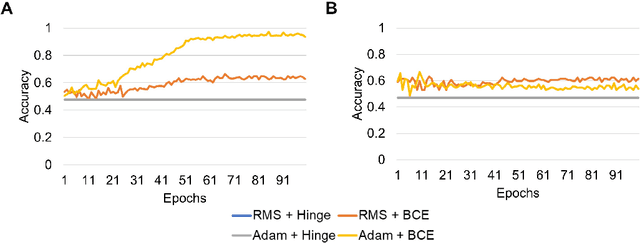
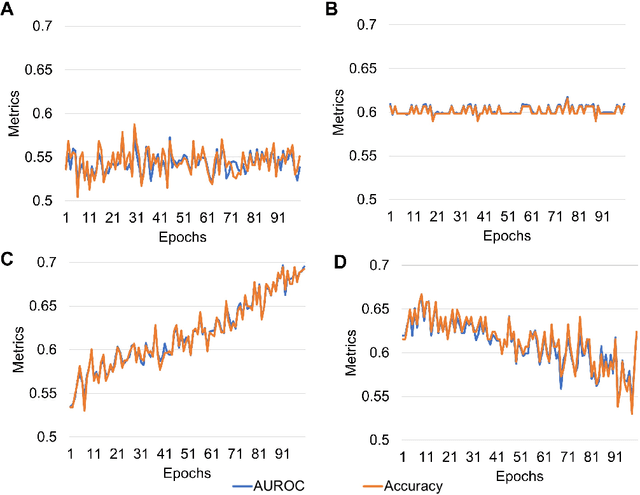
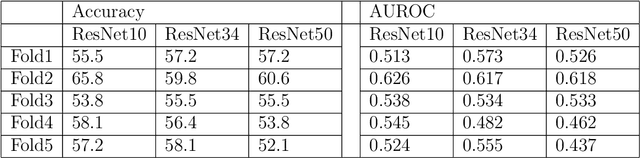
Predicting traits from images lacking visual cues is challenging, as algorithms are designed to capture visually correlated ground truth. This problem is critical in biomedical sciences, and their solution can improve the efficacy of non-invasive methods. For example, a recent challenge of predicting MGMT methylation status from MRI images is critical for treatment decisions of glioma patients. Using less robust models poses a significant risk in these critical scenarios and underscores the urgency of addressing this issue. Despite numerous efforts, contemporary models exhibit suboptimal performance, and underlying reasons for this limitation remain elusive. In this study, we demystify the complexity of MGMT status prediction through a comprehensive exploration by performing benchmarks of existing models adjoining transfer learning. Their architectures were further dissected by observing gradient flow across layers. Additionally, a feature selection strategy was applied to improve model interpretability. Our finding highlighted that current models are unlearnable and may require new architectures to explore applications in the real world. We believe our study will draw immediate attention and catalyse advancements in predictive modelling with non-visible cues.
