 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeCodeBench: A Renewable Benchmark for Perception-to-Program Reconstruction of Synthetic Shape Scenes
May 12, 2026We introduce ShapeCodeBench, a synthetic benchmark for perception-to-program reconstruction: given a rendered raster image, a model must emit an executable drawing program that a deterministic evaluator re-renders and compares with the target. The v1 DSL has four primitives on a 512 x 512 black-on-white canvas, but every instance is generated from a seeded RNG, so fresh held-out sets can be created to reduce exact-instance contamination. We release a frozen eval_v1 split with 150 samples across easy, medium, and hard tiers, scored by exact match, pixel accuracy, foreground IoU, parse success, and execution success. We evaluate an empty-program floor, a classical computer-vision heuristic, Claude Opus 4.7 at high and max effort, and GPT-5.5 at medium and extra_high reasoning effort. The heuristic is competitive on easy scenes but collapses when overlaps fuse components; the strongest multimodal configuration preserves much of the foreground structure but still misses exact match because of small parameter errors. Best overall exact match remains low, so ShapeCodeBench is far from saturated. The benchmark code, frozen dataset, run artifacts, and paper sources are released to support independent replication and extension.
Flow Matching is Adaptive to Manifold Structures
Feb 25, 2026Flow matching has emerged as a simulation-free alternative to diffusion-based generative modeling, producing samples by solving an ODE whose time-dependent velocity field is learned along an interpolation between a simple source distribution (e.g., a standard normal) and a target data distribution. Flow-based methods often exhibit greater training stability and have achieved strong empirical performance in high-dimensional settings where data concentrate near a low-dimensional manifold, such as text-to-image synthesis, video generation, and molecular structure generation. Despite this success, existing theoretical analyses of flow matching assume target distributions with smooth, full-dimensional densities, leaving its effectiveness in manifold-supported settings largely unexplained. To this end, we theoretically analyze flow matching with linear interpolation when the target distribution is supported on a smooth manifold. We establish a non-asymptotic convergence guarantee for the learned velocity field, and then propagate this estimation error through the ODE to obtain statistical consistency of the implicit density estimator induced by the flow-matching objective. The resulting convergence rate is near minimax-optimal, depends only on the intrinsic dimension, and reflects the smoothness of both the manifold and the target distribution. Together, these results provide a principled explanation for how flow matching adapts to intrinsic data geometry and circumvents the curse of dimensionality.
An IoT-Based Controlled Environment Storage for Prevention of Spoilage of Onion (Allium Cepa) During Post-Harvest with UV-C Disinfection
Jan 11, 2026India is the second largest producer of onions in the world, contributing over 26 million tonnes annually. However, during storage, approximately 30-40% of onions are lost due to rotting, sprouting, and weight loss. Despite being a major producer, conventional storage methods are either low-cost but ineffective (traditional storage with 40% spoilage) or highly effective but prohibitively expensive for small farmers (cold storage). This paper presents a low-cost IoT-based smart onion storage system that monitors and automatically regulates environmental parameters including temperature, humidity, and spoilage gases using ESP32 microcontroller, DHT22 sensor, MQ-135 gas sensor, and UV-C disinfection technology. The proposed system aims to reduce onion spoilage to 15-20% from the current 40-45% wastage rate while remaining affordable for small and marginal farmers who constitute the majority in India. The system is designed to be cost-effective (estimated 60k-70k INR), energy-efficient, farmer-friendly, and solar-powered.
