 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Free Attacks in Multi-Agent Reinforcement Learning
Dec 02, 2021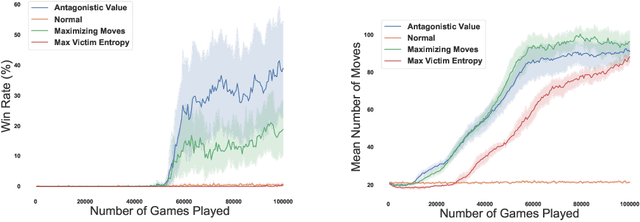

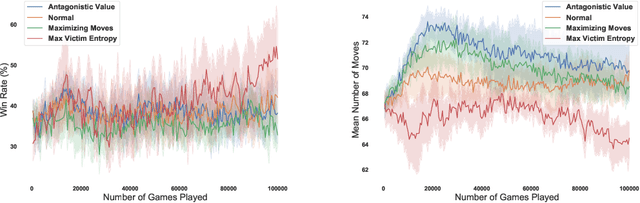

We investigate how effective an attacker can be when it only learns from its victim's actions, without access to the victim's reward. In this work, we are motivated by the scenario where the attacker wants to behave strategically when the victim's motivations are unknown. We argue that one heuristic approach an attacker can use is to maximize the entropy of the victim's policy. The policy is generally not obfuscated, which implies it may be extracted simply by passively observing the victim. We provide such a strategy in the form of a reward-free exploration algorithm that maximizes the attacker's entropy during the exploration phase, and then maximizes the victim's empirical entropy during the planning phase. In our experiments, the victim agents are subverted through policy entropy maximization, implying an attacker might not need access to the victim's reward to succeed. Hence, reward-free attacks, which are based only on observing behavior, show the feasibility of an attacker to act strategically without knowledge of the victim's motives even if the victim's reward information is protected.
Prototypical Region Proposal Networks for Few-Shot Localization and Classification
Apr 08, 2021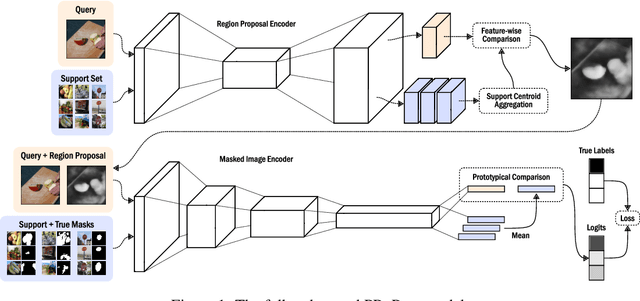
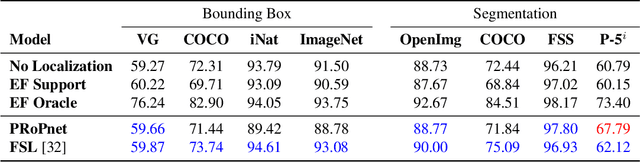
Recently proposed few-shot image classification methods have generally focused on use cases where the objects to be classified are the central subject of images. Despite success on benchmark vision datasets aligned with this use case, these methods typically fail on use cases involving densely-annotated, busy images: images common in the wild where objects of relevance are not the central subject, instead appearing potentially occluded, small, or among other incidental objects belonging to other classes of potential interest. To localize relevant objects, we employ a prototype-based few-shot segmentation model which compares the encoded features of unlabeled query images with support class centroids to produce region proposals indicating the presence and location of support set classes in a query image. These region proposals are then used as additional conditioning input to few-shot image classifiers. We develop a framework to unify the two stages (segmentation and classification) into an end-to-end classification model -- PRoPnet -- and empirically demonstrate that our methods improve accuracy on image datasets with natural scenes containing multiple object classes.
Explanatory Masks for Neural Network Interpretability
Nov 15, 2019
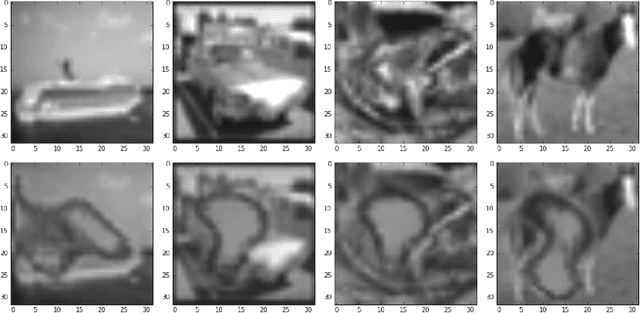


Neural network interpretability is a vital component for applications across a wide variety of domains. In such cases it is often useful to analyze a network which has already been trained for its specific purpose. In this work, we develop a method to produce explanation masks for pre-trained networks. The mask localizes the most important aspects of each input for prediction of the original network. Masks are created by a secondary network whose goal is to create as small an explanation as possible while still preserving the predictive accuracy of the original network. We demonstrate the applicability of our method for image classification with CNNs, sentiment analysis with RNNs, and chemical property prediction with mixed CNN/RNN architectures.
