 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022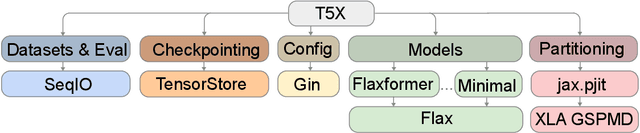
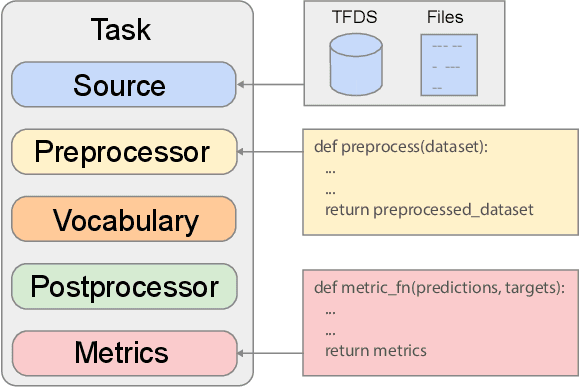
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Compositional Generalization in Semantic Parsing: Pre-training vs. Specialized Architectures
Jul 21, 2020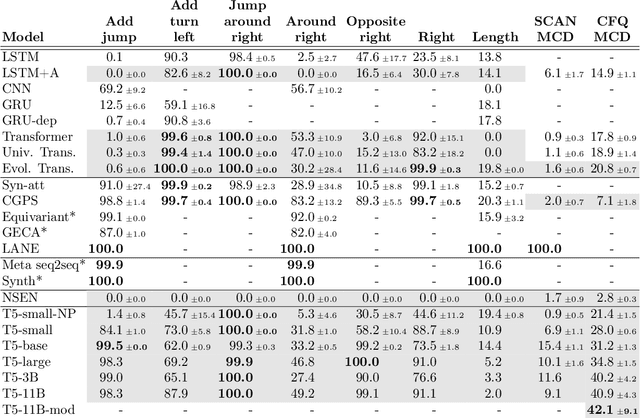

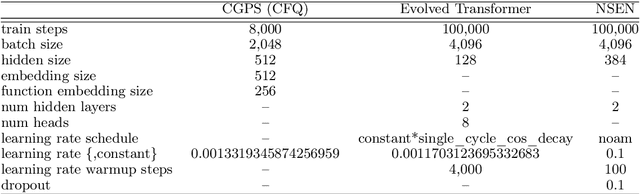
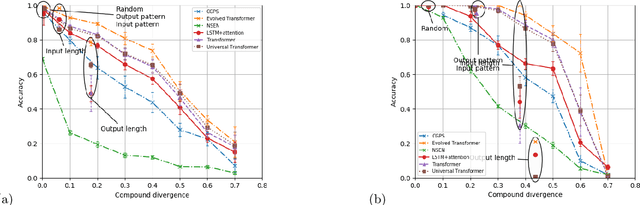
While mainstream machine learning methods are known to have limited ability to compositionally generalize, new architectures and techniques continue to be proposed to address this limitation. We investigate state-of-the-art techniques and architectures in order to assess their effectiveness in improving compositional generalization in semantic parsing tasks based on the SCAN and CFQ datasets. We show that masked language model (MLM) pre-training rivals SCAN-inspired architectures on primitive holdout splits. On a more complex compositional task, we show that pre-training leads to significant improvements in performance vs. comparable non-pre-trained models, whereas architectures proposed to encourage compositional generalization on SCAN or in the area of algorithm learning fail to lead to significant improvements. We establish a new state of the art on the CFQ compositional generalization benchmark using MLM pre-training together with an intermediate representation.
Intention as Commitment toward Time
Apr 17, 2020
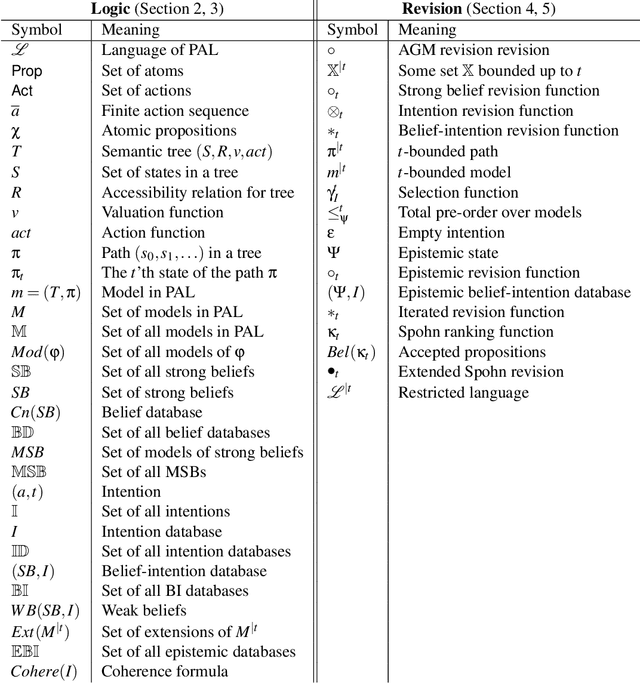
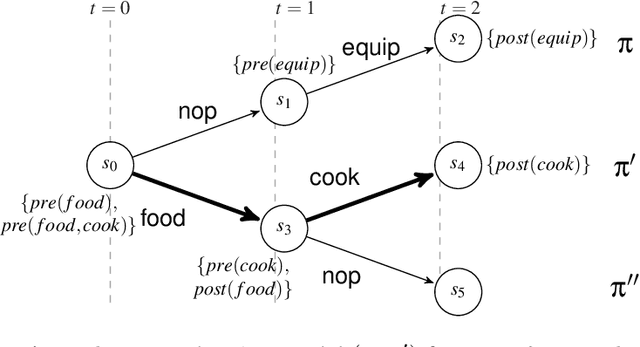

