 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Distribution Shift on Reinforcement Learning Performance
Feb 05, 2024
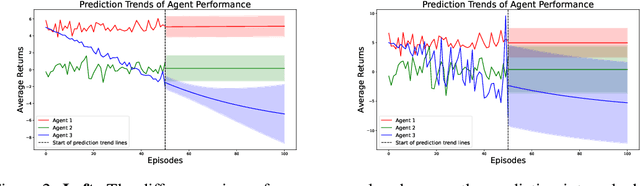
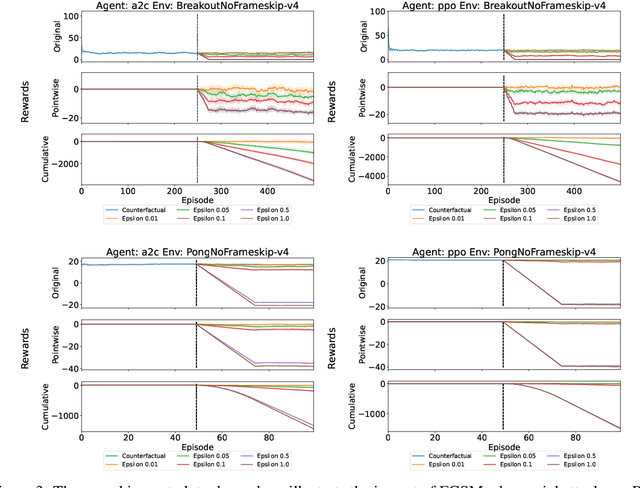
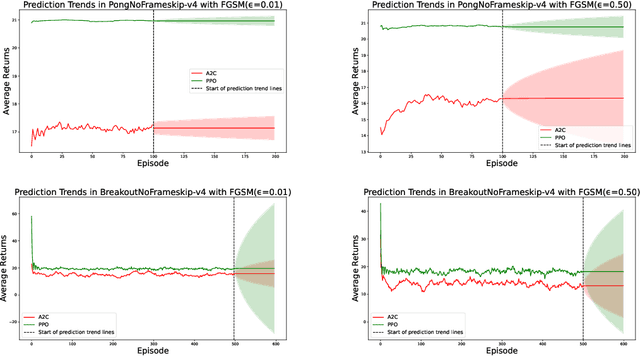
Research in machine learning is making progress in fixing its own reproducibility crisis. Reinforcement learning (RL), in particular, faces its own set of unique challenges. Comparison of point estimates, and plots that show successful convergence to the optimal policy during training, may obfuscate overfitting or dependence on the experimental setup. Although researchers in RL have proposed reliability metrics that account for uncertainty to better understand each algorithm's strengths and weaknesses, the recommendations of past work do not assume the presence of out-of-distribution observations. We propose a set of evaluation methods that measure the robustness of RL algorithms under distribution shifts. The tools presented here argue for the need to account for performance over time while the agent is acting in its environment. In particular, we recommend time series analysis as a method of observational RL evaluation. We also show that the unique properties of RL and simulated dynamic environments allow us to make stronger assumptions to justify the measurement of causal impact in our evaluations. We then apply these tools to single-agent and multi-agent environments to show the impact of introducing distribution shifts during test time. We present this methodology as a first step toward rigorous RL evaluation in the presence of distribution shifts.