Underactuated Biomimetic Autonomous Underwater Vehicle for Ecosystem Monitoring
Nov 09, 2025In this paper, we present an underactuated biomimetic underwater robot that is suitable for ecosystem monitoring in both marine and freshwater environments. We present an updated mechanical design for a fish-like robot and propose minimal actuation behaviors learned using reinforcement learning techniques. We present our preliminary mechanical design of the tail oscillation mechanism and illustrate the swimming behaviors on FishGym simulator, where the reinforcement learning techniques will be tested on
A Likelihood Based Approach to Distribution Regression Using Conditional Deep Generative Models
Oct 02, 2024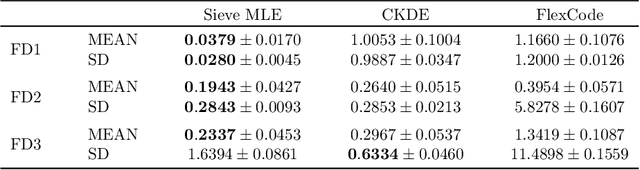
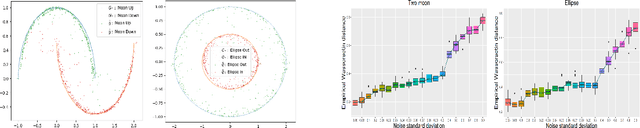

In this work, we explore the theoretical properties of conditional deep generative models under the statistical framework of distribution regression where the response variable lies in a high-dimensional ambient space but concentrates around a potentially lower-dimensional manifold. More specifically, we study the large-sample properties of a likelihood-based approach for estimating these models. Our results lead to the convergence rate of a sieve maximum likelihood estimator (MLE) for estimating the conditional distribution (and its devolved counterpart) of the response given predictors in the Hellinger (Wasserstein) metric. Our rates depend solely on the intrinsic dimension and smoothness of the true conditional distribution. These findings provide an explanation of why conditional deep generative models can circumvent the curse of dimensionality from the perspective of statistical foundations and demonstrate that they can learn a broader class of nearly singular conditional distributions. Our analysis also emphasizes the importance of introducing a small noise perturbation to the data when they are supported sufficiently close to a manifold. Finally, in our numerical studies, we demonstrate the effective implementation of the proposed approach using both synthetic and real-world datasets, which also provide complementary validation to our theoretical findings.
HistoSPACE: Histology-Inspired Spatial Transcriptome Prediction And Characterization Engine
Aug 07, 2024



Spatial transcriptomics (ST) enables the visualization of gene expression within the context of tissue morphology. This emerging discipline has the potential to serve as a foundation for developing tools to design precision medicines. However, due to the higher costs and expertise required for such experiments, its translation into a regular clinical practice might be challenging. Despite the implementation of modern deep learning to enhance information obtained from histological images using AI, efforts have been constrained by limitations in the diversity of information. In this paper, we developed a model, HistoSPACE that explore the diversity of histological images available with ST data to extract molecular insights from tissue image. Our proposed study built an image encoder derived from universal image autoencoder. This image encoder was connected to convolution blocks to built the final model. It was further fine tuned with the help of ST-Data. This model is notably lightweight in compared to traditional histological models. Our developed model demonstrates significant efficiency compared to contemporary algorithms, revealing a correlation of 0.56 in leave-one-out cross-validation. Finally, its robustness was validated through an independent dataset, showing a well matched preditction with predefined disease pathology.
