 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks in Cooperative AI
Paper and Code
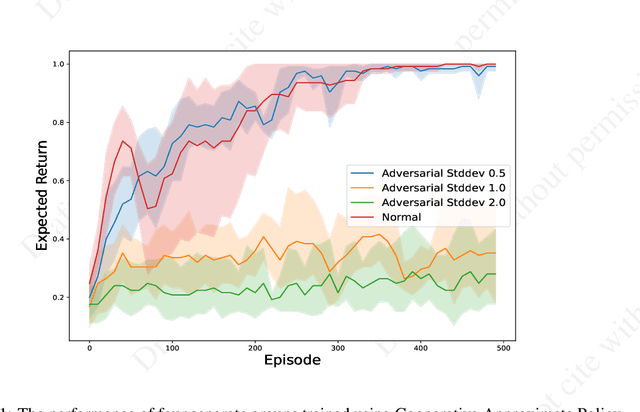
Single-agent reinforcement learning algorithms in a multi-agent environment are inadequate for fostering cooperation. If intelligent agents are to interact and work together to solve complex problems, methods that counter non-cooperative behavior are needed to facilitate the training of multiple agents. This is the goal of cooperative AI. Recent work in adversarial machine learning, however, shows that models (e.g., image classifiers) can be easily deceived into making incorrect decisions. In addition, some past research in cooperative AI has relied on new notions of representations, like public beliefs, to accelerate the learning of optimally cooperative behavior. Hence, cooperative AI might introduce new weaknesses not investigated in previous machine learning research. In this paper, our contributions include: (1) arguing that three algorithms inspired by human-like social intelligence introduce new vulnerabilities, unique to cooperative AI, that adversaries can exploit, and (2) an experiment showing that simple, adversarial perturbations on the agents' beliefs can negatively impact performance. This evidence points to the possibility that formal representations of social behavior are vulnerable to adversarial attacks.