Assessing the Impact of Distribution Shift on Reinforcement Learning Performance
Feb 05, 2024
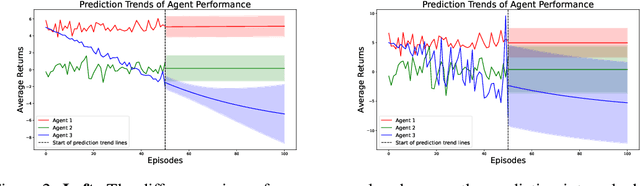
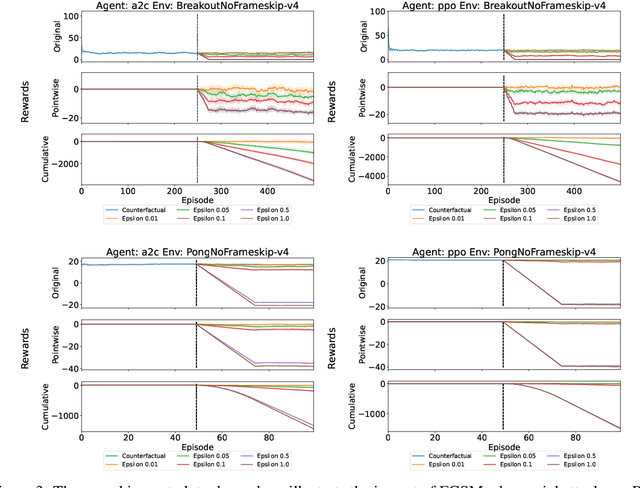
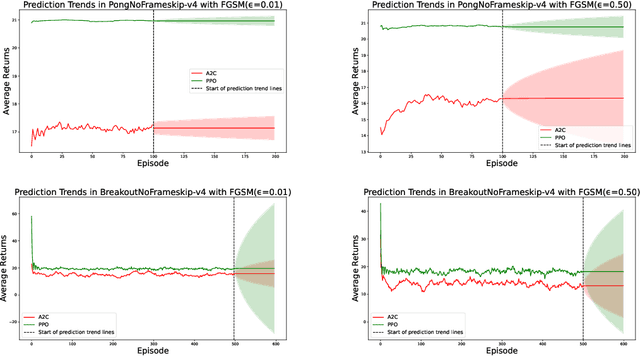
Research in machine learning is making progress in fixing its own reproducibility crisis. Reinforcement learning (RL), in particular, faces its own set of unique challenges. Comparison of point estimates, and plots that show successful convergence to the optimal policy during training, may obfuscate overfitting or dependence on the experimental setup. Although researchers in RL have proposed reliability metrics that account for uncertainty to better understand each algorithm's strengths and weaknesses, the recommendations of past work do not assume the presence of out-of-distribution observations. We propose a set of evaluation methods that measure the robustness of RL algorithms under distribution shifts. The tools presented here argue for the need to account for performance over time while the agent is acting in its environment. In particular, we recommend time series analysis as a method of observational RL evaluation. We also show that the unique properties of RL and simulated dynamic environments allow us to make stronger assumptions to justify the measurement of causal impact in our evaluations. We then apply these tools to single-agent and multi-agent environments to show the impact of introducing distribution shifts during test time. We present this methodology as a first step toward rigorous RL evaluation in the presence of distribution shifts.
Deep Reinforcement Learning for Cyber System Defense under Dynamic Adversarial Uncertainties
Feb 03, 2023



Development of autonomous cyber system defense strategies and action recommendations in the real-world is challenging, and includes characterizing system state uncertainties and attack-defense dynamics. We propose a data-driven deep reinforcement learning (DRL) framework to learn proactive, context-aware, defense countermeasures that dynamically adapt to evolving adversarial behaviors while minimizing loss of cyber system operations. A dynamic defense optimization problem is formulated with multiple protective postures against different types of adversaries with varying levels of skill and persistence. A custom simulation environment was developed and experiments were devised to systematically evaluate the performance of four model-free DRL algorithms against realistic, multi-stage attack sequences. Our results suggest the efficacy of DRL algorithms for proactive cyber defense under multi-stage attack profiles and system uncertainties.
