 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes My Embedding Reflect That $A = B$? Evaluating Mathematical Equivalence in Embedding Models
Jun 22, 2026Because mathematics is highly abstract, a single statement can take very different forms depending on what subfield it is framed in. There are many examples where breakthroughs occurred after researchers discovered that a question had already been answered in a different field. At the same time, the growth of new resources related to formalization has increased the need for tools that enable efficient and reliable navigation between mathematical 'languages' (e.g., from Lean to natural language). In this paper, we investigate whether current embedding models capture mathematical equivalence. To do this, we introduce the Mathematically Equivalent but Lexically Different Pairs (MELD) Dataset, a collection of mathematically equivalent statements that are expressed in very different language. We show that current state-of-the-art embedding models tend to group statements by the terminology used to make them instead of the underlying math. Motivated by this, we propose a contrastive approach to learning embeddings of mathematical text that focuses on aligning informal statements with different formalizations. Our experiments demonstrate that this leads to improvements not only on informal-formal retrieval tasks but also on MELD, which only contains natural language statements.
MINAR: Mechanistic Interpretability for Neural Algorithmic Reasoning
Feb 24, 2026The recent field of neural algorithmic reasoning (NAR) studies the ability of graph neural networks (GNNs) to emulate classical algorithms like Bellman-Ford, a phenomenon known as algorithmic alignment. At the same time, recent advances in large language models (LLMs) have spawned the study of mechanistic interpretability, which aims to identify granular model components like circuits that perform specific computations. In this work, we introduce Mechanistic Interpretability for Neural Algorithmic Reasoning (MINAR), an efficient circuit discovery toolbox that adapts attribution patching methods from mechanistic interpretability to the GNN setting. We show through two case studies that MINAR recovers faithful neuron-level circuits from GNNs trained on algorithmic tasks. Our study sheds new light on the process of circuit formation and pruning during training, as well as giving new insight into how GNNs trained to perform multiple tasks in parallel reuse circuit components for related tasks. Our code is available at https://github.com/pnnl/MINAR.
What do Geometric Hallucination Detection Metrics Actually Measure?
Feb 09, 2026Hallucination remains a barrier to deploying generative models in high-consequence applications. This is especially true in cases where external ground truth is not readily available to validate model outputs. This situation has motivated the study of geometric signals in the internal state of an LLM that are predictive of hallucination and require limited external knowledge. Given that there are a range of factors that can lead model output to be called a hallucination (e.g., irrelevance vs incoherence), in this paper we ask what specific properties of a hallucination these geometric statistics actually capture. To assess this, we generate a synthetic dataset which varies distinct properties of output associated with hallucination. This includes output correctness, confidence, relevance, coherence, and completeness. We find that different geometric statistics capture different types of hallucinations. Along the way we show that many existing geometric detection methods have substantial sensitivity to shifts in task domain (e.g., math questions vs. history questions). Motivated by this, we introduce a simple normalization method to mitigate the effect of domain shift on geometric statistics, leading to AUROC gains of +34 points in multi-domain settings.
Can Neural Networks Learn Small Algebraic Worlds? An Investigation Into the Group-theoretic Structures Learned By Narrow Models Trained To Predict Group Operations
Jan 29, 2026While a real-world research program in mathematics may be guided by a motivating question, the process of mathematical discovery is typically open-ended. Ideally, exploration needed to answer the original question will reveal new structures, patterns, and insights that are valuable in their own right. This contrasts with the exam-style paradigm in which the machine learning community typically applies AI to math. To maximize progress in mathematics using AI, we will need to go beyond simple question answering. With this in mind, we explore the extent to which narrow models trained to solve a fixed mathematical task learn broader mathematical structure that can be extracted by a researcher or other AI system. As a basic test case for this, we use the task of training a neural network to predict a group operation (for example, performing modular arithmetic or composition of permutations). We describe a suite of tests designed to assess whether the model captures significant group-theoretic notions such as the identity element, commutativity, or subgroups. Through extensive experimentation we find evidence that models learn representations capable of capturing abstract algebraic properties. For example, we find hints that models capture the commutativity of modular arithmetic. We are also able to train linear classifiers that reliably distinguish between elements of certain subgroups (even though no labels for these subgroups are included in the data). On the other hand, we are unable to extract notions such as the concept of the identity element. Together, our results suggest that in some cases the representations of even small neural networks can be used to distill interesting abstract structure from new mathematical objects.
FMG-Det: Foundation Model Guided Robust Object Detection
May 29, 2025

