 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Transfer Learning: a simple but effective transfer learning
Nov 22, 2021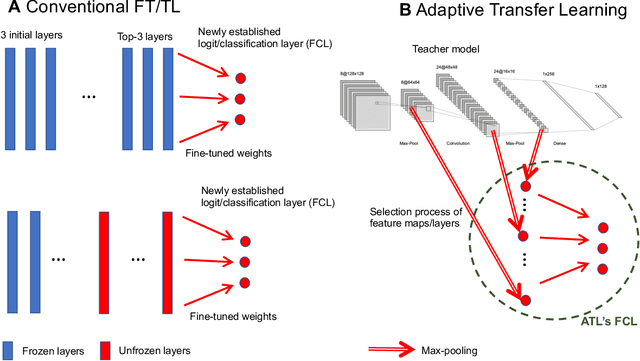
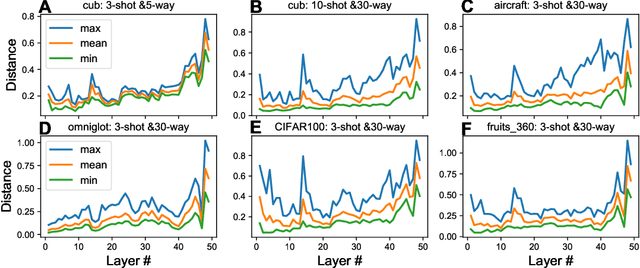
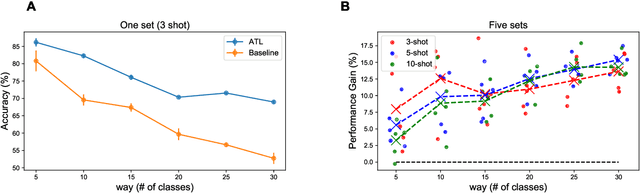
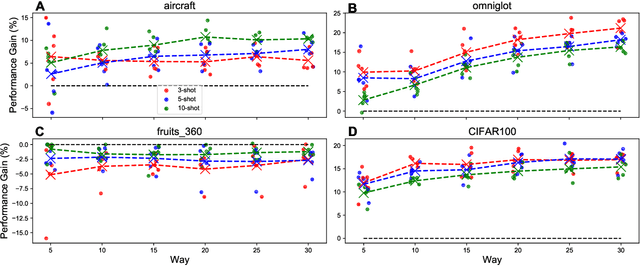
Transfer learning (TL) leverages previously obtained knowledge to learn new tasks efficiently and has been used to train deep learning (DL) models with limited amount of data. When TL is applied to DL, pretrained (teacher) models are fine-tuned to build domain specific (student) models. This fine-tuning relies on the fact that DL model can be decomposed to classifiers and feature extractors, and a line of studies showed that the same feature extractors can be used to train classifiers on multiple tasks. Furthermore, recent studies proposed multiple algorithms that can fine-tune teacher models' feature extractors to train student models more efficiently. We note that regardless of the fine-tuning of feature extractors, the classifiers of student models are trained with final outputs of feature extractors (i.e., the outputs of penultimate layers). However, a recent study suggested that feature maps in ResNets across layers could be functionally equivalent, raising the possibility that feature maps inside the feature extractors can also be used to train student models' classifiers. Inspired by this study, we tested if feature maps in the hidden layers of the teacher models can be used to improve the student models' accuracy (i.e., TL's efficiency). Specifically, we developed 'adaptive transfer learning (ATL)', which can choose an optimal set of feature maps for TL, and tested it in the few-shot learning setting. Our empirical evaluations suggest that ATL can help DL models learn more efficiently, especially when available examples are limited.
One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations
Jun 02, 2021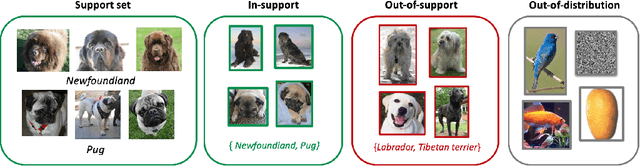
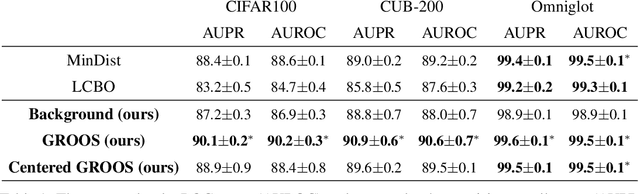
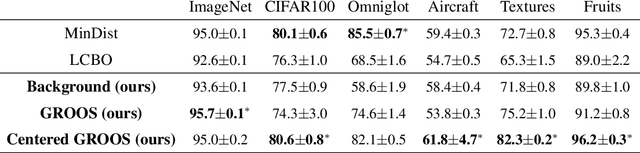
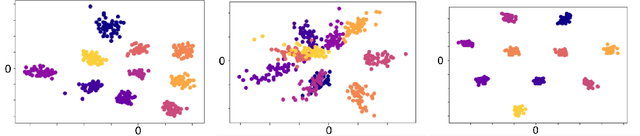
The field of few-shot learning has made remarkable strides in developing powerful models that can operate in the small data regime. Nearly all of these methods assume every unlabeled instance encountered will belong to a handful of known classes for which one has examples. This can be problematic for real-world use cases where one routinely finds 'none-of-the-above' examples. In this paper we describe this challenge of identifying what we term 'out-of-support' (OOS) examples. We describe how this problem is subtly different from out-of-distribution detection and describe a new method of identifying OOS examples within the Prototypical Networks framework using a fixed point which we call the generic representation. We show that our method outperforms other existing approaches in the literature as well as other approaches that we propose in this paper. Finally, we investigate how the use of such a generic point affects the geometry of a model's feature space.