AdverSAR: Adversarial Search and Rescue via Multi-Agent Reinforcement Learning
Dec 20, 2022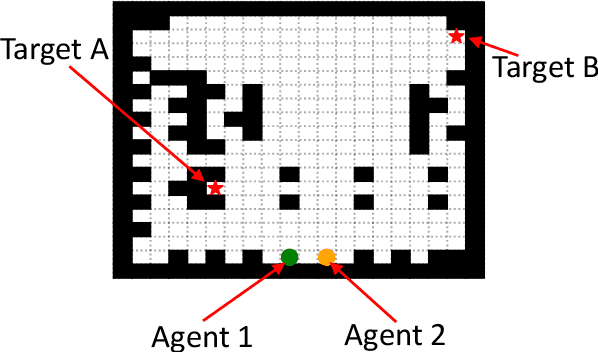
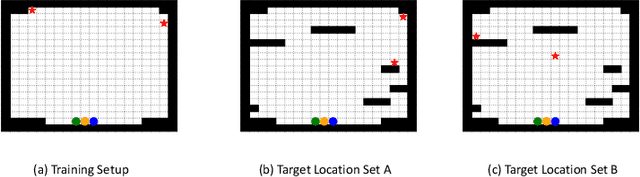
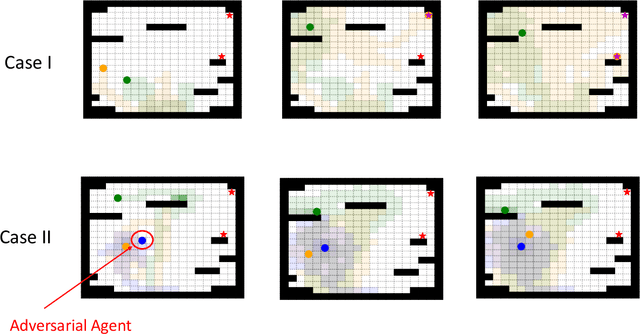
Search and Rescue (SAR) missions in remote environments often employ autonomous multi-robot systems that learn, plan, and execute a combination of local single-robot control actions, group primitives, and global mission-oriented coordination and collaboration. Often, SAR coordination strategies are manually designed by human experts who can remotely control the multi-robot system and enable semi-autonomous operations. However, in remote environments where connectivity is limited and human intervention is often not possible, decentralized collaboration strategies are needed for fully-autonomous operations. Nevertheless, decentralized coordination may be ineffective in adversarial environments due to sensor noise, actuation faults, or manipulation of inter-agent communication data. In this paper, we propose an algorithmic approach based on adversarial multi-agent reinforcement learning (MARL) that allows robots to efficiently coordinate their strategies in the presence of adversarial inter-agent communications. In our setup, the objective of the multi-robot team is to discover targets strategically in an obstacle-strewn geographical area by minimizing the average time needed to find the targets. It is assumed that the robots have no prior knowledge of the target locations, and they can interact with only a subset of neighboring robots at any time. Based on the centralized training with decentralized execution (CTDE) paradigm in MARL, we utilize a hierarchical meta-learning framework to learn dynamic team-coordination modalities and discover emergent team behavior under complex cooperative-competitive scenarios. The effectiveness of our approach is demonstrated on a collection of prototype grid-world environments with different specifications of benign and adversarial agents, target locations, and agent rewards.
Extending Conformal Prediction to Hidden Markov Models with Exact Validity via de Finetti's Theorem for Markov Chains
Oct 05, 2022



Conformal prediction is a widely used method to quantify uncertainty in settings where the data is independent and identically distributed (IID), or more generally, exchangeable. Conformal prediction takes in a pre-trained classifier, a calibration dataset and a confidence level as inputs, and returns a function which maps feature vectors to subsets of classes. The output of the returned function for a new feature vector (i.e., a test data point) is guaranteed to contain the true class with the pre-specified confidence. Despite its success and usefulness in IID settings, extending conformal prediction to non-exchangeable (e.g., Markovian) data in a manner that provably preserves all desirable theoretical properties has largely remained an open problem. As a solution, we extend conformal prediction to the setting of a Hidden Markov Model (HMM) with unknown parameters. The key idea behind the proposed method is to partition the non-exchangeable Markovian data from the HMM into exchangeable blocks by exploiting the de Finetti's Theorem for Markov Chains discovered by Diaconis and Freedman (1980). The permutations of the exchangeable blocks are then viewed as randomizations of the observed Markovian data from the HMM. The proposed method provably retains all desirable theoretical guarantees offered by the classical conformal prediction framework and is general enough to be useful in many sequential prediction problems.