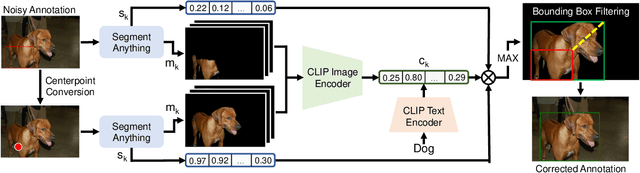

Collecting high quality data for object detection tasks is challenging due to the inherent subjectivity in labeling the boundaries of an object. This makes it difficult to not only collect consistent annotations across a dataset but also to validate them, as no two annotators are likely to label the same object using the exact same coordinates. These challenges are further compounded when object boundaries are partially visible or blurred, which can be the case in many domains. Training on noisy annotations significantly degrades detector performance, rendering them unusable, particularly in few-shot settings, where just a few corrupted annotations can impact model performance. In this work, we propose FMG-Det, a simple, efficient methodology for training models with noisy annotations. More specifically, we propose combining a multiple instance learning (MIL) framework with a pre-processing pipeline that leverages powerful foundation models to correct labels prior to training. This pre-processing pipeline, along with slight modifications to the detector head, results in state-of-the-art performance across a number of datasets, for both standard and few-shot scenarios, while being much simpler and more efficient than other approaches.
Foundation Models for Remote Sensing: An Analysis of MLLMs for Object Localization
Apr 14, 2025


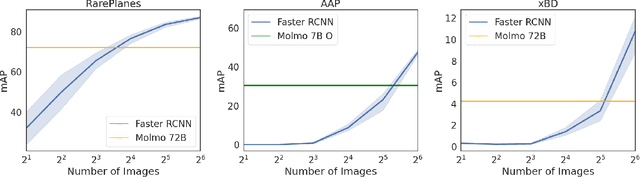
Multimodal large language models (MLLMs) have altered the landscape of computer vision, obtaining impressive results across a wide range of tasks, especially in zero-shot settings. Unfortunately, their strong performance does not always transfer to out-of-distribution domains, such as earth observation (EO) imagery. Prior work has demonstrated that MLLMs excel at some EO tasks, such as image captioning and scene understanding, while failing at tasks that require more fine-grained spatial reasoning, such as object localization. However, MLLMs are advancing rapidly and insights quickly become out-dated. In this work, we analyze more recent MLLMs that have been explicitly trained to include fine-grained spatial reasoning capabilities, benchmarking them on EO object localization tasks. We demonstrate that these models are performant in certain settings, making them well suited for zero-shot scenarios. Additionally, we provide a detailed discussion focused on prompt selection, ground sample distance (GSD) optimization, and analyzing failure cases. We hope that this work will prove valuable as others evaluate whether an MLLM is well suited for a given EO localization task and how to optimize it.
Machine Learning meets Algebraic Combinatorics: A Suite of Datasets Capturing Research-level Conjecturing Ability in Pure Mathematics
Mar 09, 2025



With recent dramatic increases in AI system capabilities, there has been growing interest in utilizing machine learning for reasoning-heavy, quantitative tasks, particularly mathematics. While there are many resources capturing mathematics at the high-school, undergraduate, and graduate level, there are far fewer resources available that align with the level of difficulty and open endedness encountered by professional mathematicians working on open problems. To address this, we introduce a new collection of datasets, the Algebraic Combinatorics Dataset Repository (ACD Repo), representing either foundational results or open problems in algebraic combinatorics, a subfield of mathematics that studies discrete structures arising from abstract algebra. Further differentiating our dataset collection is the fact that it aims at the conjecturing process. Each dataset includes an open-ended research-level question and a large collection of examples (up to 10M in some cases) from which conjectures should be generated. We describe all nine datasets, the different ways machine learning models can be applied to them (e.g., training with narrow models followed by interpretability analysis or program synthesis with LLMs), and discuss some of the challenges involved in designing datasets like these.
Machines and Mathematical Mutations: Using GNNs to Characterize Quiver Mutation Classes
Nov 12, 2024