AdverSAR: Adversarial Search and Rescue via Multi-Agent Reinforcement Learning
Dec 20, 2022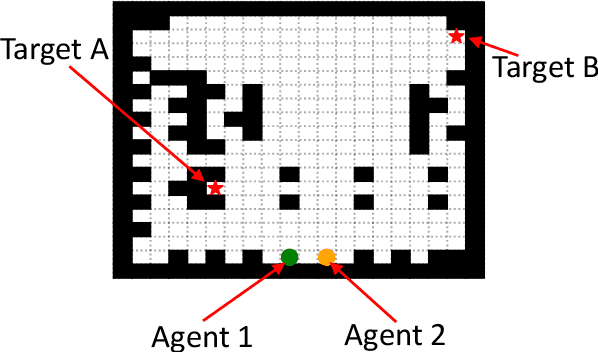
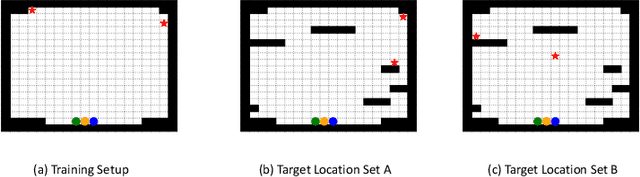
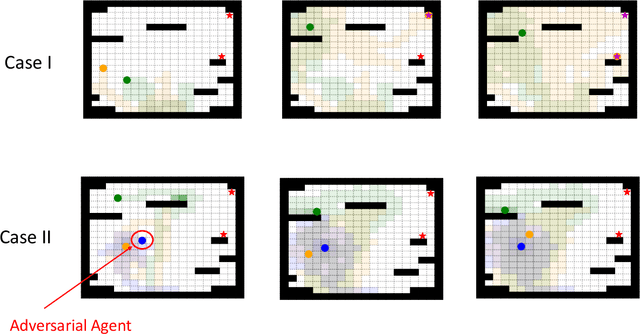
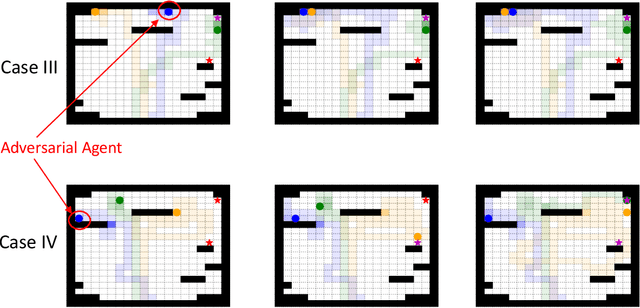
Search and Rescue (SAR) missions in remote environments often employ autonomous multi-robot systems that learn, plan, and execute a combination of local single-robot control actions, group primitives, and global mission-oriented coordination and collaboration. Often, SAR coordination strategies are manually designed by human experts who can remotely control the multi-robot system and enable semi-autonomous operations. However, in remote environments where connectivity is limited and human intervention is often not possible, decentralized collaboration strategies are needed for fully-autonomous operations. Nevertheless, decentralized coordination may be ineffective in adversarial environments due to sensor noise, actuation faults, or manipulation of inter-agent communication data. In this paper, we propose an algorithmic approach based on adversarial multi-agent reinforcement learning (MARL) that allows robots to efficiently coordinate their strategies in the presence of adversarial inter-agent communications. In our setup, the objective of the multi-robot team is to discover targets strategically in an obstacle-strewn geographical area by minimizing the average time needed to find the targets. It is assumed that the robots have no prior knowledge of the target locations, and they can interact with only a subset of neighboring robots at any time. Based on the centralized training with decentralized execution (CTDE) paradigm in MARL, we utilize a hierarchical meta-learning framework to learn dynamic team-coordination modalities and discover emergent team behavior under complex cooperative-competitive scenarios. The effectiveness of our approach is demonstrated on a collection of prototype grid-world environments with different specifications of benign and adversarial agents, target locations, and agent rewards.
Ad Hoc Teamwork in the Presence of Adversaries
Aug 09, 2022Advances in ad hoc teamwork have the potential to create agents that collaborate robustly in real-world applications. Agents deployed in the real world, however, are vulnerable to adversaries with the intent to subvert them. There has been little research in ad hoc teamwork that assumes the presence of adversaries. We explain the importance of extending ad hoc teamwork to include the presence of adversaries and clarify why this problem is difficult. We then propose some directions for new research opportunities in ad hoc teamwork that leads to more robust multi-agent cyber-physical infrastructure systems.