Ad Hoc Teamwork in the Presence of Adversaries
Aug 09, 2022Advances in ad hoc teamwork have the potential to create agents that collaborate robustly in real-world applications. Agents deployed in the real world, however, are vulnerable to adversaries with the intent to subvert them. There has been little research in ad hoc teamwork that assumes the presence of adversaries. We explain the importance of extending ad hoc teamwork to include the presence of adversaries and clarify why this problem is difficult. We then propose some directions for new research opportunities in ad hoc teamwork that leads to more robust multi-agent cyber-physical infrastructure systems.
Lorenz System State Stability Identification using Neural Networks
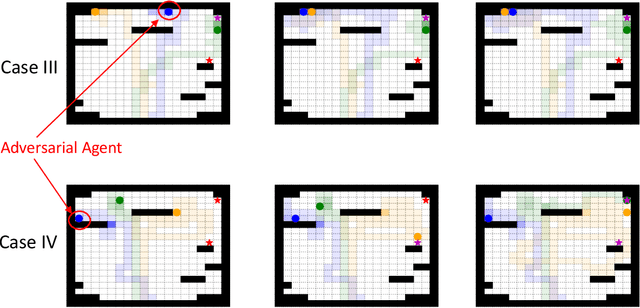
Jun 16, 2021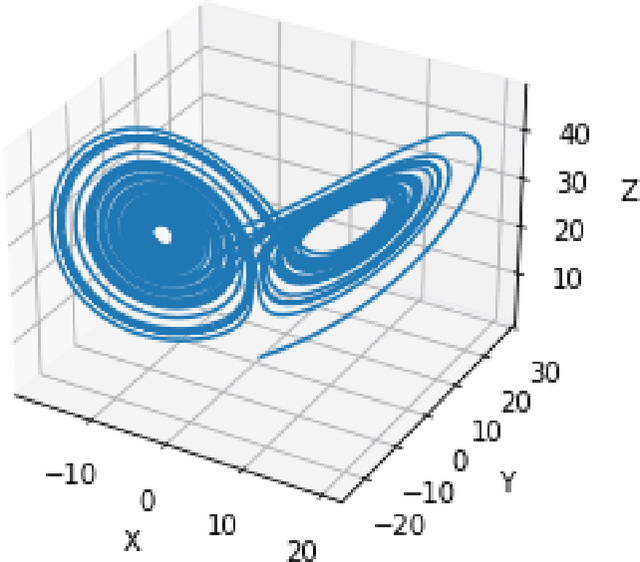
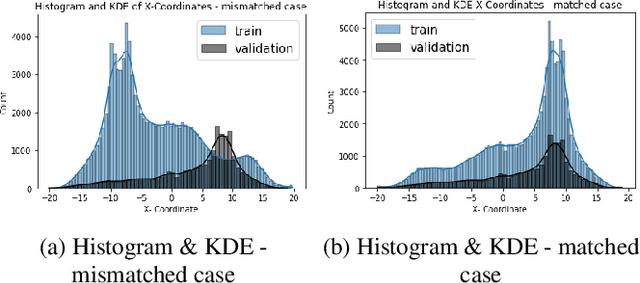
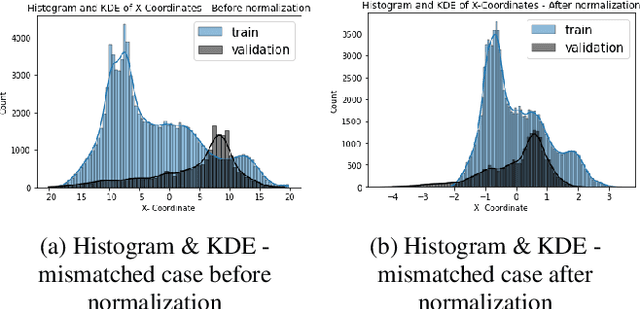
Nonlinear dynamical systems such as Lorenz63 equations are known to be chaotic in nature and sensitive to initial conditions. As a result, a small perturbation in the initial conditions results in deviation in state trajectory after a few time steps. The algorithms and computational resources needed to accurately identify the system states vary depending on whether the solution is in transition region or not. We refer to the transition and non-transition regions as unstable and stable regions respectively. We label a system state to be stable if it's immediate past and future states reside in the same regime. However, at a given time step we don't have the prior knowledge about whether system is in stable or unstable region. In this paper, we develop and train a feed forward (multi-layer perceptron) Neural Network to classify the system states of a Lorenz system as stable and unstable. We pose this task as a supervised learning problem where we train the neural network on Lorenz system which have states labeled as stable or unstable. We then test the ability of the neural network models to identify the stable and unstable states on a different Lorenz system that is generated using different initial conditions. We also evaluate the classification performance in the mismatched case i.e., when the initial conditions for training and validation data are sampled from different intervals. We show that certain normalization schemes can greatly improve the performance of neural networks in especially these mismatched scenarios. The classification framework developed in the paper can be a preprocessor for a larger context of sequential decision making framework where the decision making is performed based on observed stable or unstable states.