Machine learning is becoming an increasingly valuable tool in mathematics, enabling one to identify subtle patterns across collections of examples so vast that they would be impossible for a single researcher to feasibly review and analyze. In this work, we use graph neural networks to investigate quiver mutation -- an operation that transforms one quiver (or directed multigraph) into another -- which is central to the theory of cluster algebras with deep connections to geometry, topology, and physics. In the study of cluster algebras, the question of mutation equivalence is of fundamental concern: given two quivers, can one efficiently determine if one quiver can be transformed into the other through a sequence of mutations? Currently, this question has only been resolved in specific cases. In this paper, we use graph neural networks and AI explainability techniques to discover mutation equivalence criteria for the previously unknown case of quivers of type $\tilde{D}_n$. Along the way, we also show that even without explicit training to do so, our model captures structure within its hidden representation that allows us to reconstruct known criteria from type $D_n$, adding to the growing evidence that modern machine learning models are capable of learning abstract and general rules from mathematical data.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024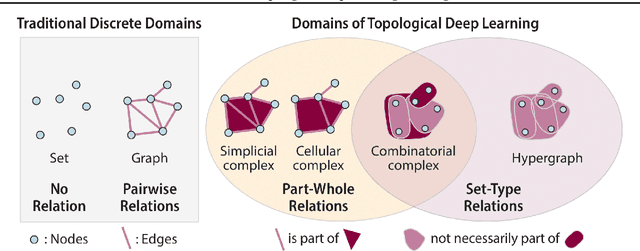
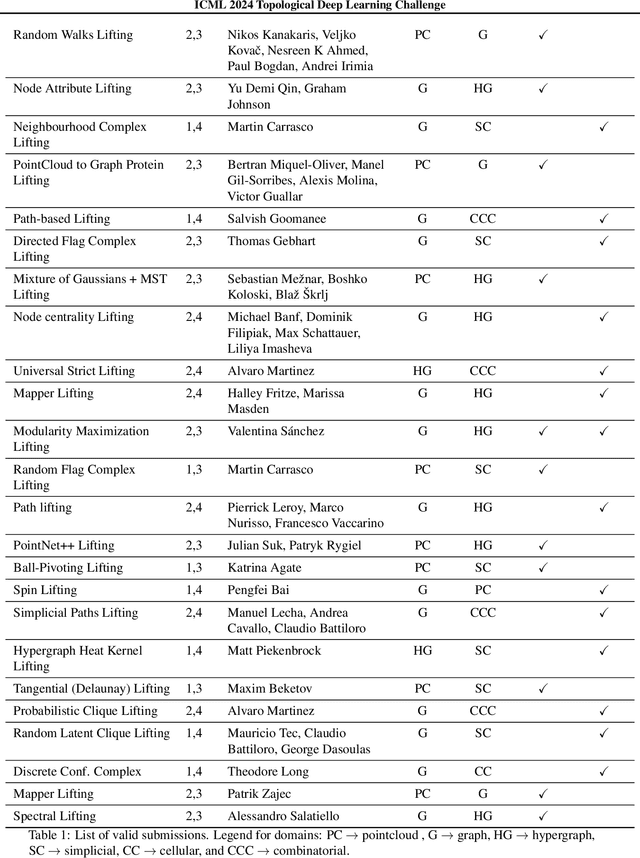
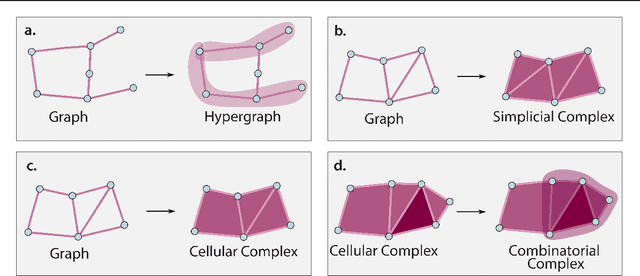
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Model editing for distribution shifts in uranium oxide morphological analysis
Jul 22, 2024

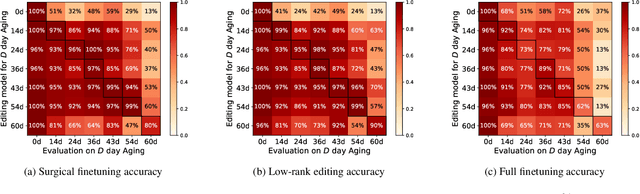
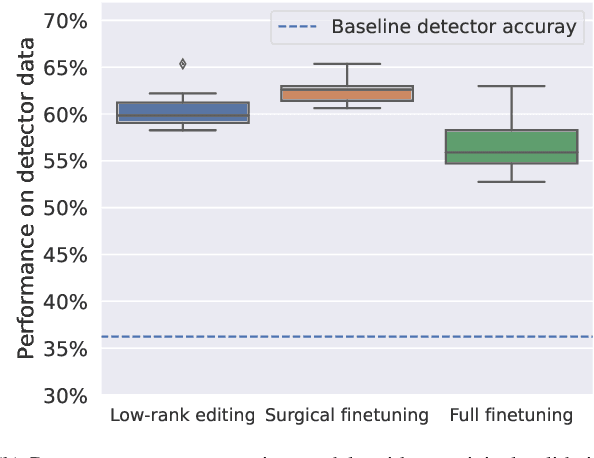
Deep learning still struggles with certain kinds of scientific data. Notably, pretraining data may not provide coverage of relevant distribution shifts (e.g., shifts induced via the use of different measurement instruments). We consider deep learning models trained to classify the synthesis conditions of uranium ore concentrates (UOCs) and show that model editing is particularly effective for improving generalization to distribution shifts common in this domain. In particular, model editing outperforms finetuning on two curated datasets comprising of micrographs taken of U$_{3}$O$_{8}$ aged in humidity chambers and micrographs acquired with different scanning electron microscopes, respectively.