Prototypical Region Proposal Networks for Few-Shot Localization and Classification
Apr 08, 2021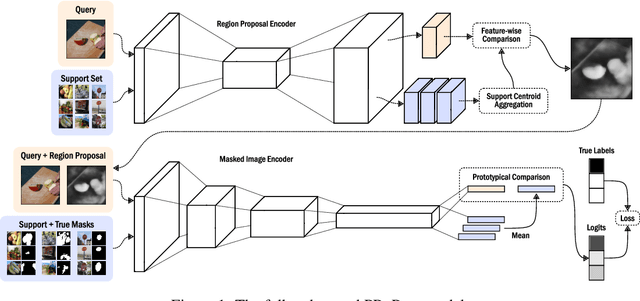
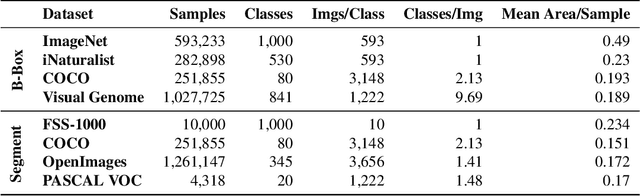
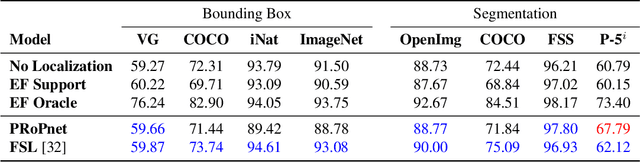
Recently proposed few-shot image classification methods have generally focused on use cases where the objects to be classified are the central subject of images. Despite success on benchmark vision datasets aligned with this use case, these methods typically fail on use cases involving densely-annotated, busy images: images common in the wild where objects of relevance are not the central subject, instead appearing potentially occluded, small, or among other incidental objects belonging to other classes of potential interest. To localize relevant objects, we employ a prototype-based few-shot segmentation model which compares the encoded features of unlabeled query images with support class centroids to produce region proposals indicating the presence and location of support set classes in a query image. These region proposals are then used as additional conditioning input to few-shot image classifiers. We develop a framework to unify the two stages (segmentation and classification) into an end-to-end classification model -- PRoPnet -- and empirically demonstrate that our methods improve accuracy on image datasets with natural scenes containing multiple object classes.
Fuzzy Simplicial Networks: A Topology-Inspired Model to Improve Task Generalization in Few-shot Learning
Sep 23, 2020


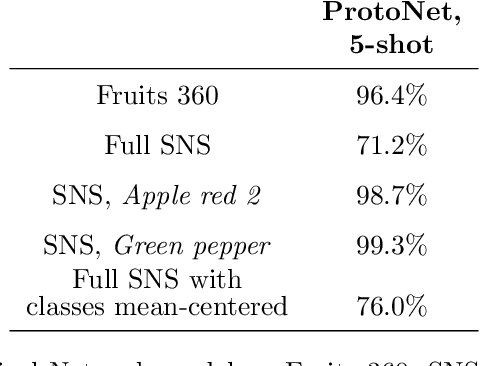
Deep learning has shown great success in settings with massive amounts of data but has struggled when data is limited. Few-shot learning algorithms, which seek to address this limitation, are designed to generalize well to new tasks with limited data. Typically, models are evaluated on unseen classes and datasets that are defined by the same fundamental task as they are trained for (e.g. category membership). One can also ask how well a model can generalize to fundamentally different tasks within a fixed dataset (for example: moving from category membership to tasks that involve detecting object orientation or quantity). To formalize this kind of shift we define a notion of "independence of tasks" and identify three new sets of labels for established computer vision datasets that test a model's ability to generalize to tasks which draw on orthogonal attributes in the data. We use these datasets to investigate the failure modes of metric-based few-shot models. Based on our findings, we introduce a new few-shot model called Fuzzy Simplicial Networks (FSN) which leverages a construction from topology to more flexibly represent each class from limited data. In particular, FSN models can not only form multiple representations for a given class but can also begin to capture the low-dimensional structure which characterizes class manifolds in the encoded space of deep networks. We show that FSN outperforms state-of-the-art models on the challenging tasks we introduce in this paper while remaining competitive on standard few-shot benchmarks.