Metric-Based Few-Shot Learning for Video Action Recognition
Sep 14, 2019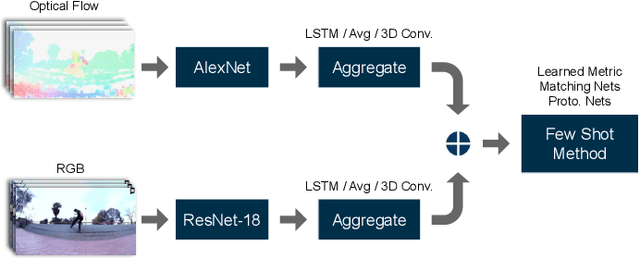
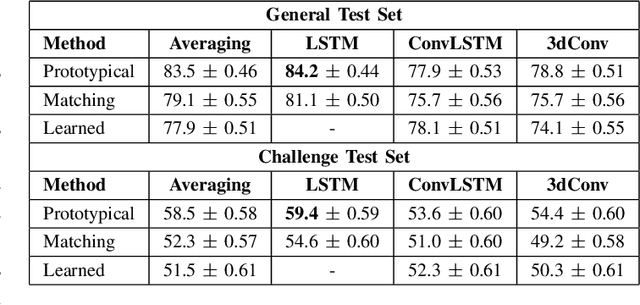
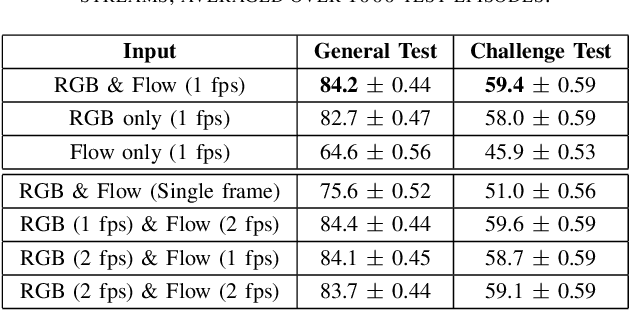
In the few-shot scenario, a learner must effectively generalize to unseen classes given a small support set of labeled examples. While a relatively large amount of research has gone into few-shot learning for image classification, little work has been done on few-shot video classification. In this work, we address the task of few-shot video action recognition with a set of two-stream models. We evaluate the performance of a set of convolutional and recurrent neural network video encoder architectures used in conjunction with three popular metric-based few-shot algorithms. We train and evaluate using a few-shot split of the Kinetics 600 dataset. Our experiments confirm the importance of the two-stream setup, and find prototypical networks and pooled long short-term memory network embeddings to give the best performance as few-shot method and video encoder, respectively. For a 5-shot 5-way task, this setup obtains 84.2% accuracy on the test set and 59.4% on a special "challenge" test set, composed of highly confusable classes.
Learning Deep Neural Network Representations for Koopman Operators of Nonlinear Dynamical Systems
Nov 17, 2017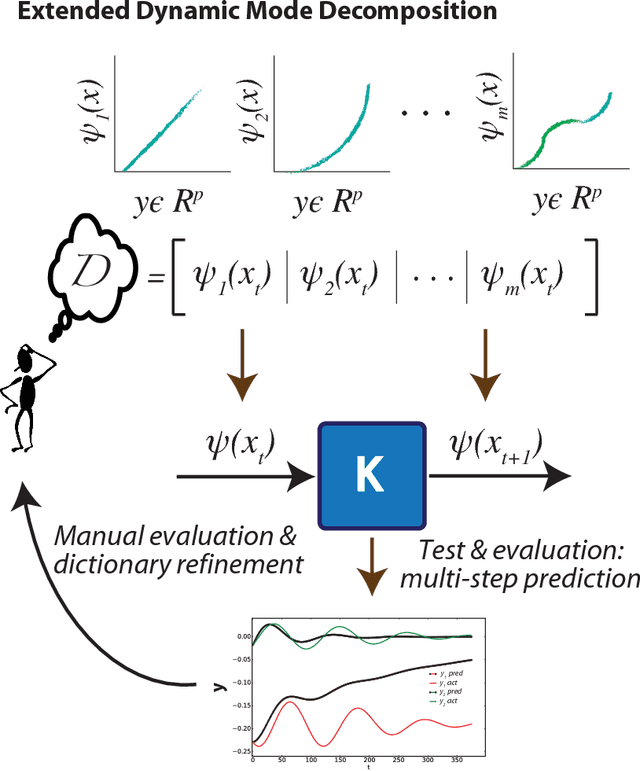
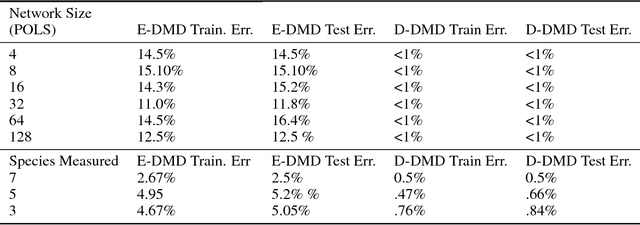
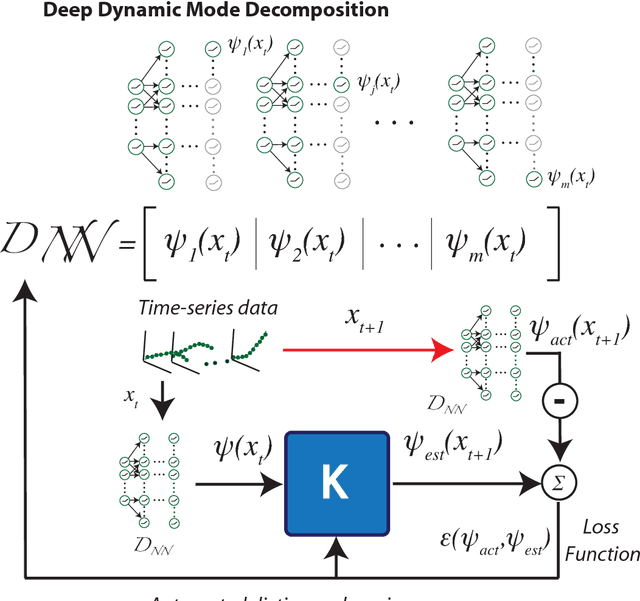
The Koopman operator has recently garnered much attention for its value in dynamical systems analysis and data-driven model discovery. However, its application has been hindered by the computational complexity of extended dynamic mode decomposition; this requires a combinatorially large basis set to adequately describe many nonlinear systems of interest, e.g. cyber-physical infrastructure systems, biological networks, social