Unmasking unlearnable models: a classification challenge for biomedical images without visible cues
Jul 29, 2024
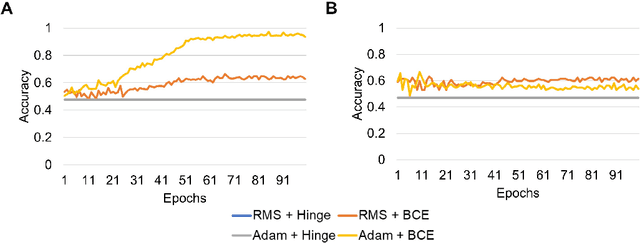
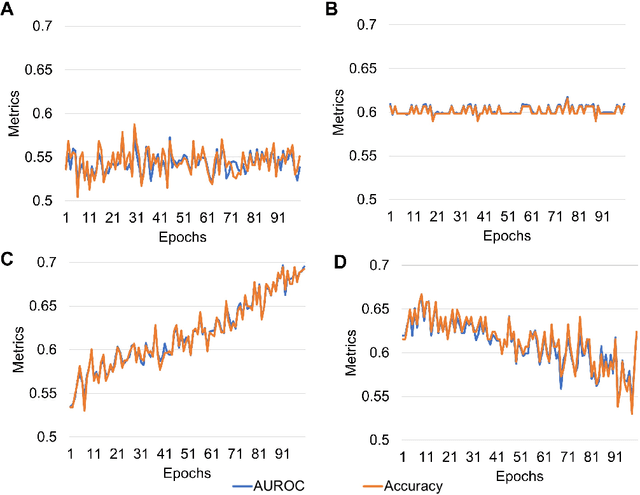
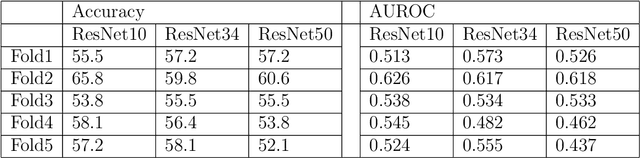
Predicting traits from images lacking visual cues is challenging, as algorithms are designed to capture visually correlated ground truth. This problem is critical in biomedical sciences, and their solution can improve the efficacy of non-invasive methods. For example, a recent challenge of predicting MGMT methylation status from MRI images is critical for treatment decisions of glioma patients. Using less robust models poses a significant risk in these critical scenarios and underscores the urgency of addressing this issue. Despite numerous efforts, contemporary models exhibit suboptimal performance, and underlying reasons for this limitation remain elusive. In this study, we demystify the complexity of MGMT status prediction through a comprehensive exploration by performing benchmarks of existing models adjoining transfer learning. Their architectures were further dissected by observing gradient flow across layers. Additionally, a feature selection strategy was applied to improve model interpretability. Our finding highlighted that current models are unlearnable and may require new architectures to explore applications in the real world. We believe our study will draw immediate attention and catalyse advancements in predictive modelling with non-visible cues.
A Globally Convergent Gradient-based Bilevel Hyperparameter Optimization Method
Aug 25, 2022
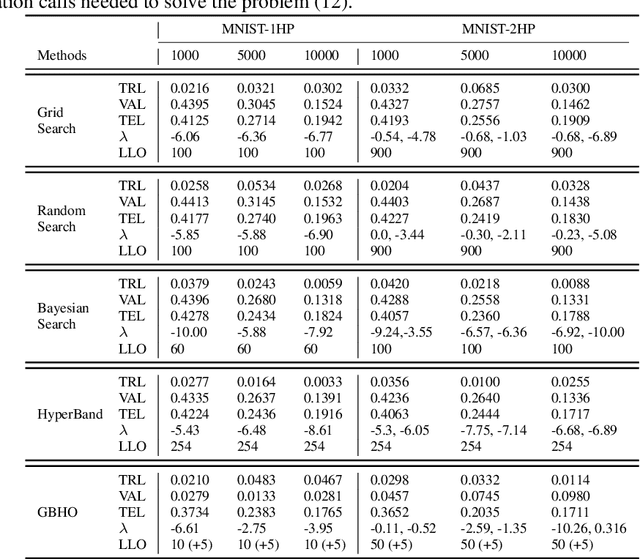

Hyperparameter optimization in machine learning is often achieved using naive techniques that only lead to an approximate set of hyperparameters. Although techniques such as Bayesian optimization perform an intelligent search on a given domain of hyperparameters, it does not guarantee an optimal solution. A major drawback of most of these approaches is an exponential increase of their search domain with number of hyperparameters, increasing the computational cost and making the approaches slow. The hyperparameter optimization problem is inherently a bilevel optimization task, and some studies have attempted bilevel solution methodologies for solving this problem. However, these studies assume a unique set of model weights that minimize the training loss, which is generally violated by deep learning architectures. This paper discusses a gradient-based bilevel method addressing these drawbacks for solving the hyperparameter optimization problem. The proposed method can handle continuous hyperparameters for which we have chosen the regularization hyperparameter in our experiments. The method guarantees convergence to the set of optimal hyperparameters that this study has theoretically proven. The idea is based on approximating the lower-level optimal value function using Gaussian process regression. As a result, the bilevel problem is reduced to a single level constrained optimization task that is solved using the augmented Lagrangian method. We have performed an extensive computational study on the MNIST and CIFAR-10 datasets on multi-layer perceptron and LeNet architectures that confirms the efficiency of the proposed method. A comparative study against grid search, random search, Bayesian optimization, and HyberBand method on various hyperparameter problems shows that the proposed algorithm converges with lower computation and leads to models that generalize better on the testing set.