 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Choice for AI Alignment: Dealing with Diverse Human Feedback
Apr 16, 2024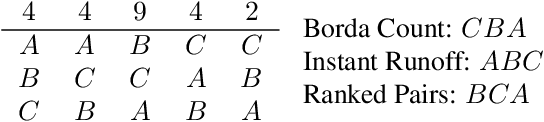
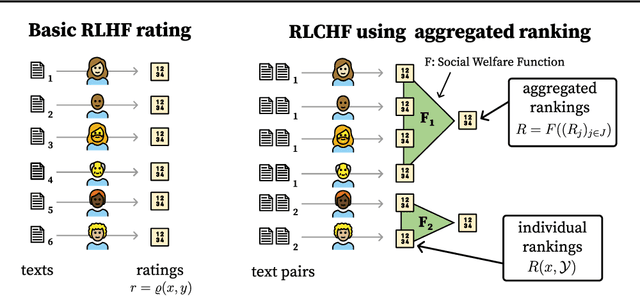
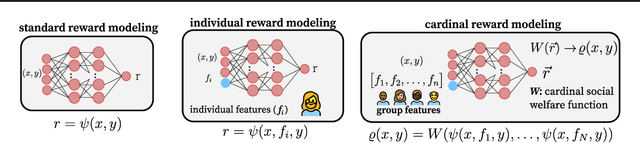
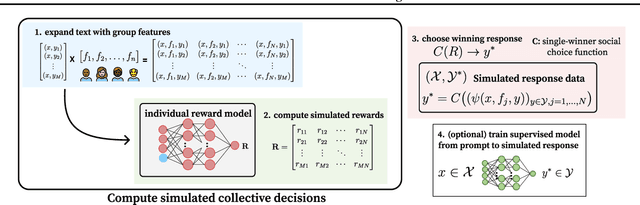
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Learning to Manipulate under Limited Information
Jan 29, 2024


By classic results in social choice theory, any reasonable preferential voting method sometimes gives individuals an incentive to report an insincere preference. The extent to which different voting methods are more or less resistant to such strategic manipulation has become a key consideration for comparing voting methods. Here we measure resistance to manipulation by whether neural networks of varying sizes can learn to profitably manipulate a given voting method in expectation, given different types of limited information about how other voters will vote. We trained nearly 40,000 neural networks of 26 sizes to manipulate against 8 different voting methods, under 6 types of limited information, in committee-sized elections with 5-21 voters and 3-6 candidates. We find that some voting methods, such as Borda, are highly manipulable by networks with limited information, while others, such as Instant Runoff, are not, despite being quite profitably manipulated by an ideal manipulator with full information.
Intention as Commitment toward Time
Apr 17, 2020
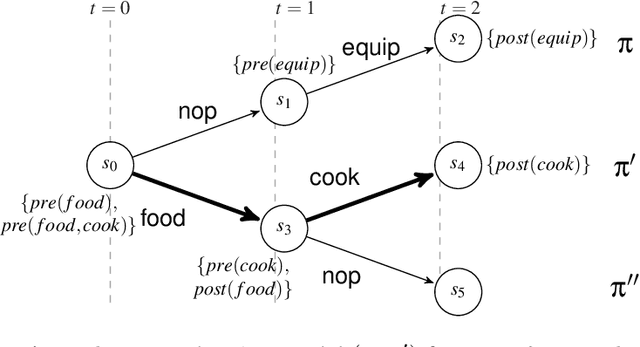

In this paper we address the interplay among intention, time, and belief in dynamic environments. The first contribution is a logic for reasoning about intention, time and belief, in which assumptions of intentions are represented by preconditions of intended actions. Intentions and beliefs are coherent as long as these assumptions are not violated, i.e. as long as intended actions can be performed such that their preconditions hold as well. The second contribution is the formalization of what-if scenarios: what happens with intentions and beliefs if a new (possibly conflicting) intention is adopted, or a new fact is learned? An agent is committed to its intended actions as long as its belief-intention database is coherent. We conceptualize intention as commitment toward time and we develop AGM-based postulates for the iterated revision of belief-intention databases, and we prove a Katsuno-Mendelzon-style representation theorem.
* 83 pages, 4 figures, Artificial Intelligence journal pre-print
When is an Example a Counterexample?
Oct 23, 2013In this extended abstract, we carefully examine a purported counterexample to a postulate of iterated belief revision. We suggest that the example is better seen as a failure to apply the theory of belief revision in sufficient detail. The main contribution is conceptual aiming at the literature on the philosophical foundations of the AGM theory of belief revision [1]. Our discussion is centered around the observation that it is often unclear whether a specific example is a "genuine" counterexample to an abstract theory or a misapplication of that theory to a concrete case.
Evidence and plausibility in neighborhood structures
Jul 04, 2013The intuitive notion of evidence has both semantic and syntactic features. In this paper, we develop an {\em evidence logic} for epistemic agents faced with possibly contradictory evidence from different sources. The logic is based on a neighborhood semantics, where a neighborhood $N$ indicates that the agent has reason to believe that the true state of the world lies in $N$. Further notions of relative plausibility between worlds and beliefs based on the latter ordering are then defined in terms of this evidence structure, yielding our intended models for evidence-based beliefs. In addition, we also consider a second more general flavor, where belief and plausibility are modeled using additional primitive relations, and we prove a representation theorem showing that each such general model is a $p$-morphic image of an intended one. This semantics invites a number of natural special cases, depending on how uniform we make the evidence sets, and how coherent their total structure. We give a structural study of the resulting `uniform' and `flat' models. Our main result are sound and complete axiomatizations for the logics of all four major model classes with respect to the modal language of evidence, belief and safe belief. We conclude with an outlook toward logics for the dynamics of changing evidence, and the resulting language extensions and connections with logics of plausibility change.