 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation and Invariance in Reinforcement Learning
Dec 14, 2021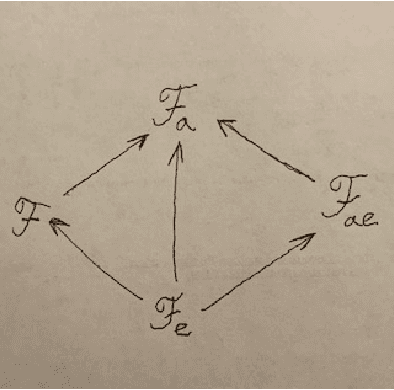
If we changed the rules, would the wise trade places with the fools? Different groups formalize reinforcement learning (RL) in different ways. If an agent in one RL formalization is to run within another RL formalization's environment, the agent must first be converted, or mapped. A criterion of adequacy for any such mapping is that it preserves relative intelligence. This paper investigates the formulation and properties of this criterion of adequacy. However, prior to the problem of formulation is, we argue, the problem of comparative intelligence. We compare intelligence using ultrafilters, motivated by viewing agents as candidates in intelligence elections where voters are environments. These comparators are counterintuitive, but we prove an impossibility theorem about RL intelligence measurement, suggesting such counterintuitions are unavoidable. Given a mapping between RL frameworks, we establish sufficient conditions to ensure that, for any ultrafilter-based intelligence comparator in the destination framework, there exists an ultrafilter-based intelligence comparator in the source framework such that the mapping preserves relative intelligence. We consider three concrete mappings between various RL frameworks and show that they satisfy these sufficient conditions and therefore preserve suitably-measured relative intelligence.
Measuring Intelligence and Growth Rate: Variations on Hibbard's Intelligence Measure
Jan 25, 2021In 2011, Hibbard suggested an intelligence measure for agents who compete in an adversarial sequence prediction game. We argue that Hibbard's idea should actually be considered as two separate ideas: first, that the intelligence of such agents can be measured based on the growth rates of the runtimes of the competitors that they defeat; and second, one specific (somewhat arbitrary) method for measuring said growth rates. Whereas Hibbard's intelligence measure is based on the latter growth-rate-measuring method, we survey other methods for measuring function growth rates, and exhibit the resulting Hibbard-like intelligence measures and taxonomies. Of particular interest, we obtain intelligence taxonomies based on Big-O and Big-Theta notation systems, which taxonomies are novel in that they challenge conventional notions of what an intelligence measure should look like. We discuss how intelligence measurement of sequence predictors can indirectly serve as intelligence measurement for agents with Artificial General Intelligence (AGIs).
* 25 pages