In this paper we address the interplay among intention, time, and belief in dynamic environments. The first contribution is a logic for reasoning about intention, time and belief, in which assumptions of intentions are represented by preconditions of intended actions. Intentions and beliefs are coherent as long as these assumptions are not violated, i.e. as long as intended actions can be performed such that their preconditions hold as well. The second contribution is the formalization of what-if scenarios: what happens with intentions and beliefs if a new (possibly conflicting) intention is adopted, or a new fact is learned? An agent is committed to its intended actions as long as its belief-intention database is coherent. We conceptualize intention as commitment toward time and we develop AGM-based postulates for the iterated revision of belief-intention databases, and we prove a Katsuno-Mendelzon-style representation theorem.
* 83 pages, 4 figures, Artificial Intelligence journal pre-print
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Dec 20, 2019

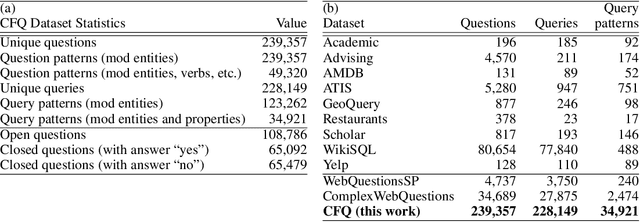
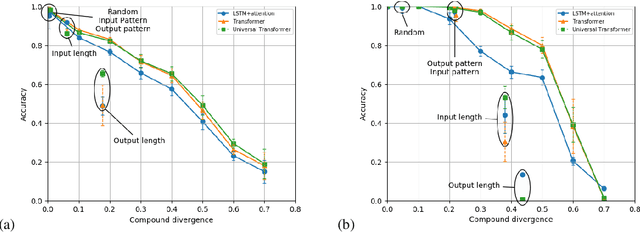
State-of-the-art machine learning methods exhibit limited compositional generalization. At the same time, there is a lack of realistic benchmarks that comprehensively measure this ability, which makes it challenging to find and evaluate improvements. We introduce a novel method to systematically construct such benchmarks by maximizing compound divergence while guaranteeing a small atom divergence between train and test sets, and we quantitatively compare this method to other approaches for creating compositional generalization benchmarks. We present a large and realistic natural language question answering dataset that is constructed according to this method, and we use it to analyze the compositional generalization ability of three machine learning architectures. We find that they fail to generalize compositionally and that there is a surprisingly strong negative correlation between compound divergence and accuracy. We also demonstrate how our method can be used to create new compositionality benchmarks on top of the existing SCAN dataset, which confirms these findings.
AGM-Style Revision of Beliefs and Intentions from a Database Perspective
Apr 26, 2016
We introduce a logic for temporal beliefs and intentions based on Shoham's database perspective. We separate strong beliefs from weak beliefs. Strong beliefs are independent from intentions, while weak beliefs are obtained by adding intentions to strong beliefs and everything that follows from that. We formalize coherence conditions on strong beliefs and intentions. We provide AGM-style postulates for the revision of strong beliefs and intentions. We show in a representation theorem that a revision operator satisfying our postulates can be represented by a pre-order on interpretations of the beliefs, together with a selection function for the intentions.