Few-Shot Learning with Metric-Agnostic Conditional Embeddings
Feb 12, 2018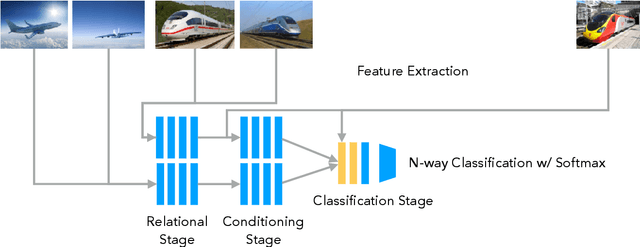
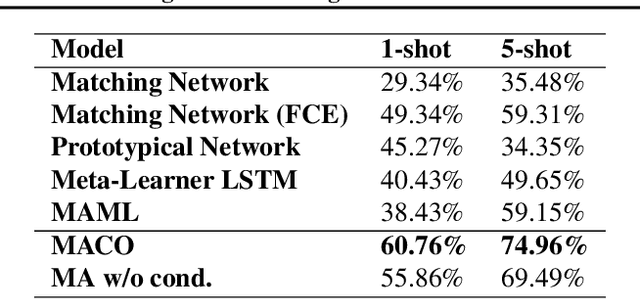
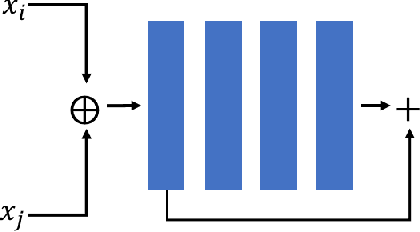
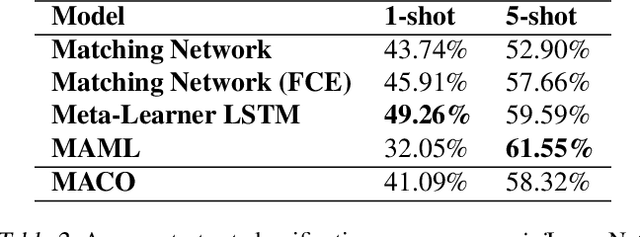
Learning high quality class representations from few examples is a key problem in metric-learning approaches to few-shot learning. To accomplish this, we introduce a novel architecture where class representations are conditioned for each few-shot trial based on a target image. We also deviate from traditional metric-learning approaches by training a network to perform comparisons between classes rather than relying on a static metric comparison. This allows the network to decide what aspects of each class are important for the comparison at hand. We find that this flexible architecture works well in practice, achieving state-of-the-art performance on the Caltech-UCSD birds fine-grained classification task.
Dynamic Input Structure and Network Assembly for Few-Shot Learning
Aug 22, 2017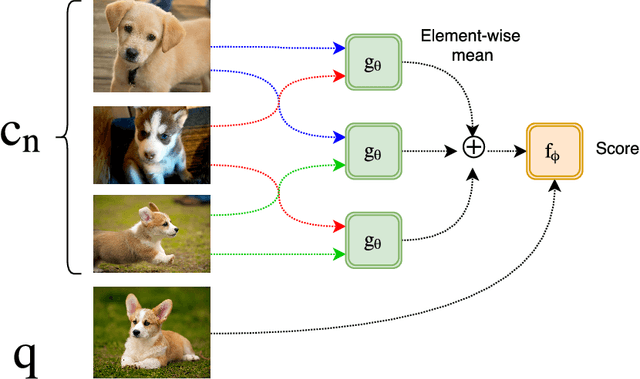
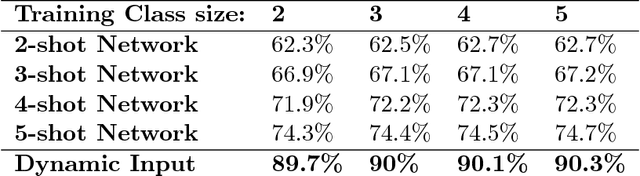
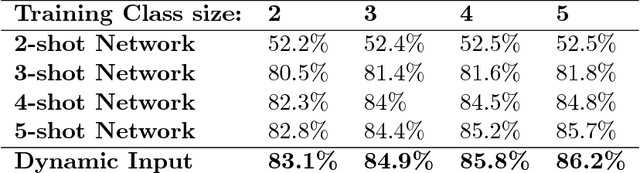
The ability to learn from a small number of examples has been a difficult problem in machine learning since its inception. While methods have succeeded with large amounts of training data, research has been underway in how to accomplish similar performance with fewer examples, known as one-shot or more generally few-shot learning. This technique has been shown to have promising performance, but in practice requires fixed-size inputs making it impractical for production systems where class sizes can vary. This impedes training and the final utility of few-shot learning systems. This paper describes an approach to constructing and training a network that can handle arbitrary example sizes dynamically as the system is used.