 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Power Series Representations in Probability and Expected Utility Theory
Aug 01, 2025We advance a general theory of coherent preference that surrenders restrictions embodied in orthodox doctrine. This theory enjoys the property that any preference system admits extension to a complete system of preferences, provided it satisfies a certain coherence requirement analogous to the one de Finetti advanced for his foundations of probability. Unlike de Finetti's theory, the one we set forth requires neither transitivity nor Archimedeanness nor boundedness nor continuity of preference. This theory also enjoys the property that any complete preference system meeting the standard of coherence can be represented by utility in an ordered field extension of the reals. Representability by utility is a corollary of this paper's central result, which at once extends H\"older's Theorem and strengthens Hahn's Embedding Theorem.
Strengthening Consistency Results in Modal Logic
Jul 11, 2023A fundamental question asked in modal logic is whether a given theory is consistent. But consistent with what? A typical way to address this question identifies a choice of background knowledge axioms (say, S4, D, etc.) and then shows the assumptions codified by the theory in question to be consistent with those background axioms. But determining the specific choice and division of background axioms is, at least sometimes, little more than tradition. This paper introduces **generic theories** for propositional modal logic to address consistency results in a more robust way. As building blocks for background knowledge, generic theories provide a standard for categorical determinations of consistency. We argue that the results and methods of this paper help to elucidate problems in epistemology and enjoy sufficient scope and power to have purchase on problems bearing on modalities in judgement, inference, and decision making.
* In Proceedings TARK 2023, arXiv:2307.04005. The authors thank three anonymous reviewers as well as Rineke Verbrugge for valuable comments and suggestions to help improve this manuscript. The authors also extend their gratitude to Alessandro Aldini, Michael Grossberg, Ali Kahn, Rohit Parikh, and Max Stinchcombe, for their generous feedback on prior drafts of this manuscript
Representation and Invariance in Reinforcement Learning
Dec 14, 2021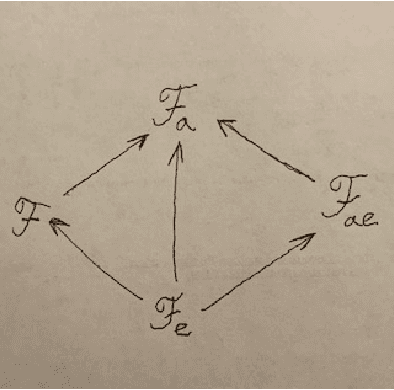
If we changed the rules, would the wise trade places with the fools? Different groups formalize reinforcement learning (RL) in different ways. If an agent in one RL formalization is to run within another RL formalization's environment, the agent must first be converted, or mapped. A criterion of adequacy for any such mapping is that it preserves relative intelligence. This paper investigates the formulation and properties of this criterion of adequacy. However, prior to the problem of formulation is, we argue, the problem of comparative intelligence. We compare intelligence using ultrafilters, motivated by viewing agents as candidates in intelligence elections where voters are environments. These comparators are counterintuitive, but we prove an impossibility theorem about RL intelligence measurement, suggesting such counterintuitions are unavoidable. Given a mapping between RL frameworks, we establish sufficient conditions to ensure that, for any ultrafilter-based intelligence comparator in the destination framework, there exists an ultrafilter-based intelligence comparator in the source framework such that the mapping preserves relative intelligence. We consider three concrete mappings between various RL frameworks and show that they satisfy these sufficient conditions and therefore preserve suitably-measured relative intelligence.
Adversarial Attacks in Cooperative AI
Dec 06, 2021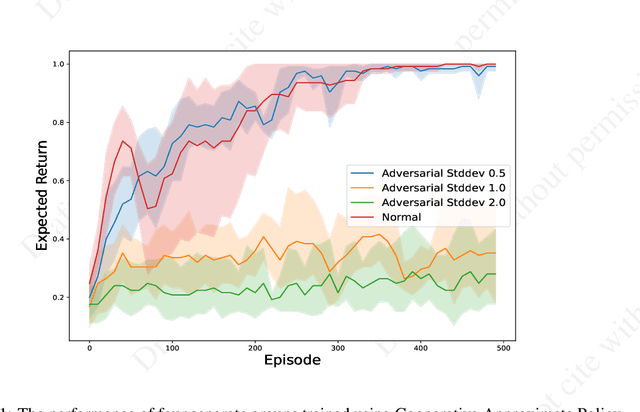
Single-agent reinforcement learning algorithms in a multi-agent environment are inadequate for fostering cooperation. If intelligent agents are to interact and work together to solve complex problems, methods that counter non-cooperative behavior are needed to facilitate the training of multiple agents. This is the goal of cooperative AI. Recent work in adversarial machine learning, however, shows that models (e.g., image classifiers) can be easily deceived into making incorrect decisions. In addition, some past research in cooperative AI has relied on new notions of representations, like public beliefs, to accelerate the learning of optimally cooperative behavior. Hence, cooperative AI might introduce new weaknesses not investigated in previous machine learning research. In this paper, our contributions include: (1) arguing that three algorithms inspired by human-like social intelligence introduce new vulnerabilities, unique to cooperative AI, that adversaries can exploit, and (2) an experiment showing that simple, adversarial perturbations on the agents' beliefs can negatively impact performance. This evidence points to the possibility that formal representations of social behavior are vulnerable to adversarial attacks.
When is an Example a Counterexample?
Oct 23, 2013In this extended abstract, we carefully examine a purported counterexample to a postulate of iterated belief revision. We suggest that the example is better seen as a failure to apply the theory of belief revision in sufficient detail. The main contribution is conceptual aiming at the literature on the philosophical foundations of the AGM theory of belief revision [1]. Our discussion is centered around the observation that it is often unclear whether a specific example is a "genuine" counterexample to an abstract theory or a misapplication of that theory to a concrete case.