systems, and fluid dynamics. Often the dictionaries generated for these problems are manually curated, requiring domain-specific knowledge and painstaking tuning. In this paper we introduce a deep learning framework for learning Koopman operators of nonlinear dynamical systems. We show that this novel method automatically selects efficient deep dictionaries, outperforming state-of-the-art methods. We benchmark this method on partially observed nonlinear systems, including the glycolytic oscillator and show it is able to predict quantitatively 100 steps into the future, using only a single timepoint, and qualitative oscillatory behavior 400 steps into the future.
Assessing the Linguistic Productivity of Unsupervised Deep Neural Networks
Jun 06, 2017
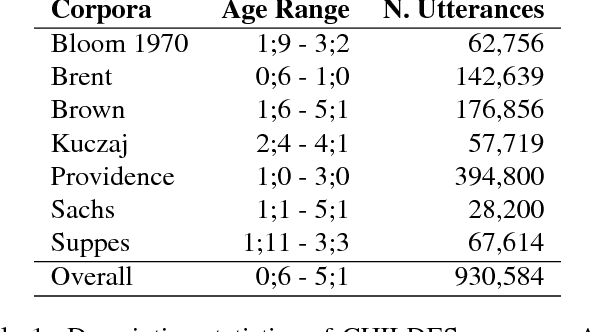
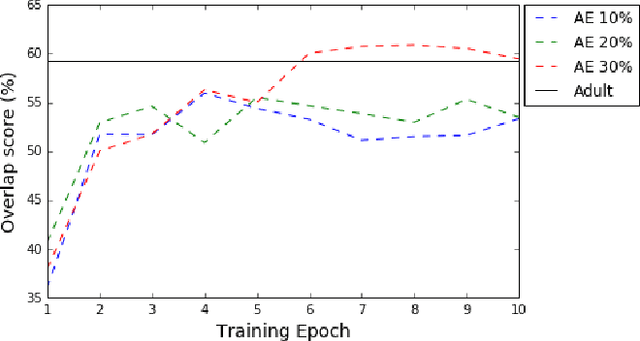
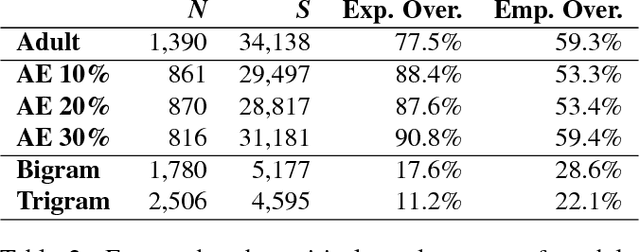
Increasingly, cognitive scientists have demonstrated interest in applying tools from deep learning. One use for deep learning is in language acquisition where it is useful to know if a linguistic phenomenon can be learned through domain-general means. To assess whether unsupervised deep learning is appropriate, we first pose a smaller question: Can unsupervised neural networks apply linguistic rules productively, using them in novel situations? We draw from the literature on determiner/noun productivity by training an unsupervised, autoencoder network measuring its ability to combine nouns with determiners. Our simple autoencoder creates combinations it has not previously encountered and produces a degree of overlap matching adults. While this preliminary work does not provide conclusive evidence for productivity, it warrants further investigation with more complex models. Further, this work helps lay the foundations for future collaboration between the deep learning and cognitive science communities.