Adversarial Attacks in Cooperative AI
Dec 06, 2021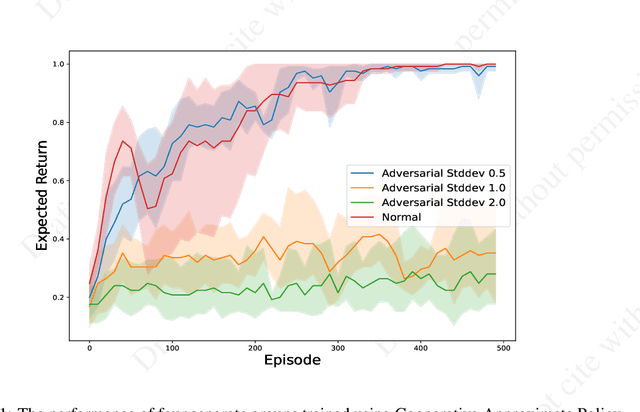
Single-agent reinforcement learning algorithms in a multi-agent environment are inadequate for fostering cooperation. If intelligent agents are to interact and work together to solve complex problems, methods that counter non-cooperative behavior are needed to facilitate the training of multiple agents. This is the goal of cooperative AI. Recent work in adversarial machine learning, however, shows that models (e.g., image classifiers) can be easily deceived into making incorrect decisions. In addition, some past research in cooperative AI has relied on new notions of representations, like public beliefs, to accelerate the learning of optimally cooperative behavior. Hence, cooperative AI might introduce new weaknesses not investigated in previous machine learning research. In this paper, our contributions include: (1) arguing that three algorithms inspired by human-like social intelligence introduce new vulnerabilities, unique to cooperative AI, that adversaries can exploit, and (2) an experiment showing that simple, adversarial perturbations on the agents' beliefs can negatively impact performance. This evidence points to the possibility that formal representations of social behavior are vulnerable to adversarial attacks.
Reward-Free Attacks in Multi-Agent Reinforcement Learning
Dec 02, 2021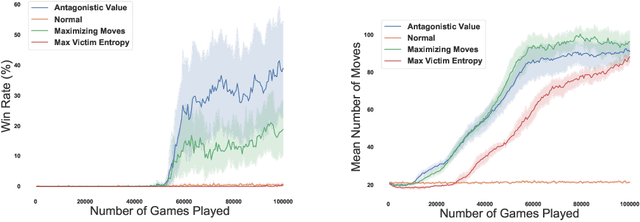

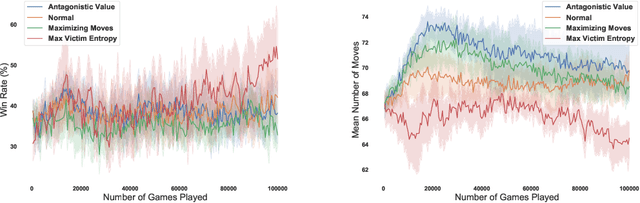

We investigate how effective an attacker can be when it only learns from its victim's actions, without access to the victim's reward. In this work, we are motivated by the scenario where the attacker wants to behave strategically when the victim's motivations are unknown. We argue that one heuristic approach an attacker can use is to maximize the entropy of the victim's policy. The policy is generally not obfuscated, which implies it may be extracted simply by passively observing the victim. We provide such a strategy in the form of a reward-free exploration algorithm that maximizes the attacker's entropy during the exploration phase, and then maximizes the victim's empirical entropy during the planning phase. In our experiments, the victim agents are subverted through policy entropy maximization, implying an attacker might not need access to the victim's reward to succeed. Hence, reward-free attacks, which are based only on observing behavior, show the feasibility of an attacker to act strategically without knowledge of the victim's motives even if the victim's reward information is protected.
How Can Creativity Occur in Multi-Agent Systems?
Nov 29, 2021Complex systems show how surprising and beautiful phenomena can emerge from structures or agents following simple rules. With the recent success of deep reinforcement learning (RL), a natural path forward would be to use the capabilities of multiple deep RL agents to produce emergent behavior of greater benefit and sophistication. In general, this has proved to be an unreliable strategy without significant computation due to the difficulties inherent in multi-agent RL training. In this paper, we propose some criteria for creativity in multi-agent RL. We hope this proposal will give artists applying multi-agent RL a starting point, and provide a catalyst for further investigation guided by philosophical discussion.