Constraints Satisfiability Driven Reinforcement Learning for Autonomous Cyber Defense
Apr 19, 2021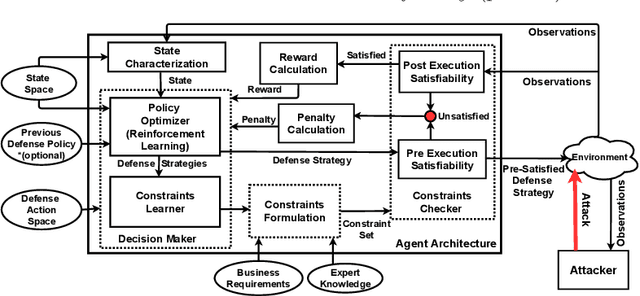
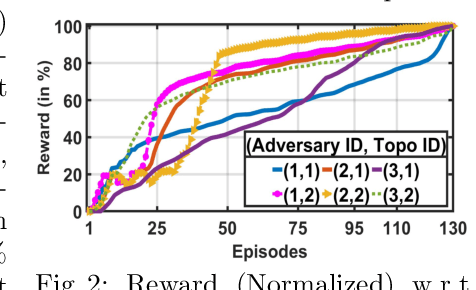
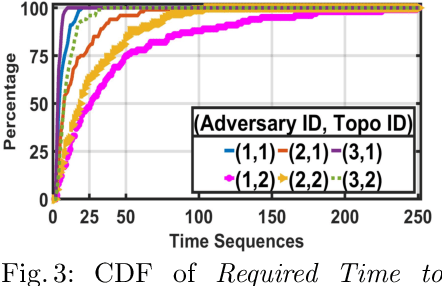
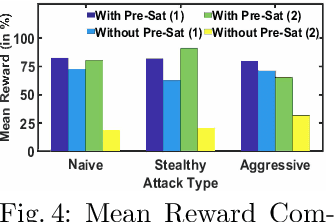
With the increasing system complexity and attack sophistication, the necessity of autonomous cyber defense becomes vivid for cyber and cyber-physical systems (CPSs). Many existing frameworks in the current state-of-the-art either rely on static models with unrealistic assumptions, or fail to satisfy the system safety and security requirements. In this paper, we present a new hybrid autonomous agent architecture that aims to optimize and verify defense policies of reinforcement learning (RL) by incorporating constraints verification (using satisfiability modulo theory (SMT)) into the agent's decision loop. The incorporation of SMT does not only ensure the satisfiability of safety and security requirements, but also provides constant feedback to steer the RL decision-making toward safe and effective actions. This approach is critically needed for CPSs that exhibit high risk due to safety or security violations. Our evaluation of the presented approach in a simulated CPS environment shows that the agent learns the optimal policy fast and defeats diversified attack strategies in 99\% cases.