 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Distribution Shift on Reinforcement Learning Performance
Paper and Code

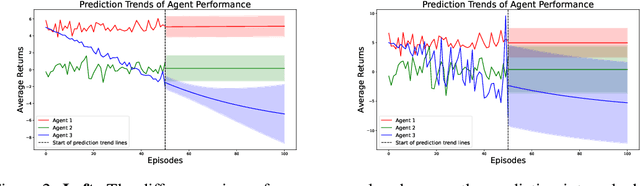
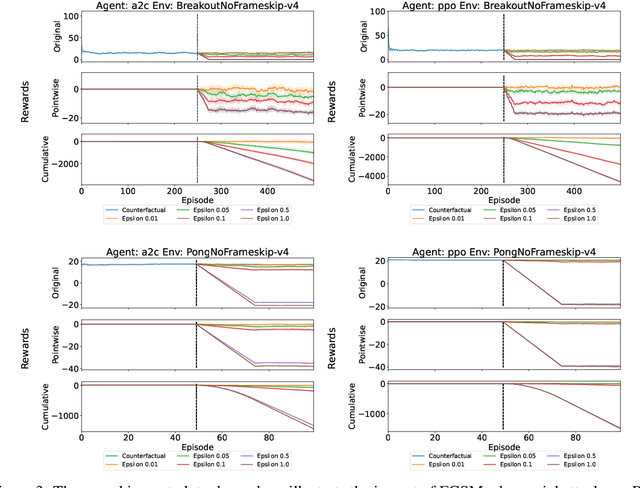
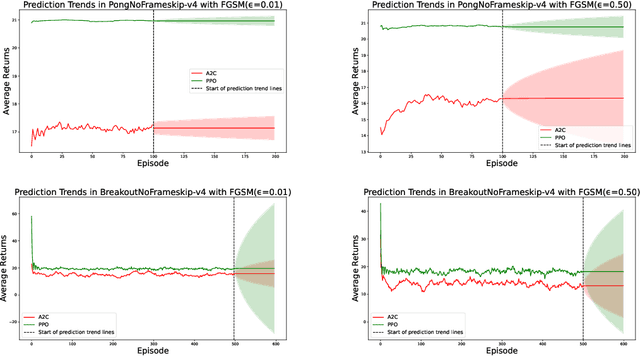
Research in machine learning is making progress in fixing its own reproducibility crisis. Reinforcement learning (RL), in particular, faces its own set of unique challenges. Comparison of point estimates, and plots that show successful convergence to the optimal policy during training, may obfuscate overfitting or dependence on the experimental setup. Although researchers in RL have proposed reliability metrics that account for uncertainty to better understand each algorithm's strengths and weaknesses, the recommendations of past work do not assume the presence of out-of-distribution observations. We propose a set of evaluation methods that measure the robustness of RL algorithms under distribution shifts. The tools presented here argue for the need to account for performance over time while the agent is acting in its environment. In particular, we recommend time series analysis as a method of observational RL evaluation. We also show that the unique properties of RL and simulated dynamic environments allow us to make stronger assumptions to justify the measurement of causal impact in our evaluations. We then apply these tools to single-agent and multi-agent environments to show the impact of introducing distribution shifts during test time. We present this methodology as a first step toward rigorous RL evaluation in the presence of distribution shifts.