 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization in Semantic Parsing: Pre-training vs. Specialized Architectures
Jul 21, 2020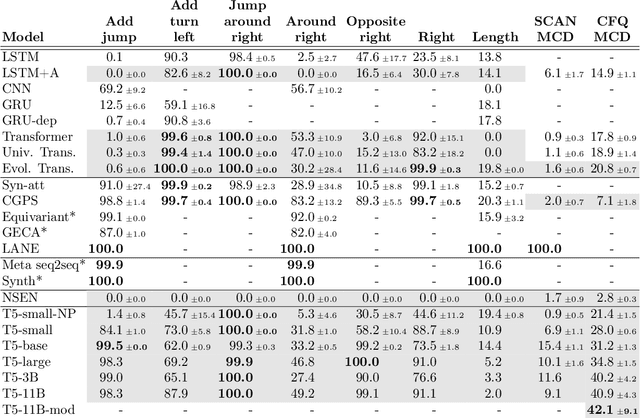

While mainstream machine learning methods are known to have limited ability to compositionally generalize, new architectures and techniques continue to be proposed to address this limitation. We investigate state-of-the-art techniques and architectures in order to assess their effectiveness in improving compositional generalization in semantic parsing tasks based on the SCAN and CFQ datasets. We show that masked language model (MLM) pre-training rivals SCAN-inspired architectures on primitive holdout splits. On a more complex compositional task, we show that pre-training leads to significant improvements in performance vs. comparable non-pre-trained models, whereas architectures proposed to encourage compositional generalization on SCAN or in the area of algorithm learning fail to lead to significant improvements. We establish a new state of the art on the CFQ compositional generalization benchmark using MLM pre-training together with an intermediate representation.
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Dec 20, 2019

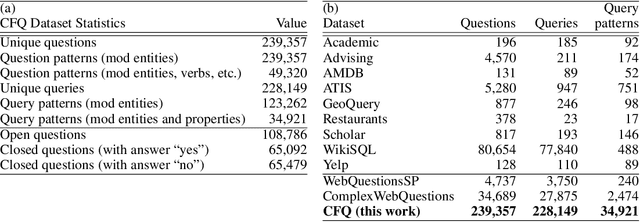
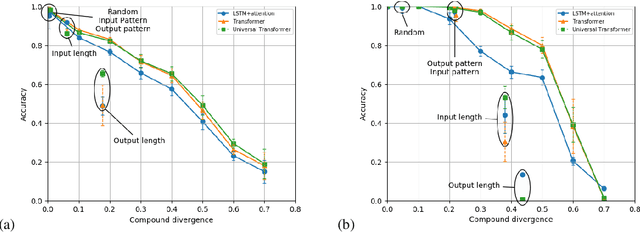
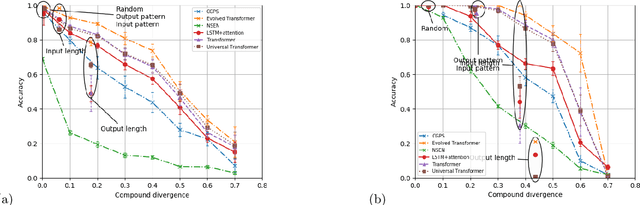
State-of-the-art machine learning methods exhibit limited compositional generalization. At the same time, there is a lack of realistic benchmarks that comprehensively measure this ability, which makes it challenging to find and evaluate improvements. We introduce a novel method to systematically construct such benchmarks by maximizing compound divergence while guaranteeing a small atom divergence between train and test sets, and we quantitatively compare this method to other approaches for creating compositional generalization benchmarks. We present a large and realistic natural language question answering dataset that is constructed according to this method, and we use it to analyze the compositional generalization ability of three machine learning architectures. We find that they fail to generalize compositionally and that there is a surprisingly strong negative correlation between compound divergence and accuracy. We also demonstrate how our method can be used to create new compositionality benchmarks on top of the existing SCAN dataset, which confirms these findings.